
信息安全系统设计基础第五周学习总结
信息安全系统设计基础第五周学习总结
第五周(10.05-10.11):
学习计时:共7小时
读书:3h
代码:1h
作业:1h
博客:2h
3.1历史观点
1.Intel处理器的模型
8086
80286
i386
i486
Pentium
PentiumPro
Pentium II
Pentium III
Pentium 4
Pentium 4E
Core 2
Core i7
最初的8086提供的存储器模型和扩展已经过时了,作为替代,Linux使用了平坦存储方式。
3.2程序编码
假设一个C程序,有两个文件p1.c和p2.c。我们在一台IA32机器上,用Unix命令行编译这些代码如下:
unix> gcc -O1 -o p p1.c p2.c
实际上gcc命令调用了一系列程序,将源代码转化成可执行代码。首先,C预处理器扩展源代码,插入所有用#include命令指定的文件,并扩展所有用#define声明指定的宏。然后,编译器产生两个源代码的汇编代码,名字分别为p1.s和p2.s。接下来,汇编器将汇编代码转化成二进制目标代码文件,名为p1.o和p2.o。目标代码是机器代码的一种形式,它包括所有指令的二进制表示,但是还没有填入地址的全局至。最后,链接器将两个目标代码文件与实现库函数(例如printf)的代码合并,并产生最终的可执行代码文件p。可执行代码是我们要考虑的机器代码的第二种形式,也就是处理器执行的代码格式。
3.2.1机器级代码
1.两种抽象:指令集体系结构;机器级程序使用的存储器地址是虚拟地址,提供的存储器模型看上去是一个非常大的字节数组。
2.程序存储器(program memory)包含:程序的可执行机器代码、操作系统需要的一些信息、栈、堆。程序存储器用虚拟地址来寻址(此虚拟地址不是机器级虚拟地址)。操作系统负责管理虚拟地址空间(程序级虚拟地址),将虚拟地址翻译成实际处理器存储器中的物理地址(机器级虚拟地址)。
3.2.2代码示例
在命令行上使用-S选项得到C语言编译器产生的汇编代码
3.2.3关于格式的注释
ATT与Intel汇编代码格式
3.3数据格式
由于是从16位体系结构扩展成32位,intel用术语字(word)表示16位数据类型,因此32位为双字(double words),64位数为4字(quad words)。
以下是比较容易模糊的数据类型大小:
32位机上:float 4 long int 4 double 8 longlong 8 char* 4 unsigned long 4
64位机上:float 4 long int 8 double 8 longlong 8 char* 8 unsigned long 8
另外,GCC 用long double表示扩展精度(10字节),出于存储器性能考虑,会被存储为12字节
3.4访问信息
3.4.1操作数指示符
大多数指令有一到多个操作数,操作数有三种:
立即数:即常数值
寄存器:表示某个寄存器内容
存储器引用:根据计算出来的地址(通常称有效地址)访问某个存储器位置
因此寻址方式也有多种,如:立即数寻址、寄存器寻址、绝对寻址、间接寻址、变址寻址、伸缩化 的变址寻址
3.4.2数据传送指令
1.通过书中图3.5可知,当push一个数值时,栈指针减小,向下移动;当pop一个数据时栈指针向上移动。一般用 %esp来存储栈指针的地址。
2.move指令:将源操作符的值复制到目的操作数中。源操作数指定的值是一个立即数,存储在寄存器中或者存储器中。目的操作数指定一个位置,要么是一个寄存器,要么是一个存储器地址。。传送指令的链各个操作数不能都指向存储器位置。这些指令的寄存器操作数,对于movl来说,可以是8个32位寄存器(%eax%ebp),对于movw来说,可以是8个16位寄存器(%ax%bp),movb可以使单字节寄存器元素(%ah%bh,%al%bl)。
3.IA32加了一条限制,传送指令的两个操作数不能都指向存储器位置。讲一个值从一个存储器位置复制到另一个存储器位置需要两条指令-----第一条指令将源值加载到寄存器中,第二条将该寄存器值写入目的位置。
3.4.3数据传送示例
下面通过一个例子说明C语言中指针使用的方式,函数exchange代码如下:
int exchange(int *xp, int y)
{
int x = *xp;
*xp = y;
return x;
}
int a = 4;
int b = exchange(&a, 3);
printf("a = %d, b = %d\n", a, b);
这段代码会打印出: a = 3, b = 4
关键部分的汇编代码如下:
xp地址的值存储在8(%ebp), y的值存储在12(%ebp)
movl 8(%ebp) %edx #获取xp地址的值,存储在%edx
movl (%edx), %eax #获取xp地址所指向的值赋予变量x,函数结束时返回这个值
movl 12(%ebp), %ecx #获取y的值,存储在%ecx
movl %ecx, (%edx) #%ecx的值存储在%edx所指向的值, 这时候*xp的值为y,xp地址的值没有变化
局部变量比如x,通常时保存在寄存器中。
3.5算数和逻辑操作
3.5.1加载有效地址
加载有效地址(load effective address)指令leal实际上是movl指令的变形。通过下面一个例子来说明它的含义:
假设%edx的值为x
movl 7(%edx, %edx, 4), %eax #计算7 + x + 4x = 5x +7
那么%eax的值就是地址5x+7地址处所存储的值.
leal 7(%edx, %edx, 4), %eax #计算7 + x + 4x = 5x +7
那么%eax的值就是地址的值5x+7,而不是这个地址存储的值.
3.5.2一元操作和二元操作
如果一个操作只有一个操作数,既是源又是目的,这个操作就是一元操作。 如果一个操作有两个操作数,第二个操作数既是源又是目的,这个操作就是二元操作。 如下:
指令 效果 操作
INC D D <- D + 1 一元操作
ADD S, D D <- D + S 二元操作
3.5.3移位操作
类型 操作 命令
非循环移位 逻辑左移/算术左移 SHL/SAL
非循环移位 逻辑右移 SHR
非循环移位 算术右移 SAR
循环移位 不含进位位的循环左移 ROL
循环移位 不含进位位的循环右移 ROR
循环移位 含进位位的循环左移 RCL
循环移位 含进位位的循环右移 RCR
3.5.4讨论
3.5.5特殊的算术操作
3.6控制
3.6.1条件码
除了整数寄存器,CPU还维护着一组单个位的条件码(codition code)寄存器,最常用的条件码有:
CF:进位标志。最近的操作使最高位产生了进位。可以用来检测无符号操作数的溢出。
ZF:零标志。最近的操作得出的结果为0。
SF:符号标志。最近的操作得到的结果为负。
OF:溢出标志。最近的操作导致一个补码溢出——正溢出或负溢出。
3.6.2访问条件码
条件码通常不会直接读取常用的使用方法有三种:
可以根据条件码的某个组合,将一个字节设置为0或者1;
可以条件跳转到程序的某个其它部分;
可以有条件地传送数据.
对于第一种情况,举例说明一下:
指令 同义名 效果 设置条件
sete D setz D<-ZF 相等/零
setne D setnz D<-~ZF 不等/非零
sets D D<-SF 负数
setns D D<-~SF 非负数
setg D setnle D<-~(SF ^ DF)&~ZF 大于(有符号>)
SET指令。每条指令根据条件码的某个组合将一个字节设置为0或者1,而不是直接访问条件码寄存器。
3.6.3跳转指令及其编码
1.正常情况下,指令按照它们出现的顺序一条一条地执行。跳转(jump)指令会导致执行切换到程序中一个全新的位置。在汇编代码中,这些跳转的目的地通常用一个标号(label)指明。当执行与PC(程序计数器)相关的寻址时,程序计数器的值是跳转指令后面的那条指令的地址,而不是跳转指令本身的地址。
2.Jmp指令也有很多兄弟,其兄弟形式如set,例如:je jne ……
3.6.4翻译条件分支
如何将条件表达式和语句从C语言翻译成机器代码,最常用的方式是结合有条件和无条件跳转。
3.6.5循环
循环和条件分支所利用的都是jump指令和标记寄存器的值
3.6.6条件传送指令
实现条件操作的传统方法是利用控制的条件转移。但是在现代处理器上,它可能会非常的低效率。数据的条件转移是一种替代的策略。这种方法先计算一个条件操作的两种结果,然后再根据条件是否满足选取一个。
3.6.7switch语句
switch(开关)语句可以根据一个整数索引值进行多重分支(multi-way branching)。处理具有多种可能结果的测试时。这种语句特别有用。它们不仅提高了C代码的可读性,而且通过使用跳转表(jump table)这种数据结构使得实现更加高效。
3.7过程
一个过程调用包括将数据(以过程参数和返回值的形式)和控制从代码的一部分传递到另一部分。另外,它还必须在进入时为过程的局部变量分配空间,并在退出时释放这些空间。数据传递、局部变量的分配和释放通过操纵程序栈来实现。
3.7.1桢栈结构
为单个过程分配的那部分栈称为栈帧(stack frame)。寄存器%ebp为帧指针,而寄存器%esp为栈指针。栈帧结构(栈用来传递参数、存储返回信息、保存寄存器,以及本地存储)
3.7.2转移控制
支持过程调用和返回的指令:
指令 描述
call Label 过程调用
call *Operand 过程调用
leave 为返回准备栈
ret 从过程调用中返回
call指令的效果是将返回地址入栈,并跳转到被调用过程的起始处。返回地址是在程序中紧跟在call后面的那条指令地址。
3.7.3寄存器使用惯例
程序寄存器组是唯一能被所有过程共享的资源。虽然在给定时刻只能有一个过程是活动的,但是我们必须保证当一个过程(调用者)调用另一个过程(被调用者)时,被调用者不会覆盖某个调用者稍后会使用的寄存器的值。根据惯例,寄存器%eax、%edx和%ecx被划分为调用者保存寄存器。当过程P调用Q时,Q可以覆盖这些寄存器,而不会破任何P所需要的数据。另一方面,寄存器%ebx、%esi和%edi被划分为被调用者保存寄存器。这意味着Q必须在覆盖这些寄存器之前,先把它们保存到栈中,并在返回前恢复它们。
3.7.4过程示例
3.7.5递归过程
每个调用过程都有它自己的私有空间,多个未完成调用的局部变量不会相互影响。
3.8数组分配和访问
3.8.1基本原则
对于数据类型T和整型常数N,声明如下:
T A[N] 它有两个效果:
它在存储器中分配一个( L \bullet N )字节的连续区域;这里L是数据类型T的大小(单位为字节), 用 ( x_{A} ) 来表示起始位置。
它引入了标符A;可以用A作为指向数组开头的指针,这个指针的值就是 (x_{A}) 。数组元素i被存放在地址为 (x_{A} + L \bullet i)的地方。
3.8.2指针运算
3.8.3嵌套的数组
3.8.4定长数组
3.8.5变长数组
c99引入了一种能力,允许数组的维度是表达式,在数组分配的时候才计算出来。
3.9异质的数据结构
C语言提供了两种结合不同类型的对象来创建数据类型的机制:结构(structure),用关键字struct声明, 将多个对象集合到一个单位中;联合(union), 用关键字union声明,允许用集中不同的类型来引用一个对象。
3.9.1结构
3.9.2联合
当用联合将各种不同大小的数据类型结合到一起时,字节顺序问题就变得很重要了。这时,大端和小端的区别就会体现。
3.9.3数据对齐
许多计算机系统对基本数据类型合法地址做出了一些限制,要求某种类型对象的地址必须是某个值k(通常是2,4或8)的倍数。这种对齐限制简化了形成处理器和存储器系统之间接口的硬件设计
3.10综合:理解指针
指针和它们映射到机器代码的关键原则:
每个指针都对应一个类型。void * 类型代表通用指针。
每个指针都有一个值。这个值是某个指定类型对象的地址。
指针用&运算符创建。常用leal指令来计算表达式的值。int * p = &x
操作符用于指针的间接引用。
数组与指针紧密联系。
将指针从一种类型强制转换为另一种类型,只改变它的类型,而不改变它的值。
指针也可以指向函数。
3.11使用GDB调试器
3.12存储器的越界引用和缓冲区溢出
1.C对于数组引用不进行任何边界检查,而且局部变量和状态信息(例如保存的寄存器值和返回地址),都存放在栈中。这两种情况结合到一起就可能导致严重的程序错误,对越界的数组元素的写操作会破坏存储在栈中的状态信息。一种常见的状态破坏称为缓冲区溢出(buffer overflow)。
2.蠕虫(worm)是这样一个程序,它可以自己运行,并且能够将一个完全有效的自己传播到其他机器。病毒(virus)是这样一段代码,它能将自己添加到包括操作系统在内的其他程序中,但它不能独立运行。
3.对越界的数组元素进行写操作会破坏存储在栈中的状态信息。
4.缓冲区溢出:在栈中分配某个字节数组来保存一个字符串,但是字符串的长度超出了为数组分配的空间。
5.缓冲区溢出的一个更加致命的使用就是让程序执行它本来不愿意执行的函数——通常给程序一个字符串,字符串包含两部分:可执行代码的字节编码(攻击代码),以及,会用一个指向前面可执行代码的指针覆盖返回地址。这样,当ret的时候,控制就交给了可执行代码。
6.可执行代码的字节编码(攻击代码)的攻击形式:一种方式是攻击代码会使用系统调用启动一个外壳程序,给攻击者提供一组操作系统函数。另一种方式是,攻击代码会执行一些未授权的任务,修复对栈的破坏,然后第二次执行ret指令,(表面上)正常返回给调用者。
3.13x86-64将IA32扩展到64位
3.13.1x86-64的历史和动因
虽然后续的处理器系列引入了新的指令类型和格式,但是为了保持向后兼容性,许多编译器,包括GCC,都避免使用这些新特性。
3.13.2x86-64简介
3.13.3访问信息
3.13.4控制
3.13.5数据结构
3.13.6关于x86-64的总结性评论
3.14浮点程序的机器级表示
我们把浮点存储模型,指令和传递规则的组合称为机器的浮点体系结构。x86的历史中有多种浮点体系结构,目前有两种还在使用:x87和SSE。
3.15小结
学习重点
本章学习内容是汇编语言,现在直接写汇编的机会不多了,但一定要能读懂,信息安全的核心思维方式“逆向”在这有很好很直接的体现,反汇编就是直接的逆向工程。
本章重点是3.7,但没有3.1-3.6的基础也是不行,如果想真正的提高动手能力,3.11如何用GDB调试汇编要好好练习一下,不过大多GDB技巧大家都会了。
3.1-3.7中练习,重点:3.1,3.3,3.5,3.6,3.9,3.14,3.15,3.16,3.22,3.23,3.27,3.29,3.30,3.33,3.34
p104, p105: X86 寻址方式经历三代:
1 DOS时代的平坦模式,不区分用户空间和内核空间,很不安全
2 8086的分段模式
3 IA32的带保护模式的平坦模式
p106: ISA的定义,ISA需要大家能总结规律,举一反三,比如能对比学习ARM的ISA;PC寄存器要好好理解;
p107: gcc -S xxx.c -o xxx.s 获得汇编代码,也可以用objdump -d xxx 反汇编; 注意函数前两条和后两条汇编代码,所有函数都有,建立函数调用栈帧,应该理解、熟记。
注意: 64位机器上想要得到32代码:gcc -m32 -S xxx.c
MAC OS中没有objdump, 有个基本等价的命令otool
Ubuntu中 gcc -S code.c (不带-O1) 产生的代码更接近教材中代码(删除"."开头的语句)
p108: 二进制文件可以用od 命令查看,也可以用gdb的x命令查看。
有些输出内容过多,我们可以使用 more或less命令结合管道查看,也可以使用输出重定向来查看
od code.o | more
od code.o > code.txt
p109: gcc -S 产生的汇编中可以把 以”.“开始的语句都删除了再阅读
p110: 了解Linux和Windows的汇编格式有点区别:ATT格式和Intel格式
p111: 表中不同数据的汇编代码后缀
p112: 这几个寄存器要深入理解,知道它们的用处。esi edi可以用来操纵数组,esp ebp用来操纵栈帧。
对于寄存器,特别是通用寄存器中的eax,ebx,ecx,edx,大家要理解32位的eax,16位的ax,8位的ah,al都是独立的,我们通过下面例子说明:
假定当前是32位x86机器,eax寄存器的值为0x8226,执行完addw $0x8266, %ax指令后eax的值是多少?
解析:0x8226+0x826=0x1044c, ax是16位寄存器,出现溢出,最高位的1会丢掉,剩下0x44c,不要以为eax是32位的不会发生溢出.
p113: 结合表,深入理解各种 寻址方式;理解操作数的三种类型:立即数、寄存器、存储器;掌握有效地址的计算方式 Imm(Eb,Ei,s) = Imm + R[Eb] + R[Ei]*s
p114: MOV相当于C语言的赋值”=“,注意ATT格式中的方向, 另外注意不能从内存地址直接MOV到另一个内存地址,要用寄存器中转一下。能区分MOV,MOVS,MOVZ,掌握push,pop
p115/p116: 栈帧与push pop; 注意栈顶元素的地址是所有栈中元素地址中最低的。
p117: 指针就是地址;局部变量保存在寄存器中。
p119: 结合表理解一下算术和逻辑运算, 注意目的操作数都是什么类型
特别注意一下减法是谁减去谁
注意移位操作移位量可以是立即数或%cl中的数
p123: 结合C语言理解一下控制部分,也就是分支(if/switch),循环语句(while, for)如何实现的。考验大家举一反三的学习能力。控制中最核心的是跳转语句:有条件跳转p128(实现if,switch,while,for),无条件跳转jmp(实现goto)
p124: 有条件跳转的条件看状态寄存器(教材上叫条件码寄存器)
注意leal不改变条件码寄存器
思考一下:CMP和SUB用在什么地方
p125: SET指令根据t=a-b的结果设置条件码
p127: 跳转与标号
p130/p131: if-else 的汇编结构
p132/p133: do-while
p134/p135: while
p137/p138: for
p144/p145: switch
p149: IA32通过栈来实现过程调用。掌握栈帧结构,注意函数参数的压栈顺序.
p150/p151: call/ret; 函数返回值存在%eax中
p174: bt/frame/up/down :关于栈帧的gdb命令
实验楼实验五
要求
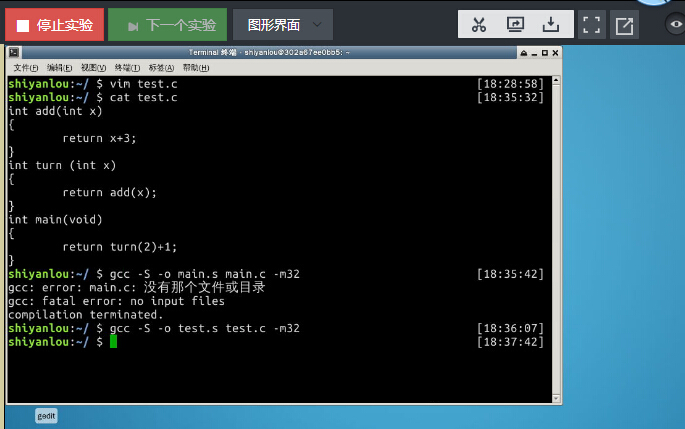
使用gcc –S –o main.s main.c -m32
命令编译成汇编代码,如下代码中的数字和函数名请自行修改以防与他人雷同
int g(int x)
{
return x + 3;
}
int f(int x)
{
return g(x);
}
int main(void)
{
return f(8) + 1;
}
1.删除gcc产生代码中以"."开头的编译器指令,针对每条指令画出相应栈帧的情况
2.(选做)使用gdb的bt/frame/up/down 指令动态查看调用栈帧的情况
过程
1.反汇编代码
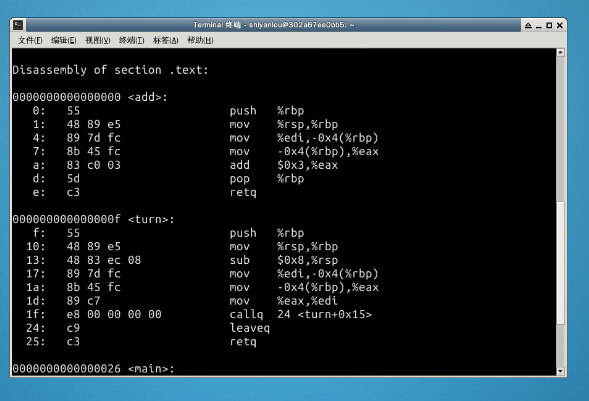
2.汇编结果

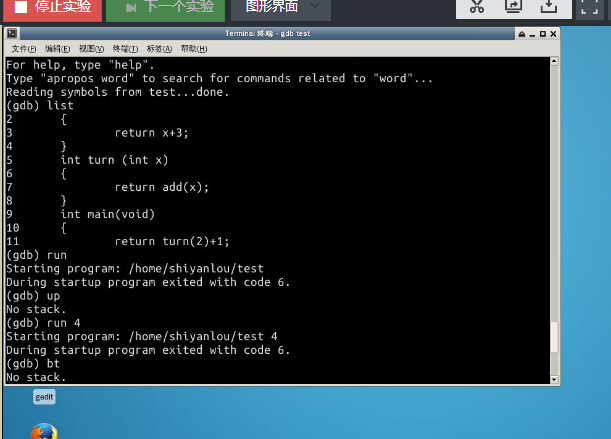
3.使用GDB的堆栈跟踪功能
还不会用这个功能,使用bt的时候为空,想借本Linux的书再学习一下后再做一遍。
遇到的问题
问题:
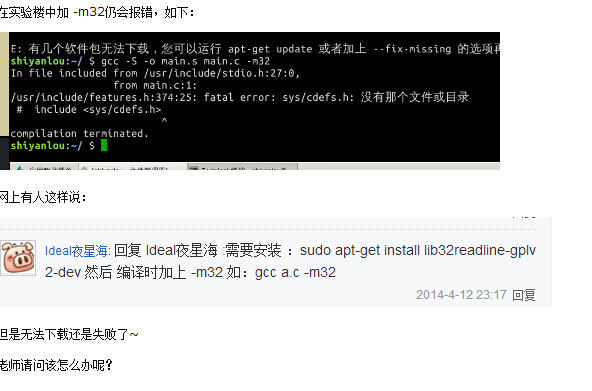
解决方法:
作业3.66
1. 1 typedef struct {
2. 2 int left;
3. 3 a_struct a[CNT];
4. 4 int right;
5. 5 } b_struct;
6. 6
7. 7 void test(int i, b_struct *bp)
8. 8 {
9. 9 int n = bp->left + bp->right;
10.10 a_struct *ap = &bp->a[i];
11.11 ap->x[ap->idx] = n;
12.12 }
查看文本打印
1. 1 000000
2. 2 0: 55 push %ebp
3. 3 1: 89 e5 mov %esp,%ebp
4. 4 3: 53 push %ebx
5. 5 4: 8b 45 08 mov 0x8(%ebp),%eax ;%eax=i
6. 6 7: 8b 4d 0c mov 0xc(%ebp),%ecx ;%ecx=bp
7. 7 a: 8b d8 1c imul $0x1c,%eax,%ebx ;%ebx=i28
8. 8 d: 8d 14 c5 00 00 00 00 lea 0x0(,%eax,8),%edx ;%edx=8i;
9. 9 14: 29 c2 sub %eax,%edx ;%edx=7i;
10.10 16: 03 54 19 04 add 0x4(%ecx,%ebx,1),%edx ;%edx=7i+[bp+28i+4]
11.11 1a: 8b 81 c8 00 00 00 mov %0xc8(%ecx),%eax ;%eax=right
12.12 20: 03 01 add (%ecx),%eax ;%eax=right+left
13.13 22: 89 44 91 08 mov %eax,0x8(%ecx,%edx,4) ;[bp+47i+4*[bp+28i+4]+0x8]=%eax
14.14 26: 5b pop %ebx
15.15 27: 5d pop %ebp
16.16 28: c3 ret
第22行,bp+47i+4[bp+28i+4]+0x8=bp+4+28i+4*[bp+28i+4]+4。这个地址就是ap->x[ap->idx]。bp+4是a[CNT]的首地址,bp+28i+4可以看作是ap->idx。那么我们就很容推出sizeof(a_struct)大小为28bytes。在a_struct中,idx的偏移为0。而b.struct.a.struct.x[]偏移为(bp+4+28i)+4,也进一步证明了sizeof(a_struct)的大小为28bytes。right在b_struct中的偏移0xc8,也就是十进制的200,而a[CNT]的偏移为4,则数组的总大小为196,196/28=7,则CNT=7。
a_struct的大小为28bytes,idx的大小为4byte,剩下来24bytes都被x数组所占用,故x数组中有6个元素。它的结构是:
查看文本打印
1.1 struct {
2.2 int idx;
3.3 int x[6];
4.4 }a_struct;
参考资料
- 教材:第三章《程序的机器级表示》,详细学习指导:http://group.cnblogs.com/topic/73069.html 重点是3.7,3.11
- 课程资料:https://www.shiyanlou.com/courses/413 实验四,课程邀请码:W7FQKW4Y
- 教材中代码运行、思考一下,读代码的学习方法:http://www.cnblogs.com/rocedu/p/4837092.html。
- AT&T格式汇编与intel汇编区别:http://blog.sina.com.cn/s/blog_4017fe890102uws4.html
- 做实验理解栈帧的参考:http://www.codes51.com/article/detail_116649.html
http://blog.csdn.net/a363344923/article/details/44116651
感悟
起初看到书中的汇编代码时感到非常迷茫,因为跟上学期学到的汇编很不一样,然后就将书中的一行代码敲进了百度的搜索栏里,发现我们熟悉的是Intel汇编代码格式,但是在Linux下的GCC、OBJDUMP等工具都是使用ATT格式,后来书上也有提到这个问题。因此首先要适应这种转变。
看到网上有总结这两种格式在以下方面是有区别的:
1、Intel省略了大小后缀;
2、Intel省略了%;
3、Intel使用DWORD PTR [ebp+12]而不是12(%ebp), %eax ;
4、带有多个操作数时,顺序相反;
5、ATT使用立即数前面要加 $ 符号。
考试和平时都发现了自己在Linux上的缺陷,还需要补一下怎么使用。

