


一、索引视图基本概念
索引视图实际上是一种将一组唯一值“物化”为群集索引形式的视图,所为物化就是几乎和表一样,其数据也是会存储一份的(会占用硬盘空间,但是查询速度快,例如可以将count(),sum()等值设在索引视图中)。其优点是它在提取视图背后的信息方面提供了一个非常快的查找方法。在第一个索引(必须是针对一组唯一值的聚集索引)之后,通过使用来自第一个索引的聚集键作为参考点,SQL Server还能在视图上建立额外的索引。其限制如下:
- 视图必须使用SCHEMABINDING选项;
- 如果视图引用了任何用户自定义函数,那么这些函数也必须是模式绑定的;
- 视图不可以引用任何其他的视图-只能引用表和UDF;
- 在视图中引用的所有表和UDF必须采用两部分的命名约定(例如:dbo..Customers),并且也必须具有和视图相同的所有者;
- 视图和视图引用的所有对象必须在相同的数据库中;
- 在创建视图和所有底层表时,必须打开ANSI_NULLS以及QUOTED_IDENTIFIER选项;
- 视图引用的任何函数必须是确定的;
示例:
CREATE VIEW CustomerOrders_vw WITH SCHEMABINDING AS SELECT ....
当创建索引时,在视图上创建的第一个索引必须是聚集的和唯一的:
CREATE UNIQUE CLUSTERED INDEX ivCustomerOrders ON CustomerOrders_vw(AccountNumber,SalesOrderID,ProductID)
一旦执行该命令,就有了视图的群集索引。索引基本和表的一样,也需要维护成本。
二、索引视图作用示例
PersonTenMillion是一张一千万记录的表,下面我们来执行如下SQL语句:
SELECT Age,COUNT(Age) FROM PersonTenMillion GROUP BY Age ORDER BY Age
对一张1千万记录的表进行分组计算每个年龄的认输,你可以想象到需要花费的时间了。
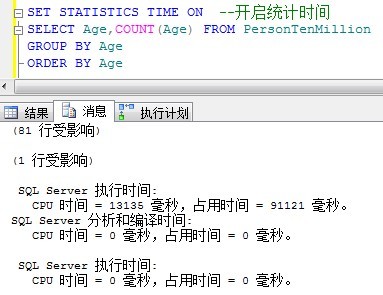
1分31秒,这种查询语句如果在网页上面,页面已经显示页面无法响应了。
下面我们来优化上面这个查询,我们创建一个索引视图如下:
--创建模式绑定视图 CREATE VIEW PersonAge_vw WITH SCHEMABINDING AS SELECT Age,COUNT_BIG(*) AS CountAge FROM dbo.PersonTenMillion GROUP BY Age --为视图创建索引 CREATE UNIQUE CLUSTERED INDEX ivPersonAge ON PersonAge_vw(Age)
这次我们从索引视图上获取数据:
SELECT * FROM PersonAge_vw
这次是瞬间出来的,因为只是相当于从一个81行的表中使用聚集索引分那会81行数据:
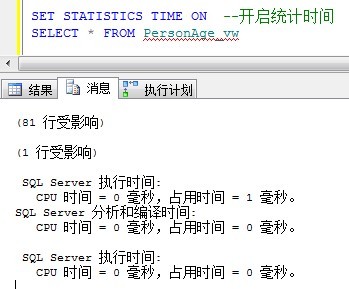
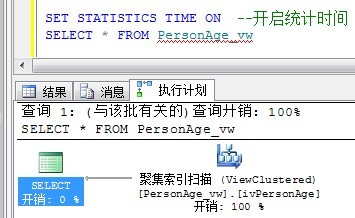
查询速度快了好多好多,但这以为这索引视图是好的选择吗?不是的,这只意味着它可能是。和任何索引一样,需要记住索引的维护成本。维护该索引将会使对底层表的INSERT、UPDATE和DELETE语句的执行速度减慢多少?这必须考虑进去,这是个平衡问题,要视每个表和每个索引而定。尽管如此,索引视图还是一种较强大的工具,因此作仔细地权衡。

