

一、提取搜索结果
1、TopDocs对象的说明
- MaxScore:最高得分;
- TotalHits:匹配到的结果总数;
- ScoreDocs:匹配到的文档数组(内部可以获得文档Id与分数);
下面来看看获得的结果信息:
Console.WriteLine(docs.MaxScore); //输出最高得分 Console.WriteLine(docs.TotalHits); //输出搜索结果数量 foreach (ScoreDoc d in docs.ScoreDocs) //输出文档得分与文档ID { Console.WriteLine(d.Score); Console.WriteLine(d.Doc); }
2、搜索性能说明
为了快速搜索,可以先将文件索引读入内存,建立起内存中的索引,然后再进行搜索。
DirectoryInfo dir = new DirectoryInfo(@"D:\3"); Lucene.Net.Store.Directory directory1 = new SimpleFSDirectory(dir); //将索引文件读入内存 Lucene.Net.Store.Directory rd = new RAMDirectory(directory1); //再从内存索引查找 using (IndexSearcher searcher = new IndexSearcher(rd)){}
二、过滤搜索结果
当搜索结果中含有的记录只有一部分满足要求时吗,可以通过过滤的方法将无用的记录滤去,从而得到更好的搜索结果。
过滤搜索结果的方式有这样两种:一种是在搜索结果提取出来以后过滤,另一种是把过滤条件加在搜索条件中实现过滤。
1、搜索结果提取出来以后过滤

for (int i = 0; i < docs.TotalHits; i++) { Document doc = MySearcher.Doc(docs.ScoreDocs[i].Doc); //输出 张飞打架 或关系 string name = doc.Get("title"); if (name.Contains("张飞")) { continue; } Console.WriteLine(name); }
2、利用Lucene的Filter过滤
Filter用于从搜索结果中筛选出满足特定条件的记录。
1、PrefixFilter
PrefixFilter用于从搜索结果中得到具有某一前缀要求的记录。
//搜索包含“打”的结果 Term t1 = new Term("title", "打"); Query query = new TermQuery(t1); //筛选出以关开始的结果 Term t2 = new Term("title", "关"); PrefixFilter filter = new PrefixFilter(t2); TopDocs docs = MySearcher.Search(query, filter, 10);
2、NumericRangeFilter
过滤掉不在某范围内的数据,在搜索结果中过滤掉大于18岁的数据。
NumericRangeFilter<int> NumFilter = NumericRangeFilter.NewIntRange("Age", 0, 18, true, true);
过滤掉不在NumericRangeFilter范围内的数据。
3、CachingWrapperFilter
CachingWrapperFilter被开发出来用于包装其他的Filter,从而使之具有缓存功能。
其构造方法如下:
CachingWrapperFilter(Filter filter);
使用方法如下:
NumericRangeFilter<int> NumFilter = NumericRangeFilter.NewIntRange("Age", 0, 18, true, true); CachingWrapperFilter c = new CachingWrapperFilter(NumFilter);
4、FilteredQuery
FilterQuery是一种带有过滤器的特殊Query类,它是一种包装器,将原始的Query对象和某个过滤器结合起来,从而达到过滤的目的。
由于有了这个方法的存在,我们有了两种方式来过滤搜索结果:
- 使用Query加Filter,得到Filter,然后使用Search(Query对象,Filter对象)方法执行搜索。
- 使用Query加Filter,得到Query,然后使用Search(Query对象方法)执行搜索。
示例:
NumericRangeQuery<int> query = NumericRangeQuery.NewIntRange("Age", 0, 30, true, true); NumericRangeFilter<int> NumFilter = NumericRangeFilter.NewIntRange("Age", 0, 18, true, true); FilteredQuery fq = new FilteredQuery(query, NumFilter); TopDocs docs = searcher.Search(fq, null, 10);
5、建议
- 使用过滤器消耗资源、慎用。
- 如果一定要使用过滤器,应使用带缓存的过滤器,如CachingWrapperFilter进行包装。
三、搜索结果的排序
Lucene的搜索结果默认是按照得分进行排序的,我们可以根据需要使其按照其他规则进行排序。
1、按照文档得分排序
1、默认的排序规则
Lucene在建立索引时,对每个文档进行评分(计算相关度),也就是确定其权重。这个得分是相对于搜索关键词的,根据不同的关键词去搜索得到的相同的文档,其得分往往不同。
搜索结果默认是按照得分进行排序的,而且是倒序,即按照得分从高到低进行排序。如果两个文档的得分相同,则按照对文档建立索引的顺序排列。
如:


我们,看到当关键字改变了,得分也变了。
2、修改默认得分
Lucene通过一个公式来计算每个文档的得分,这个很复杂,不懂。每个文档的得分受到多个因素的影响,我们可以通过这些因素来改变某个文档的得分。
最常用的修改得分方式是通过Document的Boost属性:
document1.Boost = 1.0f;
Boost是影响得分的主要因素之一。如果不考虑其他因素,boost值越大,得分越大,搜索结果的排名越靠前。但是,由于Lucene搜索结果的排名包括很多因素,所以单纯地增加boost并不总能提高排名顺序。
Document和Field类都具有这个方法。Document类的Boost属性用来设定其所含有的所有Field的Boost值,Field类的Boost用来设定该Field的Boost值。对于Boost值的设定是建立索引的过程中进行的,也就是对某个文档调用AddDocument方法之前。
Field f1 = new Field("title", "张飞很能打", Field.Store.YES, Field.Index.ANALYZED); f1.Boost = 1.0f;
Boost设置的值只代表我们对文档排名的期待,这个值要经过进一步的计算才能转化为文档真正的Boost值。我们不需要关心其计算方法,我们需要的是相对排名,而不是绝对数值。
3、查看得分计算过程
Lucene提供了一个方法,可以用来查看得分的计算过程。这个方法就是Searcher类的Explain方法。
该方法调用方式如下:
searcher.Explain(query, docs.ScoreDocs[i].Doc);
第一个参数是被解释的Query对象,第二个对象是索引中的文档序号。返回值是一个Explanation对象,这个对象包括GetDetails()、IsMatch(),ToHtml(),ToString()等方法;
for (int i = 0; i < docs.TotalHits; i++) { Explanation exp = searcher.Explain(query, docs.ScoreDocs[i].Doc); Console.WriteLine(exp.IsMatch); Console.WriteLine(exp.GetDetails()); Console.WriteLine(exp.ToString()); }
其输出结果如下:
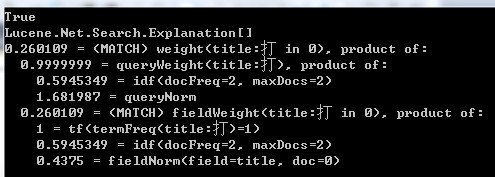
执行Explain方法是要付出代价的,而且代价不小。这代价相当于执行对整个索引的查询。所以,除非必要,否则不要轻易使用。
2、自定义排序算法
有时候,我们需要修改默认的排序规则。例如,按照日期排序,或者按照多个字段组合排序等。
假设我们做一个新闻网搜索引擎,如果搜索按照文档得分排序。那么,往往会导致旧的文档排在新文档前面。得分高的文档永远排在前面。
要解决这个问题,有如下方法:
- 修改评分规则,使得新发布的新闻得分永远高于旧新闻。
- 在搜索结果显示的过程中做过滤,使得旧新闻在显示的时候排在新发布的新闻后面。
- 建立新的排序规则,使搜索结果按照新规则排序。例如,使搜索结果按照日期排序。或者利用评分规则,得分相同的文档按照日期的先后排序。
本处主要讲解第三种方法。
需要自定义排序规则,需要使用Sort类。
1、Sort()
按照系统自己的排序规则,不施加人工干预。这个构造方法没什么用。
2、Sort(String field)
按照指定的某个field进行排序,参数是该field的名称。
3、Sort(String[] fields)
按照指定的多个field进行排序,参数是这些field的名称。
4、Sort(SortField field)
按照指定的某个field进行排序,注意:这个field不是原始的字段名称,而是SortField对象
5、Sort(SortField[] fields)
按照指定的多个field进行排序,注意:这些field不是原始的字段名称,而是SortField对象
6、Sort(String field,boolean reverse)
按照指定的某个field进行排序,第一个参数是该field的名称,第二个参数用来指定是降序(从大到小)还是升序(从小到大),若为false,是升序,这也是默认值。
Sort类除了具有以上方法之外,还具有两个静态属性。
(1)public static final Sort RELEVANCE
使用RELEVANCE属性相当于没有使用Sort方法,它将排序的规则交给系统去决定了。
(2)public static final Sort INDEXORDER
使用INDEXORDER属性相当于按照索引内部的文档编号去进行排序。
在构造好Sort对象以后,就可以通过Search(Query对象,Sort对象)来执行搜索了。
注意:
- 被指定作为排序依据的字段必须被索引并且不能被分词,这是因为,如果一个字段被分词了,它往往会失去本来的意思。这样一来,排序就无从红丝线。如果我们试图对一个做了分词的字段作排序,Lucene会抛出异常。
- 被指定作为排序依据的字段可以存储也可以不存储。
- 被指定作为排序依据的字段的值类型必须是可排序的整型、浮点型或者字符型。系统会根据字段的第一个值自动判断字段类型。整型和浮点型排序效率高,系统消耗少。
3、让系统决定如何排序
要让系统决定如何排序,可以使用Sort类的RELEVANCE。
TopDocs docs = searcher.Search(query, null, 1000, Sort.RELEVANCE);
4、按照索引中的文档编号排序
按照索引中的文档编号排序,要使用Sort类的INDEXORDER属性。
TopDocs docs = searcher.Search(query, null, 1000, Sort.INDEXORDER);
5、按照文档字段,指定类型排序
我们使用Sort(String field)和Sort(String field,boolean reverse)两个方法来演示按照某个字段进行排序的方法。
下面的示例,我们队常见的文本字段进行排序。注意:我们的文本字段没有作分词。
//建立索引 using (IndexWriter writer = new IndexWriter(directory1, analyzer, maxFieldLength)) { Document document1 = new Document(); document1.Add(new Field("title", "大神", Field.Store.YES, Field.Index.NOT_ANALYZED)); document1.Add(new Field("time", "2010-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED)); writer.AddDocument(document1); Document document2 = new Document(); document2.Add(new Field("title", "大神", Field.Store.YES, Field.Index.NOT_ANALYZED)); document2.Add(new Field("time", "2011-01-01", Field.Store.YES, Field.Index.NOT_ANALYZED)); writer.AddDocument(document2); } //查找 using (IndexSearcher searcher = new IndexSearcher(directory1)) { Term t = new Term("title", "大神"); TermQuery query = new TermQuery(t); SortField sf = new SortField("time", SortField.STRING, true); //true false 决定顺序Or倒序 Sort sort = new Sort(sf); TopDocs docs = searcher.Search(query, null, 10, sort); for (int i = 0; i < docs.TotalHits; i++) { Document doc = searcher.Doc(docs.ScoreDocs[i].Doc); string name = doc.Get("time"); Console.WriteLine(name); } }
这里,我们指定了按照time字段进行排序。并且time字段的数据类型为String。所以Lucene.net把他们当做字符串进行排序。如果我们在排序的时候没有指定将某个字段看做某种类型的话,那么Lucene会首先尝试将这个字符串转换成int类型,如果转换失败,会继续尝试将其转换为float类型,如果还是转换失败,这时就把它当做字符串来处理。
要良好地控制排序规则,我们必须自己去指定Lucene把某个字段当成某种类型。
其中,SortField支持的类型如下:
- public const int BYTE = 10;
- public const int CUSTOM = 9;
- public const int DOC = 1;
- public const int DOUBLE = 7;
- public const int FLOAT = 5;
- public const int INT = 4;
- public const int LONG = 6;
- public const int SCORE = 0;
- public const int SHORT = 8;
- public const int STRING = 3;
- public const int STRING_VAL = 11;
6、按多个字段排序
同时按照多个字段排序,只需将作为排序依据的字段合起来,以数组形式传递给Sort方法即可。
如,下面的示例中,每个文档含有id,age和text三个字段,其中id和age两个字段是可以转换成数字类型的。我们按照id和age两个字段进行组合排序。
SortField sf1 = new SortField("id",SortField.INT, false); //按id升序 SortField sf2 = new SortField("age", SortField.INT, true); //按age降序 Sort sort = new Sort(sf1,sf2); TopDocs docs = searcher.Search(query, null, 10, sort);
我们有时需要让排序所依据的多个字段按照不同的升降顺序去排列,这时就需要建立SortField对象,在SortField对象中指定字段的排序规则,然后将SortField对象数组传入Sort类的构造方法。
7、综述
排序是消耗资源的事情,越复杂消耗越大。
通常,按照得分去排序就足够了。
另外,Lucene提供了对于复杂自定义类型字段的排序接口,例如希望将三维坐标值以字符串形式保存在索引中,然后在提取出来的时候进行排序。但是,要实现这种排序消耗资源太多。
实际的工厂项目所要求的是执行效率,而不是概念。我们完全可以通过编码解码的方法来解决复杂自定义类型的存储、搜索和排序问题。我们甚至可以为某个不方便排序的字段专门建立一个辅助字段,将复杂数据类型转换成可以表示其大小的数值存储在辅助字段中,这样,搜索的时候就非常容易排序了。
四、搜索结果的高亮显示
1、关于高亮显示
当搜索引擎显示出搜索结果之后,最好将搜索结果中的关键词以某种醒目的方式显示出来,从而使用户知道他所搜索的关键词在文档中的位置。搜索引擎完成这项操作就叫做高亮显示。高亮显示的方法就是给文档中的关键词设置特殊的显示格式。例如,加上背景色,或者将关键词的显示颜色改变、加粗、变成斜体等。
在Web搜索中,通常使用修改关键词文本背景色、加粗显示和修改文本颜色的方法来实现高亮。
2、Lucene高亮处理的基本方式
实现高亮的原理是:
- 建立索引时,在文档的相关字段(需要高亮处理的字段,被搜索的字段)中记录词条(Term)的位置。
- 搜索时,利用字段中记录的词条的位置信息,将修饰符号添加进去,从而改变了搜索关键词的显示格式,达到了突出显示的目的。
(1)建立索引时,在文档的相关字段中记录词条的位置
document.Add(new Field("text", "大神", Field.Store.YES, Field.Index.NOT_ANALYZED, Field.TermVector.WITH_OFFSETS));
最后一个参数表示,在构造Field对象时,就可以将词条位置信息记录进去。
(2)在搜索时修改词条文本的显示格式
要实现这一步,首先要构造Highlighter对象,Highlighter类的最基本构造方法是(使用此类要引用Lucene.Net.Contrib.Highlighter.dll):
Highlighter(IScorer fragmentScorer)
其参数类型IScorer是一个接口,它的一个常用实现类是QueryScorer,这个类可以有QueryScorer(Query query)方法来构造。
TermQuery query = new TermQuery(t); QueryScorer qs = new QueryScorer(query); Highlighter hl = new Highlighter(qs);
Highlighter类通过TextFragmenter属性来设置文本的分块,其参数是Fragmenter类型,Fragmenter是一个接口,它最常用的子类是SimpleFragmenter,可以通过SimpleFragmenter()或SimpleFragmenter(int fragmentSize)方法来构造。其他第二个构造方法的参数表示分块的大小,也就是显示给用户的含有关键词的文本块的大小。
class Program { static void Main(string[] args) { Analyzer analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_30); IndexWriter.MaxFieldLength maxFieldLength = new IndexWriter.MaxFieldLength(10000); Lucene.Net.Store.Directory directory1 = new RAMDirectory(); //建立索引 using (IndexWriter writer = new IndexWriter(directory1, analyzer, maxFieldLength)) { Document document1 = new Document(); document1.Add(new Field("id", "1", Field.Store.YES, Field.Index.NOT_ANALYZED)); document1.Add(new Field("age", "30", Field.Store.YES, Field.Index.NOT_ANALYZED)); document1.Add(new Field("text", "刘备", Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_OFFSETS)); writer.AddDocument(document1); Document document2 = new Document(); document2.Add(new Field("id", "2", Field.Store.YES, Field.Index.NOT_ANALYZED)); document2.Add(new Field("age", "25", Field.Store.YES, Field.Index.NOT_ANALYZED)); document2.Add(new Field("text", "关羽", Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_OFFSETS)); writer.AddDocument(document2); } //查找 using (IndexSearcher searcher = new IndexSearcher(directory1)) { Term t = new Term("text", "关"); TermQuery query = new TermQuery(t); QueryScorer qs = new QueryScorer(query); Highlighter hl = new Highlighter(qs); SimpleFragmenter sf = new SimpleFragmenter(100); hl.TextFragmenter = sf; //获得高亮处理后的结果 TopDocs docs = searcher.Search(query, null, 10); for (int i = 0; i < docs.TotalHits; i++) { Document doc = searcher.Doc(docs.ScoreDocs[i].Doc);string[] StrArr = hl.GetBestFragments(analyzer, "text", doc.Get("text"), 3); Console.WriteLine(StrArr[0]); } } Console.ReadKey(); } }
输出如下:
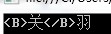
3、高亮处理的基本设置
(1)、如果一篇文档中包含许多个被搜索的关键词,那么可以限定显示出来的关键词数量。通过GetBestFragments()方法重载中的maxNumFragments来设定。
(2)、高亮处理后的结果是一段文本,可以在SimpleFragmenter的构造方法中指定显示给用户的文本长度。
(3)、通常,我们设置含有关键词的文本块之间使用"..."符号来连接。通过GetBestFragments()方法中的separator参数来设定。
(4)、默认情况下,高亮处理是使用"<b></b>"来修饰关键词的。我们可以自定义新的修饰格式。
下面,再举个例子,实现前三个设置。将maxNumFragments设置为2,设定高亮处理后的显示文本长度为60。
using (IndexSearcher searcher = new IndexSearcher(directory1)) { Term t = new Term("text", "关"); TermQuery query = new TermQuery(t); QueryScorer qs = new QueryScorer(query); Highlighter hl = new Highlighter(qs); SimpleFragmenter sf = new SimpleFragmenter(60); //设定一个关键词显示周围的内容长度为60个字符 hl.TextFragmenter = sf; TopDocs docs = searcher.Search(query, null, 10); for (int i = 0; i < docs.TotalHits; i++) { Document doc = searcher.Doc(docs.ScoreDocs[i].Doc); Lucene.Net.Analysis.TokenStream tokenStream = analyzer.TokenStream("text", new System.IO.StringReader(doc.Get("text"))); string Str = hl.GetBestFragments(tokenStream, doc.Get("text"), 2, "!!!"); //显示关键词数为2,分隔符为"!!!" Console.WriteLine(Str); } }
4、为高亮显示设置新的格式
默认情况下,高亮处理是使用"<b></b>"来格式化关键词的。我们可以自定义新的修饰格式。这主要会用到SimpleHTMLFormatter类。
Highlighter(IFormatter formatter, IScorer fragmentScorer);
这个构造方法的第一个参数是IFormatter,也就是“格式器”,即用来格式化高亮文本的工具类。SimpleHTMLFormatter类很适合作为格式器。
(1)SimpleHTMLFormatter()
构造的格式奇使用"<B>"和"</B>"标记来格式化高亮文本。
(2)SimpleHTMLFormatter(string preTag,String postTag)
构造的格式器使用自定义的标记来格式化高亮文本,第一个参数是前标记,第二个参数的后标记。
SimpleHTMLFormatter stf = new SimpleHTMLFormatter("<font style=\"color:red\">","</font>"); Highlighter hl = new Highlighter(stf,qs);
输出效果如下:


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步