

cJONS序列化工具解读二(数据解析)
cJSON数据解析
关于数据解析部分,其实这个解析就是个自动机,通过递归或者解析栈进行实现数据的解析
/* Utility to jump whitespace and cr/lf */
//用于跳过ascii小于32的空白字符 static const char *skip(const char *in) { while (in && *in && (unsigned char)*in <= 32) in++; return in; } /* Parse an object - create a new root, and populate. */ cJSON *cJSON_ParseWithOpts(const char *value, const char **return_parse_end, int require_null_terminated) { const char *end = 0; cJSON *c = cJSON_New_Item(); ep = 0; if (!c) return 0; /* memory fail */ //根据前几个字符设置c类型并更新读取位置为end end = parse_value(c, skip(value)); if (!end) { cJSON_Delete(c); //解析失败,数据不完整 return 0; } /* parse failure. ep is set. */ /* if we require null-terminated JSON without appended garbage, skip and then check for a null terminator */ if (require_null_terminated)///?? { end = skip(end); if (*end) { cJSON_Delete(c); ep = end; return 0; } } if (return_parse_end) *return_parse_end = end; return c; } /* Default options for cJSON_Parse */ cJSON *cJSON_Parse(const char *value) { return cJSON_ParseWithOpts(value, 0, 0); }
①关于重点部分parse_value 对类型解读函数
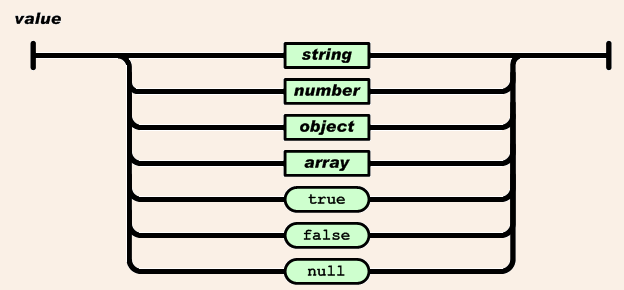
/* Parser core - when encountering text, process appropriately. */
//将输入字符串解析为具体类型cJSON结构 static const char *parse_value(cJSON *item, const char *value) { if (!value) return 0; /* Fail on null. */
//设置结构的具体类型并且返回下一个将要解读数据的位置 if (!strncmp(value, "null", 4)) { item->type = cJSON_NULL; return value + 4; } if (!strncmp(value, "false", 5)) { item->type = cJSON_False; return value + 5; } if (!strncmp(value, "true", 4)) { item->type = cJSON_True; item->valueint = 1; return value + 4; } if (*value == '\"') { return parse_string(item, value); } if (*value == '-' || (*value >= '0' && *value <= '9')) { return parse_number(item, value); } if (*value == '[') { return parse_array(item, value); } if (*value == '{') { return parse_object(item, value); } ep = value; return 0; /* failure. */ }
②解析字符串部分
解析字符串时, 对于特殊字符也应该转义,比如 "n" 字符应该转换为 'n' 这个换行符。
当然,如果只有特殊字符转换的话,代码不会又这么长, 对于字符串, 还要支持非 ascii 码的字符, 即 utf8字符。
这些字符在字符串中会编码为 uXXXX 的字符串, 我们现在需要还原为 0 - 255 的一个字符。
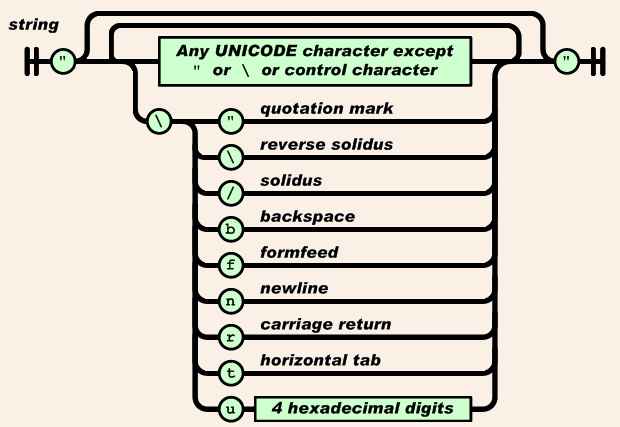
static unsigned parse_hex4(const char *str) { unsigned h = 0; if (*str >= '0' && *str <= '9') h += (*str) - '0'; else if (*str >= 'A' && *str <= 'F') h += 10 + (*str) - 'A'; else if (*str >= 'a' && *str <= 'f') h += 10 + (*str) - 'a'; else return 0; h = h << 4; //*F str++; if (*str >= '0' && *str <= '9') h += (*str) - '0'; else if (*str >= 'A' && *str <= 'F') h += 10 + (*str) - 'A'; else if (*str >= 'a' && *str <= 'f') h += 10 + (*str) - 'a'; else return 0; h = h << 4; str++; if (*str >= '0' && *str <= '9') h += (*str) - '0'; else if (*str >= 'A' && *str <= 'F') h += 10 + (*str) - 'A'; else if (*str >= 'a' && *str <= 'f') h += 10 + (*str) - 'a'; else return 0; h = h << 4; str++; if (*str >= '0' && *str <= '9') h += (*str) - '0'; else if (*str >= 'A' && *str <= 'F') h += 10 + (*str) - 'A'; else if (*str >= 'a' && *str <= 'f') h += 10 + (*str) - 'a'; else return 0; return h; } /* Parse the input text into an unescaped cstring, and populate item. */ static const unsigned char firstByteMark[7] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC }; static const char *parse_string(cJSON *item, const char *str) { const char *ptr = str + 1; char *ptr2; char *out; int len = 0; unsigned uc, uc2; if (*str != '\"') { ep = str; return 0; } /* not a string! */ while(*ptr != '\"' && *ptr && ++len) if (*ptr++ == '\\') //跳过\续行符 ptr++; /* Skip escaped quotes. */ //空间申请 out = (char*)cJSON_malloc(len + 1); /* This is how long we need for the string, roughly. */ if (!out) return 0; ptr = str + 1;//跳过“开始 ptr2 = out; while (*ptr != '\"' && *ptr) { if (*ptr != '\\') *ptr2++ = *ptr++; else //转义字符处理 { ptr++; switch (*ptr) { case 'b': *ptr2++ = '\b'; break; case 'f': *ptr2++ = '\f'; break; case 'n': *ptr2++ = '\n'; break; case 'r': *ptr2++ = '\r'; break; case 't': *ptr2++ = '\t'; break; case 'u': /* transcode utf16 to utf8. */ uc = parse_hex4(ptr + 1); ptr += 4; /* get the unicode char. */ if ((uc >= 0xDC00 && uc <= 0xDFFF) || uc == 0) break; /* check for invalid. */ if (uc >= 0xD800 && uc <= 0xDBFF) /* UTF16 surrogate pairs. */ { if (ptr[1] != '\\' || ptr[2] != 'u') break; /* missing second-half of surrogate. */ uc2 = parse_hex4(ptr + 3); ptr += 6; if (uc2<0xDC00 || uc2>0xDFFF) break; /* invalid second-half of surrogate. */ uc = 0x10000 + (((uc & 0x3FF) << 10) | (uc2 & 0x3FF)); } len = 4; if (uc<0x80) len = 1; else if (uc<0x800) len = 2; else if (uc<0x10000) len = 3; ptr2 += len; switch (len) { case 4: *--ptr2 = ((uc | 0x80) & 0xBF); uc >>= 6; case 3: *--ptr2 = ((uc | 0x80) & 0xBF); uc >>= 6; case 2: *--ptr2 = ((uc | 0x80) & 0xBF); uc >>= 6; case 1: *--ptr2 = (uc | firstByteMark[len]); } ptr2 += len; break; default: *ptr2++ = *ptr; break; } ptr++; } } *ptr2 = 0; if (*ptr == '\"') ptr++; item->valuestring = out; item->type = cJSON_String; return ptr; }
关于具体的字符解析中的编码相关问题,请自行阅读编码相关知识
③数字解析
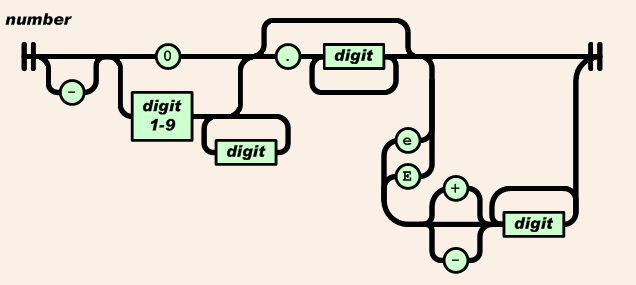
/* Parse the input text to generate a number, and populate the result into item. */ static const char *parse_number(cJSON *item, const char *num) { double n = 0, sign = 1, scale = 0; int subscale = 0, signsubscale = 1; if (*num == '-') sign = -1, num++; /* Has sign? */ if (*num == '0') num++; /* is zero */ if (*num >= '1' && *num <= '9') do { n = (n*10.0) + (*num++ - '0'); }while (*num >= '0' && *num <= '9'); /* Number? */ if (*num == '.' && num[1] >= '0' && num[1] <= '9') { num++; do n = (n*10.0) + (*num++ - '0'), scale--; while (*num >= '0' && *num <= '9'); } /* Fractional part? */ if (*num == 'e' || *num == 'E') /* Exponent? */ { num++; if (*num == '+') num++; else if (*num == '-') signsubscale = -1, num++; /* With sign? */ while (*num >= '0' && *num <= '9') subscale = (subscale * 10) + (*num++ - '0'); /* Number? */ } n = sign*n*pow(10.0, (scale + subscale*signsubscale)); /* number = +/- number.fraction * 10^+/- exponent */ item->valuedouble = n; item->valueint = (int)n; item->type = cJSON_Number; return num; }
④解析数组
解析数组, 需要先遇到 '[' 这个符号, 然后挨个的读取节点内容, 节点使用 ',' 分隔, ',' 前后还可能有空格, 最后以 ']' 结尾。
我们要编写的也是这样。
先创建一个数组对象, 判断是否有儿子, 有的话读取第一个儿子, 然后判断是不是有 逗号, 有的话循环读取后面的儿子。
最后读取 ']' 即可。
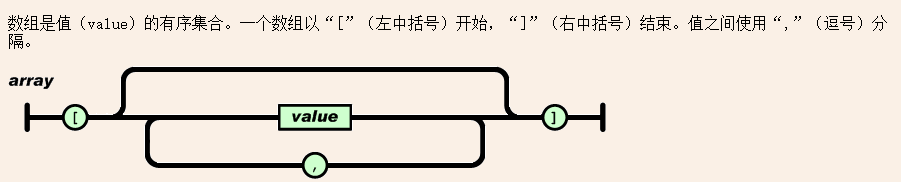
/* Build an array from input text. */ static const char *parse_array(cJSON *item, const char *value) { cJSON *child; if (*value != '[') { ep = value; return 0; } /* not an array! */ item->type = cJSON_Array; value = skip(value + 1); if (*value == ']') return value + 1; /* empty array. */ item->child = child = cJSON_New_Item(); if (!item->child) return 0; /* memory fail */ //解析数组内结构 value = skip(parse_value(child, skip(value))); /* skip any spacing, get the value. */ if (!value) return 0; while (*value == ',') { cJSON *new_item; if (!(new_item = cJSON_New_Item())) return 0; /* memory fail */ child->next = new_item; new_item->prev = child; child = new_item; value = skip(parse_value(child, skip(value + 1))); if (!value) return 0; /* memory fail */ } if (*value == ']') return value + 1; /* end of array */ ep = value; return 0; /* malformed. */ }
⑤解析对象
解析对象和解析数组类似, 只不过对象的一个儿子是个 key - value, key 是字符串, value 可能是任何值, key 和 value 用 ":" 分隔。

/* Render an object to text. */ static char *print_object(cJSON *item, int depth, int fmt, printbuffer *p) { char **entries = 0, **names = 0; char *out = 0, *ptr, *ret, *str; int len = 7, i = 0, j; cJSON *child = item->child; int numentries = 0, fail = 0; size_t tmplen = 0; /* Count the number of entries. */ while (child) numentries++, child = child->next; /* Explicitly handle empty object case */ if (!numentries) { if (p) out = ensure(p, fmt ? depth + 4 : 3); else out = (char*)cJSON_malloc(fmt ? depth + 4 : 3); if (!out) return 0; ptr = out; *ptr++ = '{'; if (fmt) { *ptr++ = '\n'; for (i = 0; i<depth - 1; i++) *ptr++ = '\t'; } *ptr++ = '}'; *ptr++ = 0; return out; } if (p) { /* Compose the output: */ i = p->offset; len = fmt ? 2 : 1; ptr = ensure(p, len + 1); if (!ptr) return 0; *ptr++ = '{'; if (fmt) *ptr++ = '\n'; *ptr = 0; p->offset += len; child = item->child; depth++; while (child) { if (fmt) { ptr = ensure(p, depth); if (!ptr) return 0; for (j = 0; j<depth; j++) *ptr++ = '\t'; p->offset += depth; } print_string_ptr(child->string, p); p->offset = update(p); len = fmt ? 2 : 1; ptr = ensure(p, len); if (!ptr) return 0; *ptr++ = ':'; if (fmt) *ptr++ = '\t'; p->offset += len; print_value(child, depth, fmt, p); p->offset = update(p); len = (fmt ? 1 : 0) + (child->next ? 1 : 0); ptr = ensure(p, len + 1); if (!ptr) return 0; if (child->next) *ptr++ = ','; if (fmt) *ptr++ = '\n'; *ptr = 0; p->offset += len; child = child->next; } ptr = ensure(p, fmt ? (depth + 1) : 2); if (!ptr) return 0; if (fmt) for (i = 0; i<depth - 1; i++) *ptr++ = '\t'; *ptr++ = '}'; *ptr = 0; out = (p->buffer) + i; } else { /* Allocate space for the names and the objects */ entries = (char**)cJSON_malloc(numentries * sizeof(char*)); if (!entries) return 0; names = (char**)cJSON_malloc(numentries * sizeof(char*)); if (!names) { cJSON_free(entries); return 0; } memset(entries, 0, sizeof(char*)*numentries); memset(names, 0, sizeof(char*)*numentries); /* Collect all the results into our arrays: */ child = item->child; depth++; if (fmt) len += depth; while (child) { names[i] = str = print_string_ptr(child->string, 0); entries[i++] = ret = print_value(child, depth, fmt, 0); if (str && ret) len += strlen(ret) + strlen(str) + 2 + (fmt ? 2 + depth : 0); else fail = 1; child = child->next; } /* Try to allocate the output string */ if (!fail) out = (char*)cJSON_malloc(len); if (!out) fail = 1; /* Handle failure */ if (fail) { for (i = 0; i<numentries; i++) { if (names[i]) cJSON_free(names[i]); if (entries[i]) cJSON_free(entries[i]); } cJSON_free(names); cJSON_free(entries); return 0; } /* Compose the output: */ *out = '{'; ptr = out + 1; if (fmt)*ptr++ = '\n'; *ptr = 0; for (i = 0; i<numentries; i++) { if (fmt) for (j = 0; j<depth; j++) *ptr++ = '\t'; tmplen = strlen(names[i]); memcpy(ptr, names[i], tmplen); ptr += tmplen; *ptr++ = ':'; if (fmt) *ptr++ = '\t'; strcpy(ptr, entries[i]); ptr += strlen(entries[i]); if (i != numentries - 1) *ptr++ = ','; if (fmt) *ptr++ = '\n'; *ptr = 0; cJSON_free(names[i]); cJSON_free(entries[i]); } cJSON_free(names); cJSON_free(entries); if (fmt) for (i = 0; i<depth - 1; i++) *ptr++ = '\t'; *ptr++ = '}'; *ptr++ = 0; } return out; }
这样都实现后, 字符串解析为 json 对象就实现了。
⑥序列化
序列化也就是格式化输出了。
序列化又分为格式化输出,压缩输出
/* Render a cJSON item/entity/structure to text. */ char *cJSON_Print(cJSON *item) { return print_value(item, 0, 1, 0); } char *cJSON_PrintUnformatted(cJSON *item) { return print_value(item, 0, 0, 0); } char *cJSON_PrintBuffered(cJSON *item, int prebuffer, int fmt) { printbuffer p; p.buffer = (char*)cJSON_malloc(prebuffer); p.length = prebuffer; p.offset = 0; return print_value(item, 0, fmt, &p); return p.buffer; } /* Render a value to text. */ static char *print_value(cJSON *item, int depth, int fmt, printbuffer *p) { char *out = 0; if (!item) return 0; if (p) { switch ((item->type) & 255) { case cJSON_NULL: {out = ensure(p, 5); if (out) strcpy(out, "null"); break; } case cJSON_False: {out = ensure(p, 6); if (out) strcpy(out, "false"); break; } case cJSON_True: {out = ensure(p, 5); if (out) strcpy(out, "true"); break; } case cJSON_Number: out = print_number(item, p); break; case cJSON_String: out = print_string(item, p); break; case cJSON_Array: out = print_array(item, depth, fmt, p); break; case cJSON_Object: out = print_object(item, depth, fmt, p); break; } } else { switch ((item->type) & 255) { case cJSON_NULL: out = cJSON_strdup("null"); break; case cJSON_False: out = cJSON_strdup("false"); break; case cJSON_True: out = cJSON_strdup("true"); break; case cJSON_Number: out = print_number(item, 0); break; case cJSON_String: out = print_string(item, 0); break; case cJSON_Array: out = print_array(item, depth, fmt, 0); break; case cJSON_Object: out = print_object(item, depth, fmt, 0); break; } } return out; }
假设我们要使用格式化输出, 也就是美化输出。
cjson 的做法不是边分析 json 边输出, 而是预先将要输的内容全部按字符串存在内存中, 最后输出整个字符串。
这对于比较大的 json 来说, 内存就是个问题了。
另外,格式化输出依靠的是节点的深度, 这个也可以优化, 一般宽度超过80 时, 就需要从新的一行算起的。
/* Render an object to text. */ static char *print_object(cJSON *item, int depth, int fmt, printbuffer *p) { char **entries = 0, **names = 0; char *out = 0, *ptr, *ret, *str; int len = 7, i = 0, j; cJSON *child = item->child; int numentries = 0, fail = 0; size_t tmplen = 0; /* Count the number of entries. */ while (child) numentries++, child = child->next; /* Explicitly handle empty object case */ if (!numentries) { if (p) out = ensure(p, fmt ? depth + 4 : 3); else out = (char*)cJSON_malloc(fmt ? depth + 4 : 3); if (!out) return 0; ptr = out; *ptr++ = '{'; if (fmt) { *ptr++ = '\n'; for (i = 0; i<depth - 1; i++) *ptr++ = '\t'; } *ptr++ = '}'; *ptr++ = 0; return out; } if (p) { /* Compose the output: */ i = p->offset; len = fmt ? 2 : 1; ptr = ensure(p, len + 1); if (!ptr) return 0; *ptr++ = '{'; if (fmt) *ptr++ = '\n'; *ptr = 0; p->offset += len; child = item->child; depth++; while (child) { if (fmt) { ptr = ensure(p, depth); if (!ptr) return 0; for (j = 0; j<depth; j++) *ptr++ = '\t'; p->offset += depth; } print_string_ptr(child->string, p); p->offset = update(p); len = fmt ? 2 : 1; ptr = ensure(p, len); if (!ptr) return 0; *ptr++ = ':'; if (fmt) *ptr++ = '\t'; p->offset += len; print_value(child, depth, fmt, p); p->offset = update(p); len = (fmt ? 1 : 0) + (child->next ? 1 : 0); ptr = ensure(p, len + 1); if (!ptr) return 0; if (child->next) *ptr++ = ','; if (fmt) *ptr++ = '\n'; *ptr = 0; p->offset += len; child = child->next; } ptr = ensure(p, fmt ? (depth + 1) : 2); if (!ptr) return 0; if (fmt) for (i = 0; i<depth - 1; i++) *ptr++ = '\t'; *ptr++ = '}'; *ptr = 0; out = (p->buffer) + i; } else { /* Allocate space for the names and the objects */ entries = (char**)cJSON_malloc(numentries * sizeof(char*)); if (!entries) return 0; names = (char**)cJSON_malloc(numentries * sizeof(char*)); if (!names) { cJSON_free(entries); return 0; } memset(entries, 0, sizeof(char*)*numentries); memset(names, 0, sizeof(char*)*numentries); /* Collect all the results into our arrays: */ child = item->child; depth++; if (fmt) len += depth; while (child) { names[i] = str = print_string_ptr(child->string, 0); entries[i++] = ret = print_value(child, depth, fmt, 0); if (str && ret) len += strlen(ret) + strlen(str) + 2 + (fmt ? 2 + depth : 0); else fail = 1; child = child->next; } /* Try to allocate the output string */ if (!fail) out = (char*)cJSON_malloc(len); if (!out) fail = 1; /* Handle failure */ if (fail) { for (i = 0; i<numentries; i++) { if (names[i]) cJSON_free(names[i]); if (entries[i]) cJSON_free(entries[i]); } cJSON_free(names); cJSON_free(entries); return 0; } /* Compose the output: */ *out = '{'; ptr = out + 1; if (fmt)*ptr++ = '\n'; *ptr = 0; for (i = 0; i<numentries; i++) { if (fmt) for (j = 0; j<depth; j++) *ptr++ = '\t'; tmplen = strlen(names[i]); memcpy(ptr, names[i], tmplen); ptr += tmplen; *ptr++ = ':'; if (fmt) *ptr++ = '\t'; strcpy(ptr, entries[i]); ptr += strlen(entries[i]); if (i != numentries - 1) *ptr++ = ','; if (fmt) *ptr++ = '\n'; *ptr = 0; cJSON_free(names[i]); cJSON_free(entries[i]); } cJSON_free(names); cJSON_free(entries); if (fmt) for (i = 0; i<depth - 1; i++) *ptr++ = '\t'; *ptr++ = '}'; *ptr++ = 0; } return out; }
static char *print_array(cJSON *item, int depth, int fmt, printbuffer *p) { char **entries; char *out = 0, *ptr, *ret; int len = 5; cJSON *child = item->child; int numentries = 0, i = 0, fail = 0; size_t tmplen = 0; /* How many entries in the array? */ while (child) numentries++, child = child->next; /* Explicitly handle numentries==0 */ if (!numentries) { if (p) out = ensure(p, 3); else out = (char*)cJSON_malloc(3); if (out) strcpy(out, "[]"); return out; } if (p) { /* Compose the output array. */ i = p->offset; ptr = ensure(p, 1); if (!ptr) return 0; *ptr = '['; p->offset++; child = item->child; while (child && !fail) { print_value(child, depth + 1, fmt, p); p->offset = update(p); if (child->next) { len = fmt ? 2 : 1; ptr = ensure(p, len + 1); if (!ptr) return 0; *ptr++ = ','; if (fmt)*ptr++ = ' '; *ptr = 0; p->offset += len; } child = child->next; } ptr = ensure(p, 2); if (!ptr) return 0; *ptr++ = ']'; *ptr = 0; out = (p->buffer) + i; } else { /* Allocate an array to hold the values for each */ entries = (char**)cJSON_malloc(numentries * sizeof(char*)); if (!entries) return 0; memset(entries, 0, numentries * sizeof(char*)); /* Retrieve all the results: */ child = item->child; while (child && !fail) { ret = print_value(child, depth + 1, fmt, 0); entries[i++] = ret; if (ret) len += strlen(ret) + 2 + (fmt ? 1 : 0); else fail = 1; child = child->next; } /* If we didn't fail, try to malloc the output string */ if (!fail) out = (char*)cJSON_malloc(len); /* If that fails, we fail. */ if (!out) fail = 1; /* Handle failure. */ if (fail) { for (i = 0; i<numentries; i++) if (entries[i]) cJSON_free(entries[i]); cJSON_free(entries); return 0; } /* Compose the output array. */ *out = '['; ptr = out + 1; *ptr = 0; for (i = 0; i<numentries; i++) { tmplen = strlen(entries[i]); memcpy(ptr, entries[i], tmplen); ptr += tmplen; if (i != numentries - 1) { *ptr++ = ','; if (fmt)*ptr++ = ' '; *ptr = 0; } cJSON_free(entries[i]); } cJSON_free(entries); *ptr++ = ']'; *ptr++ = 0; } return out; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号