浏览器专题之缓存url请求
1)背景:首先科谱下get与post的区别
get请求
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
post请求
- POST 请求不会被缓存
- POST 请求不会保留在浏览器历史记录中
- POST 不能被收藏为书签
- POST 请求对数据长度没有要求
2) 除了上面的,还要说明下根据HTTP规范,GET是用于信息获取的,而且是幂等的,也就是说,当使用相同的URL重复GET请求会返回预期的相同结果时,GET方法才是适用的;POST更多的作用是修改服务器的信息状态(比如用户注册,数据库要进行操作等),也就是说POST请求是有副作用的。对于GET请求的幂等性,有的浏览器会默认将url相同的GET请求做缓存处理(来自参考链接(1)),比如IE就会进行缓存
IE情况

3)不同的浏览对于相同的get请求所采取的措施也不大一样,有的浏览器会阻塞相同url的get请求(相同时间发出的请求),直到当前的get请求完成,而post则不会有此种情况。
chrome情况
发送中阻塞
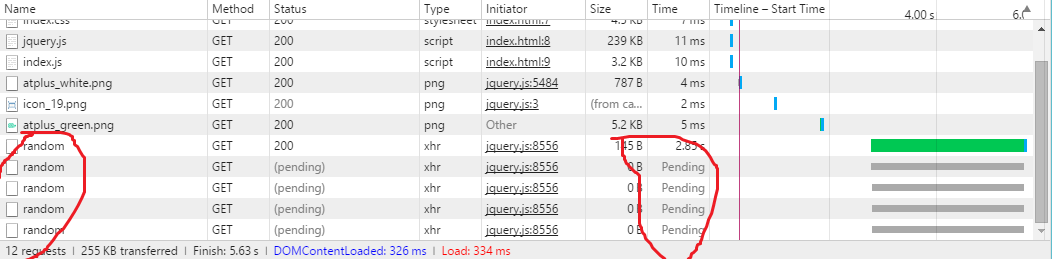
请求并获取了数据(关键看数据的请求起始终止时间 )

那么如何解决上述的get请求下因为相同url下缓存和阻塞的问题
1)GET时,在url后面加上随机数(比如时间new Date().getTime()),让浏览器认为是不同的资源,而不被缓存或阻塞

2)在服务端加上header来指令浏览器不要缓存
相关的报文头设置为{'Content-Type': 'text/plain', "Cache-Control":"no-cache, no-store, must-revalidate"}
3)使用post进行请求
测试代码:https://github.com/sysuKinthon/Web2.0/tree/master/Web2.0/menuCalculate/S3
