
HMM MEMM & label bias
(http://blog.csdn.net/xum2008/article/details/38147425)
隐马尔科夫模型(HMM):
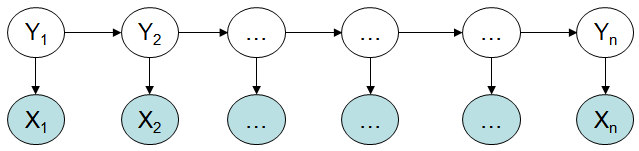
图1. 隐马尔科夫模型
隐马尔科夫模型的缺点:
1、HMM只依赖于每一个状态和它对应的观察对象:
序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。
2、目标函数和预测目标函数不匹配:
HMM学到的是状态和观察序列的联合分布P(Y,X),而预测问题中,我们需要的是条件概率P(Y|X)。
最大熵隐马尔科夫模型(MEMM):
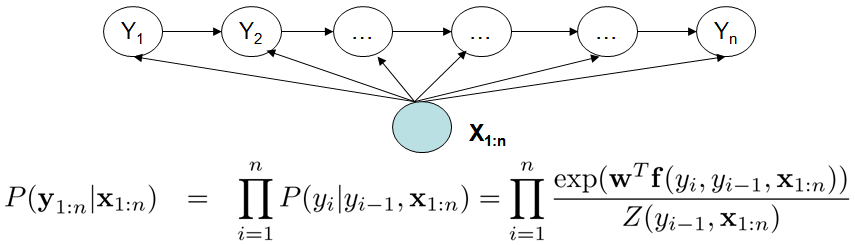
图2. 最大熵马尔科夫模型
MEMM考虑到相邻状态之间依赖关系,且考虑整个观察序列,因此MEMM的表达能力更强;MEMM不考虑P(X)减轻了建模的负担,同时学到的是目标函数是和预测函数一致。
MEMM的标记偏置问题:
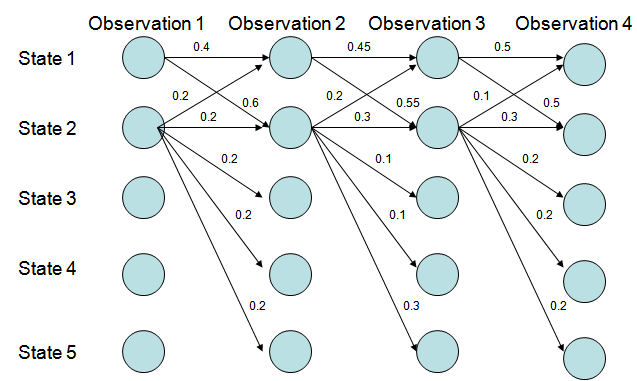
图3. Viterbi算法解码MEMM,状态1倾向于转换到状态2,同时状态2倾向于保留在状态2;
P(1-> 1-> 1-> 1)= 0.4 x 0.45 x 0.5 = 0.09 ,P(2->2->2->2)= 0.2 X 0.3 X 0.3 = 0.018,
P(1->2->1->2)= 0.6 X 0.2 X 0.5 = 0.06,P(1->1->2->2)= 0.4 X 0.55 X 0.3 = 0.066。
图3中状态1倾向于转换到状态2,同时状态2倾向于保留在状态2;但是得到的最优的状态转换路径是1->1->1->1,为什么呢?因为状态2可以转换的状态比状态1要多,从而使转移概率降低;即MEMM倾向于选择拥有更少转移的状态。这就是标记偏置问题。而CRF很好地解决了标记偏置问题。
MEMM是局部归一化,CRF是全局归一化
另一方面,MEMMs不可能找到相应的参数满足以下这种分布:
a b c --> a/A b/B c/C p(A B C | a b c) = 1
a b e --> a/A b/D e/E p(A D E | a b e) = 1
p(A|a)p(B|b,A)p(C|c,B) = 1
p(A|a)p(D|b,A)p(E|e,D) = 1
但是CRFs可以找到模型满足这种分布。
我喜欢程序员,他们单纯、固执、容易体会到成就感;面对困难,能够不休不眠;面对压力,能够迎接挑战。他们也会感到困惑与傍徨,但每个程序员的心中都有一个比尔盖茨或是乔布斯的梦想,用智慧把属于自己的事业开创。其实我是一个程序员[=.=]

