Hive安装与配置
1.什么是hive
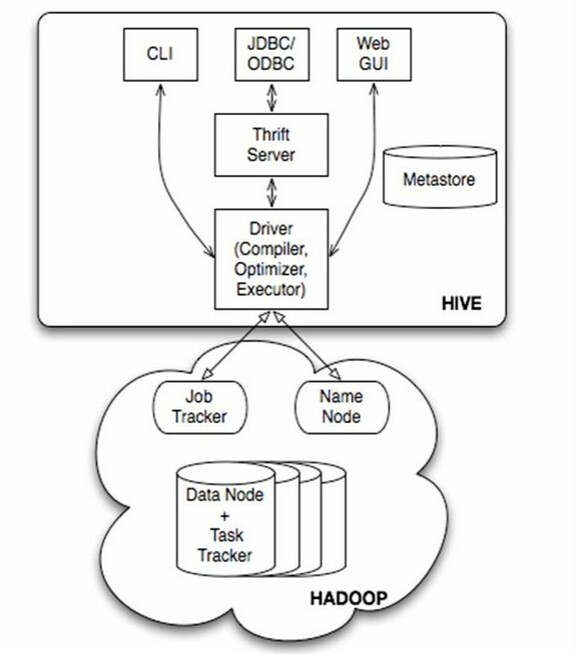
Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
2. Hive安装与配置
2.1 下载hive安装文件
可以从Apache官网下载安装文件,即 http://mirror.bit.edu.cn/apache/hive/
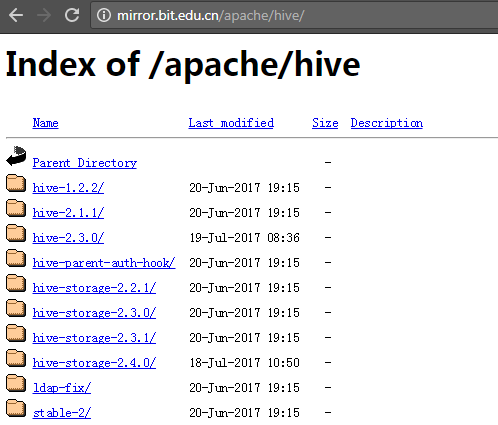
也可以从我的云盘下载 <apache-hive-2.1.0-bin.tar.gz> 链接是:https://pan.baidu.com/s/1i5mTBEH 密码是:xbf
除此之外,由于hive是默认将元数据保存在本地内嵌的 Derby 数据库中,但是这种做法缺点也很明显,Derby不支持多会话连接,因此本文将选择mysql作为元数据存储。
需要下载mysql的jdbc<mysql-connector-java-5.1.28.jar>,然后将下载后的jdbc放到hive安装包的lib目录下, 下载链接是:http://dev.mysql.com/downloads/connector/j/ ,也可以从上述云盘中获取。
2.2 安装mysql来替换默认的Derby数据库
请参考 Hive集成mysql数据库
2.3 修改配置文件
解压安装文件到指定的的文件夹 /opt/hive
tar -zxf apache-hive-2.1.0-bin.tar.gz -C opt/hive
2.3.1 设置环境变量
vi /etc/profile

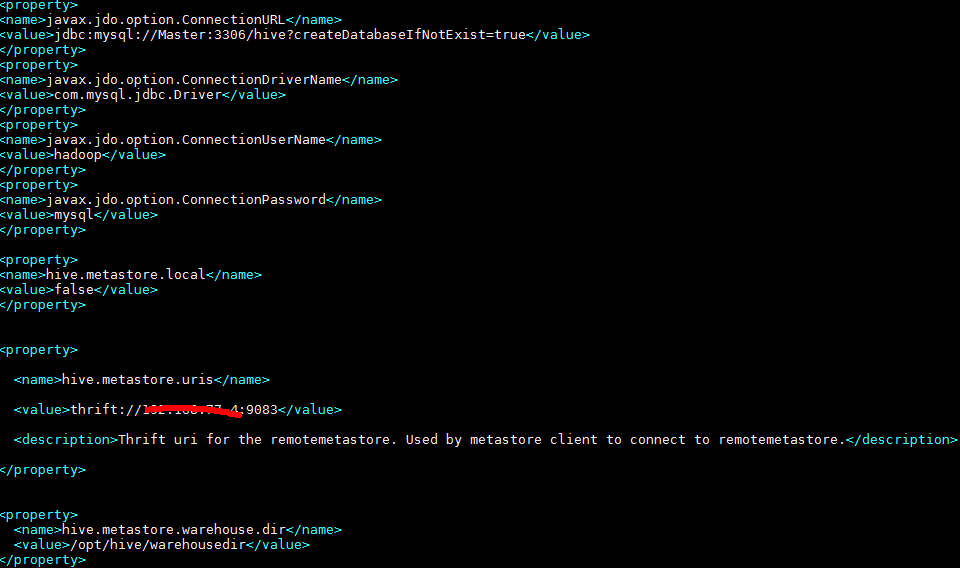
2.3.2 修改hive-site.xml文件
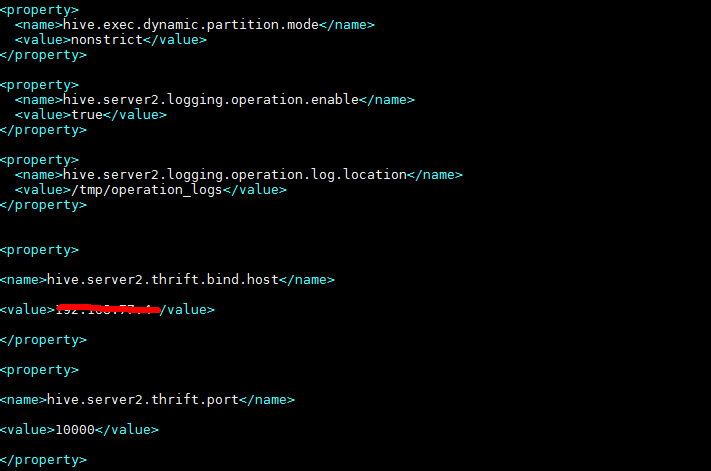
2.3.3 修改hive-env.sh
cp hive-env.sh.template hive-env.sh
vi hive-env.sh

2.4 运行hive
运行hive之前首先要确保meta store服务已经启动,
nohup hive --service metastore > metastore.log 2>&1 &
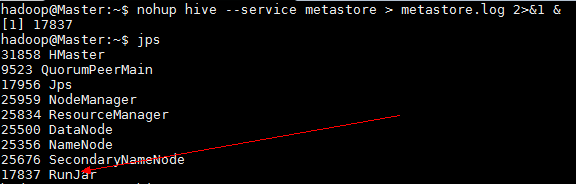
如果需要用到远程客户端(比如 Tableau)连接到hive数据库,还需要启动hive service
nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &
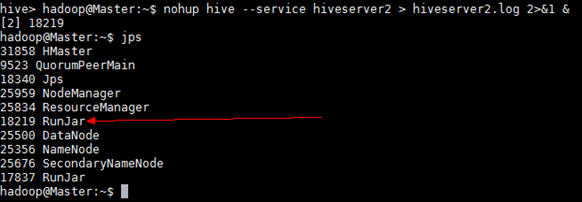
然后由于配置过环境变量,可以直接在命令行中输入hive

2.5 测试hive是否可以正确使用
2.5.1 创建测试表dep
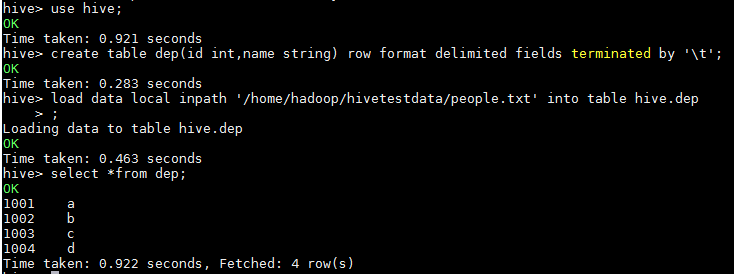
2.5.2 通过Mysql查看创建的表
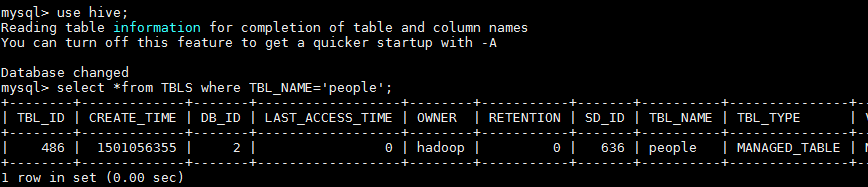
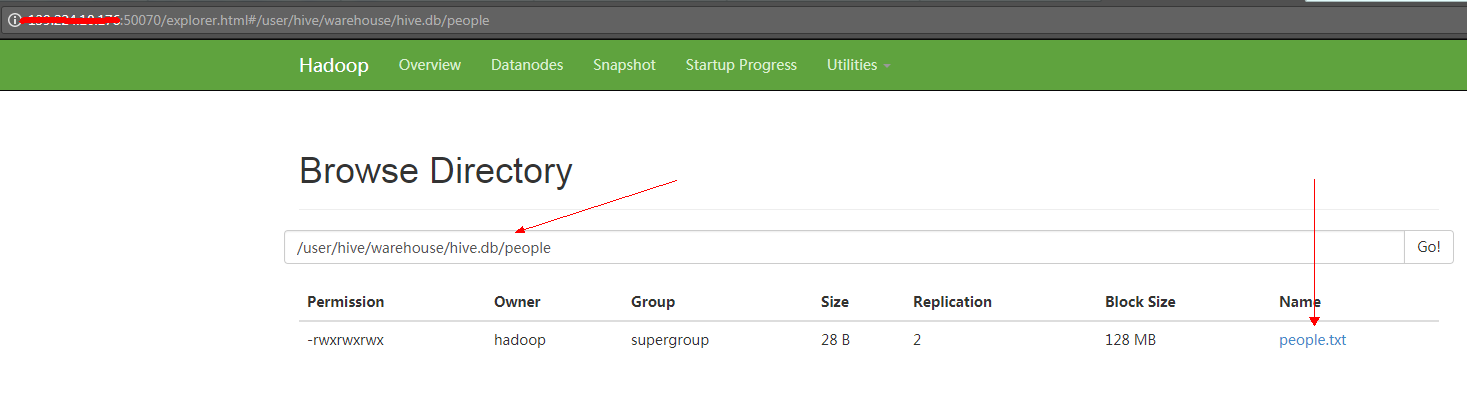
2.5.3 通过UI页面查看创建的数据位
访问 xxx.xxx.xxx.xxx:50070