

有时候一个念头或想法在不经意间蹦出——就像是一段美好的邂逅,让人淡然而有些欣喜。写这篇博客的由来也是如此,——“查询条件的排序的不同可能会对查询效率有影响”的想法突然出现在我的脑海里,而且我饶有兴致的细想了下,经过测试,但无奈的是我本地只有2w多的数据量,数据量太小,无法测试出其真实的结果,这也是为何这篇博客的标题中说是'漫谈'的原因;'漫谈'很可能就是乱弹,我所说的只是我想当然的,未经证实;但我仍想也感觉有必要把所考虑的跟大家分享交流下,就是板儿砖满天飞也无所谓,以求正解!

如上图,就是淘宝网的商品搜索页,我所要说的会直截了当的围绕上图谈起——只用看上图中绿色框部分,对于搜索功能的sql查询,分别是 价格和分类 这两个查询(where)条件,单就(where)条件的拼接有以下两种写法(以下sql只是为了辅助说明我的想法而已,非淘宝真实实现):
1.select * from product where price>=45 and price<=138 and category='恒源祥'
2.select * from product where category='恒源祥' and price>=45 and price<=138
两条sql看起来一样,最后查询到的结果也相同,只是查询条件价格和分类的顺序不同。以
如果我以上的设想或考虑成立,我倒是感觉为了提高查询效率,应该在每个项目的后台管理中可以动态根据不同时期或情况设置数据查询各个条件的排序。
此文就写到这里,提出两个问题,希望知道的朋友能不吝赐教!
Q1:数据库sql查询分析引擎是否会对查询sql语句进行优化或其它处理?
Q2:本文所说的观点是否正确?
最后,附上SQL Server调优(性能诊断)DMV查询SQL,希望对需要的朋友有所帮助。

1 set transaction isolation level read uncommitted 2 3 select top 20 4 CAST(qs.total_elapsed_time/1000000.0 as decimal(28,2)) 5 as [Total Elapsed Duration (s)] 6 ,qs.execution_count 7 ,SUBSTRING(qt.text,(qs.statement_start_offset/2)+1, 8 ((Case when qs.statement_end_offset=-1 9 Then len(CONVERT(Nvarchar(max),qt.text))*2 10 else 11 qs.statement_end_offset 12 end - qs.statement_start_offset)/2)+1) as [Individual Query] 13 ,qt.text as [Parent Query] 14 ,DB_NAME(qt.dbid) as databseName 15 ,qp.query_plan 16 from sys.dm_exec_query_stats qs 17 cross apply sys.dm_exec_sql_text(qs.sql_handle) qt 18 cross apply sys.dm_exec_query_plan(qs.plan_handle) qp 19 20 order by total_elapsed_time desc
查询结果如下:
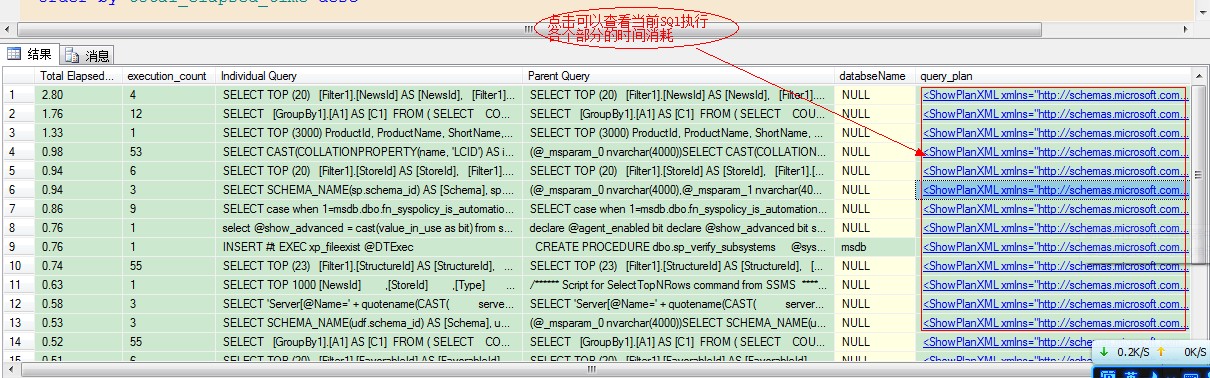
通过以上查询可以得到最消耗性能的前20条SQL语句,并对其进行优化处理!



· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· DeepSeek “源神”启动!「GitHub 热点速览」
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· DeepSeek R1 简明指南:架构、训练、本地部署及硬件要求
· NetPad:一个.NET开源、跨平台的C#编辑器