hadoop集群搭建
前置条件:JDK安装,JAVA_HOME配置。
1. 下载
wget https://dist.apache.org/repos/dist/release/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
2. 解压
配置hadoop home
vim /etc/profile export HADOOP_HOME=/xxx/soft/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin
3. 配置ssh免密登陆
/etc/hosts
vim /etc/hosts 10.112.29.9 master 10.112.29.10 slave1 10.112.28.237 slave2
ssh-keygen -t RSA
ssh-copy-id master ssh-copy-id slave1 ssh-copy-id slave2
同时将/etc/hosts内容scp至slave1,slave2。
注意:master 本机需要添加本机的ssh免密信任。否则后面namenode 启动不成功。
4. 配置hadoop
./etc/hadoop/hadoop-env.sh JAVA_HOME配置一下全路径
vim ./etc/hadoop/hadoop-env.sh export JAVA_HOME=......./soft/java
...hadoop-2.7.3/etc/hadoop/core-site.xml
vim ./etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/xxx/soft/hadoop-2.7.3/tmp</value>
</property>
</configuration>
..../etc/hadoop/hdfs-site.xml
vim ./etc/hadoop/hdfs-site.xml
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/xxx/soft/hadoop-2.7.3/tmp/name</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/xxx/soft/hadoop-2.7.3/tmp/data</value>
</property>
</configuration>
..../etc/hadoop/mapred-site.xml
mv ./etc/mapred-site.xml.template ./etc/mapred-site.xml
vim ./etc/hadoop/mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
...../etc/hadoop/yarn-site.xml
vim ./etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
创建masters文件
vim ./etc/hadoop/masters slave1
修改slaves文件
vim ./etc/hadoop/slaves slave1 slave2
5. 拷贝 /xxx/soft/hadoop-2.7.3至slaves
scp -r /xxx/soft/hadoop-2.7.3 slave1:/xxx/soft/ scp -r /xxx/soft/hadoop-2.7.3 slave2:/xxx/soft/
6. 启动
./bin/hdfs namenode -format ./sbin/start-dfs.sh ./sbin/start-yarn.sh
7. 查看进程
master: [root@vm-10-112-29-9 hadoop-2.7.3]# jps 14897 ResourceManager 14568 NameNode 16058 Jps slave1: [root@vm-10-112-29-10 hadoop-2.7.3]# jps 1522 SecondaryNameNode 2708 Jps 1628 NodeManager 1405 DataNode slave2: [root@vm-10-112-28-237 hadoop-2.7.3]# jps 1799 DataNode 2876 Jps 1935 NodeManager
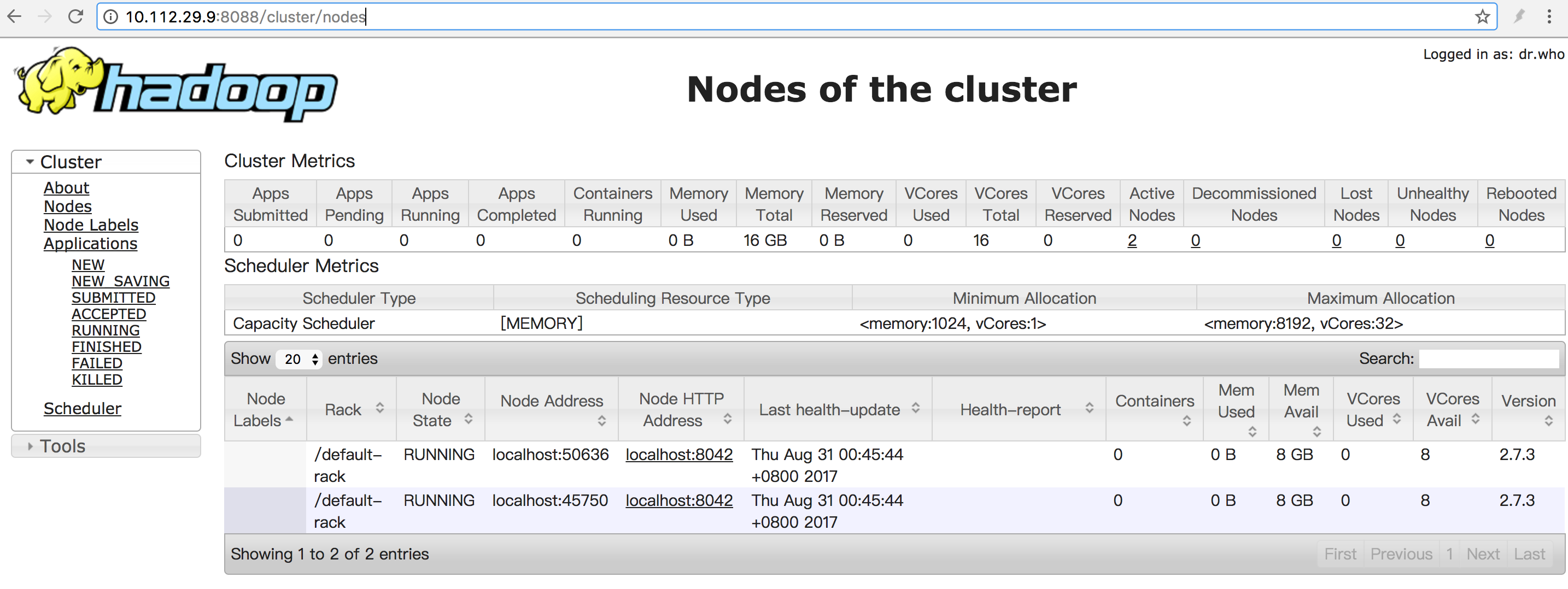
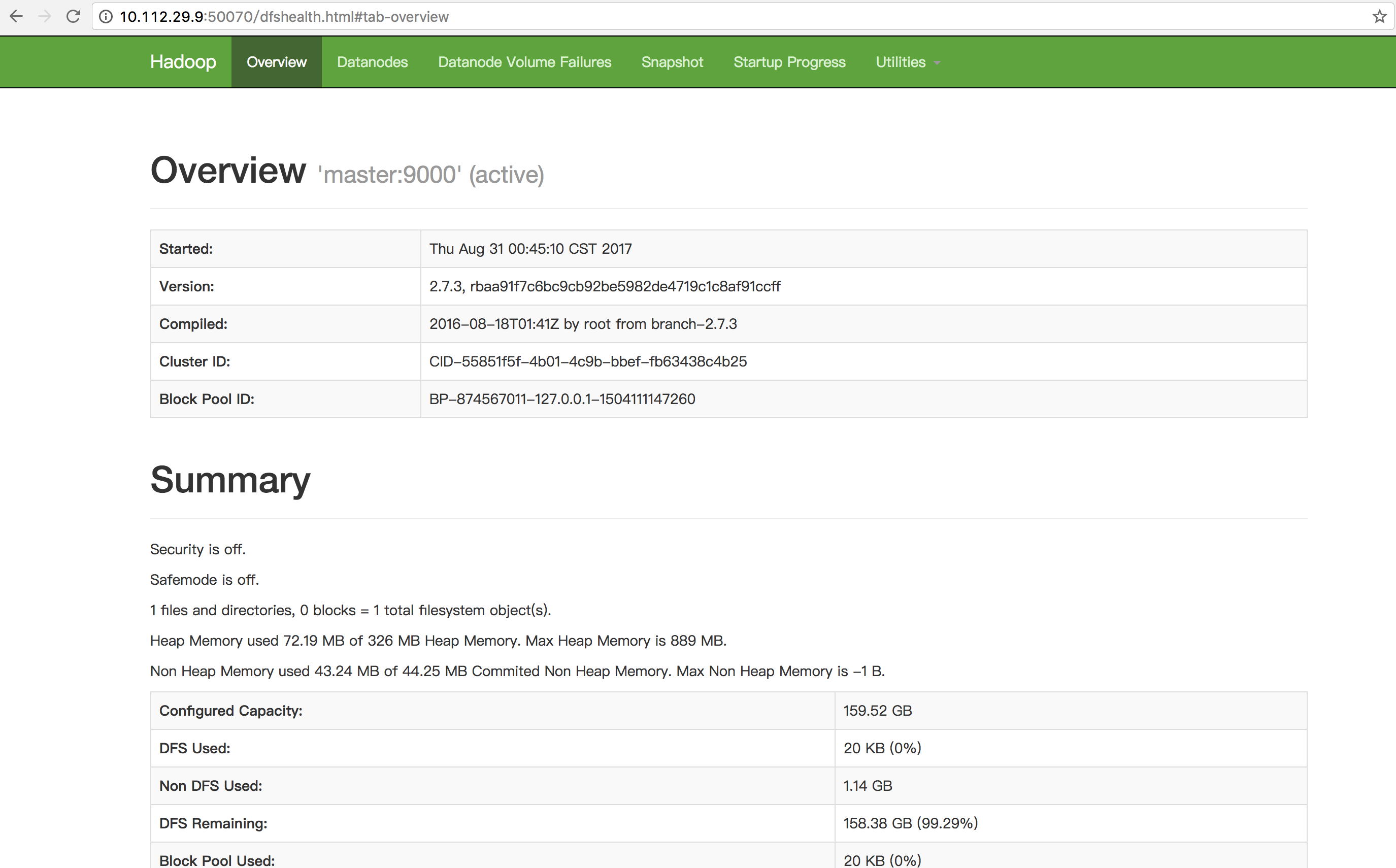
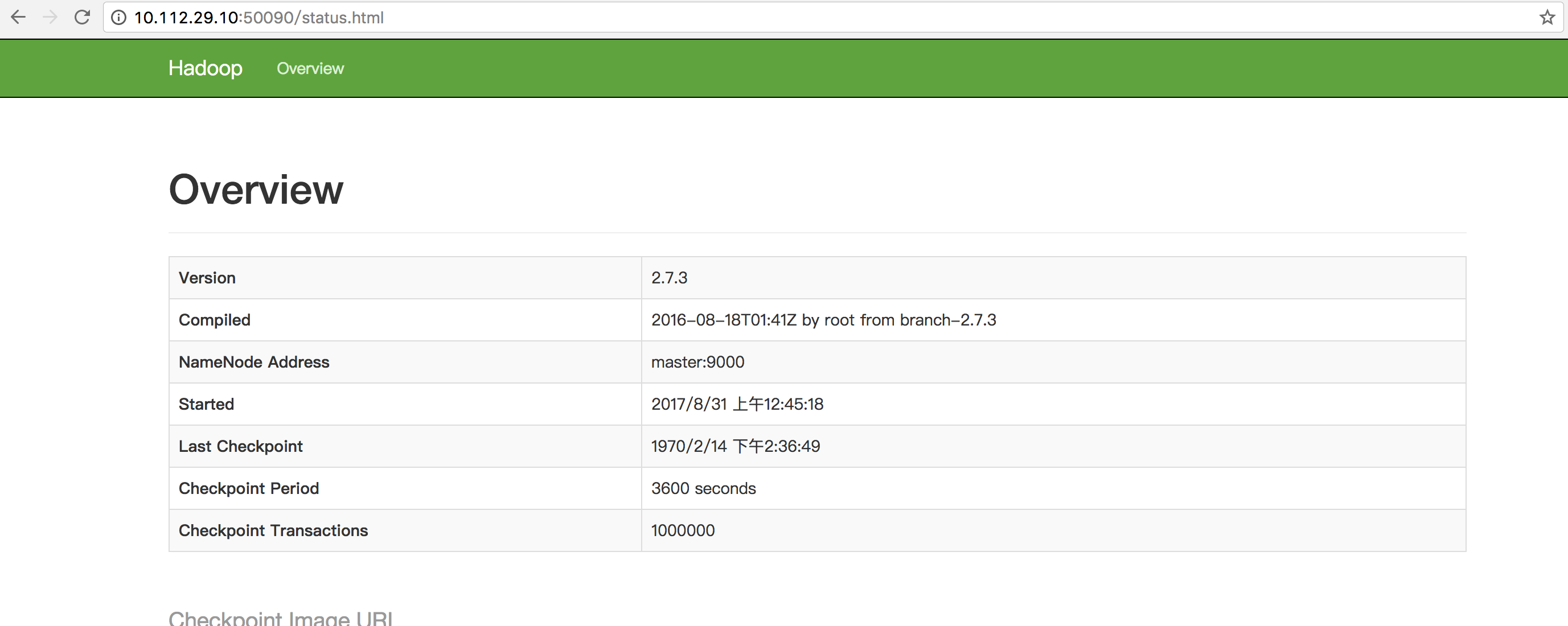
8. 访问
http://10.112.29.9:8088/ http://10.112.29.9:50070/ http://10.112.29.10:50090/