

SQL SERVER 中is null 和 is not null 将会导致索引失效吗?
2015-06-04 00:01 潇湘隐者 阅读(44471) 评论(17) 编辑 收藏 举报其实本来这个问题没有什么好说的,今天优化的时候遇到一个SQL语句,因为比较有意思,所以我截取、简化了SQL语句,演示给大家看,如下所示
declare @bamboo_Code varchar(3);
set @bamboo_Code='-01';
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH ( nolock )
WHERE RIGHT(ges_no, 3) = @bamboo_Code
AND Isnull(yarn_lot, '') <> '';
如上所示,SQL中对列yarn_log 使用了Isnull(yarn_lot, '') <> ''这种写法,我估计书写该SQL语句的人应该是深信了“is null 和 is not null 将会导致索引失效”这条网上流传的教条, 至于这个建议是从哪里流传开来,已经无法考证。 那么我们通过实践来验证一下is null 或 is not null 是否会导致索引失效。
表rsjob是一个堆表,在列yarn_lot上建有索引yarn_lot.那么我们通过实验来验证吧
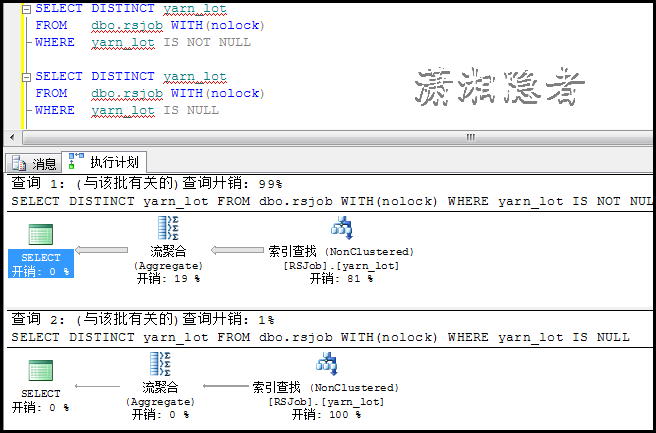
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH(nolock)
WHERE yarn_lot IS NOT NULL;
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH(nolock)
WHERE yarn_lot IS NULL

如上所示,不管是IS NULL 或IS NOT NULL都走了索引查找。
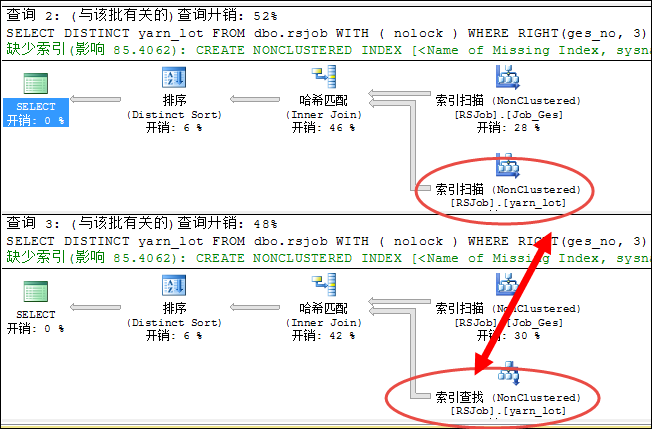
declare @bamboo_Code varchar(3);
set @bamboo_Code='-01';
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH ( nolock )
WHERE RIGHT(ges_no, 3) = @bamboo_Code
AND Isnull(yarn_lot, '') <> '';
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH ( nolock )
WHERE RIGHT(ges_no, 3) = @bamboo_Code
AND yarn_lot IS NOT NULL;
另外我们来看看这两个原始SQL执行计划的开销比值为52:48, 也就是说使用IS NOT NULL性能更好,第一个SQL语句由于做了转换,导致其走索引扫描,而使用IS NOT NULL则走索引查找。
![clipboard[26]](http://images0.cnblogs.com/blog/73542/201506/101443410191969.png "clipboard[26]")
“is null 和 is not null 将会导致索引失效”这种坑人教条直接被推翻了。所以还在信奉这个教条的人真应该自己动手验证一下。
下面我们可以通过实验验证一下,考虑到在真实环境中,可能情况比较复杂。我们可以构建下面几个场景。其实真实环境中情况还会复杂一些。但是基本上大致有如下一些场景
情况1:堆表 谓词上单独索引列
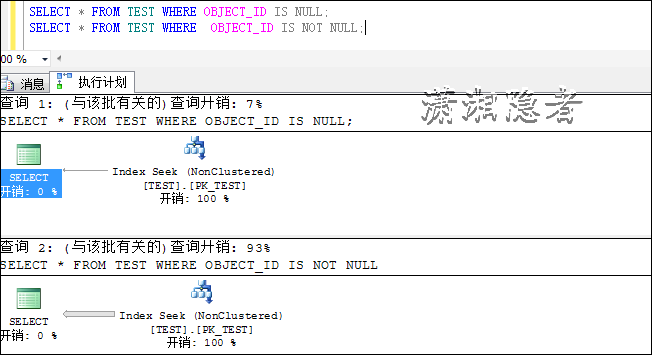
USE Test;GODROP TABLE TEST;
GOCREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12));
CREATE INDEX PK_TEST ON TEST(OBJECT_ID) INCLUDE(NAME);
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN INSERT INTO TESTSELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR);
SET @Index = @Index +1;
ENDINSERT INTO TESTSELECT NULL, 'only test1' UNION ALL
SELECT NULL, 'only test2'
UPDATE STATISTICS TEST WITH FULLSCAN;
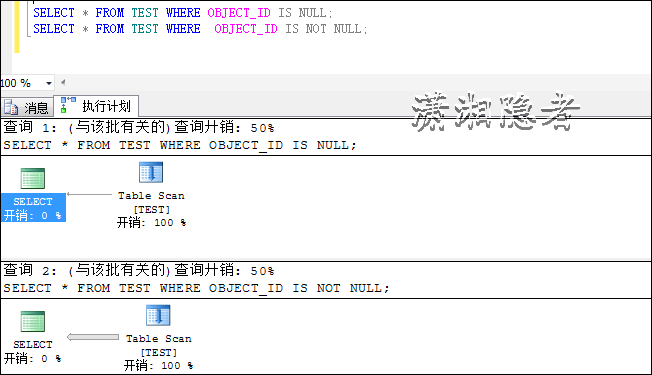
SELECT * FROM TEST WHERE OBJECT_ID IS NULL;
SELECT * FROM TEST WHERE OBJECT_ID IS NOT NULL;
![clipboard[1]](http://images0.cnblogs.com/blog/73542/201506/101443419739810.png "clipboard[1]")
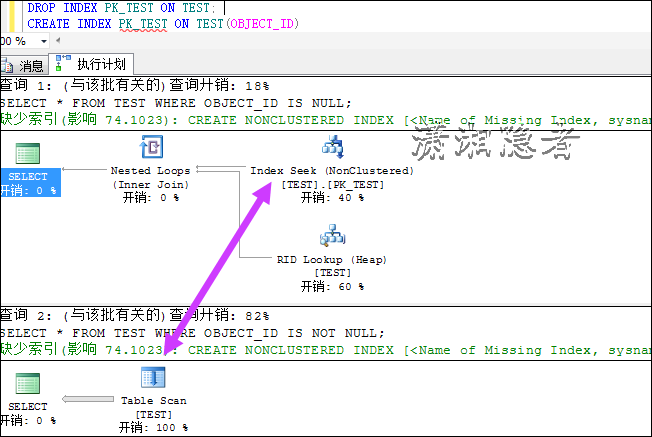
删除索引,建立如下索引。如下所示
DROP INDEX PK_TEST ON TEST;
CREATE INDEX PK_TEST ON TEST(OBJECT_ID)
![clipboard[2]](http://images0.cnblogs.com/blog/73542/201506/101443430199624.png "clipboard[2]")
由此可见IS NULL 或IS NOT NULL的执行计划即与索引有关系,还跟数据分布有一定关系。
情况2:堆表 谓词上无索引
USE Test;GODROP TABLE TEST;
GOCREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12));
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN INSERT INTO TESTSELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR);
SET @Index = @Index +1;
ENDINSERT INTO TESTSELECT NULL, 'only test1' UNION ALL
SELECT NULL, 'only test2'
UPDATE STATISTICS TEST WITH FULLSCAN;
SELECT * FROM TEST WHERE OBJECT_ID IS NULL;
SELECT * FROM TEST WHERE OBJECT_ID IS NOT NULL;
![clipboard[3]](http://images0.cnblogs.com/blog/73542/201506/101443442234923.png "clipboard[3]")
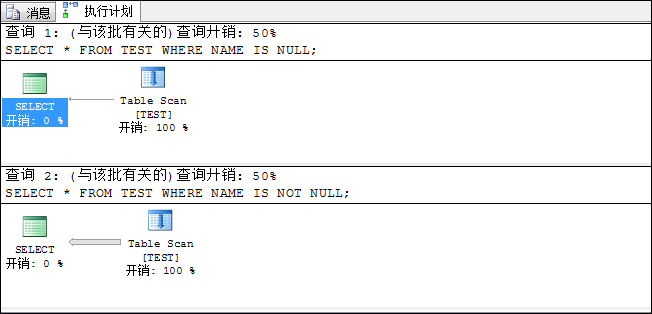
如上所示,如果一个堆表没有建立任何索引,那么使用IS NULL 或IS NOT NULL肯定要走全表扫描,不过这不在我们的讨论范围之内。然后我们看看将索引建立在其它字段上(主要是为了与聚集索引表对比),它依然全表扫描。
CREATE INDEX PK_TEST ON TEST(OBJECT_ID) INCLUDE(NAME);
INSERT INTO TESTSELECT 10000, NULL UNION ALL
SELECT 10001, NULL ;
SELECT * FROM TEST WHERE NAME IS NULL;
SELECT * FROM TEST WHERE NAME IS NOT NULL;
![clipboard[4]](http://images0.cnblogs.com/blog/73542/201506/101443452541508.png "clipboard[4]")
情况3:堆表 联合索引列
USE Test;GODROP TABLE TEST;
GOCREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12), AGE INT);
CREATE INDEX IDX_TEST_N1 ON TEST(NAME, AGE);
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN INSERT INTO TESTSELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR), floor(rand()*100) ;
SET @Index = @Index +1;
ENDINSERT INTO TESTSELECT NULL, 'only test1', 12 UNION ALL
SELECT NULL, 'only test2',24
UPDATE STATISTICS TEST WITH FULLSCAN;
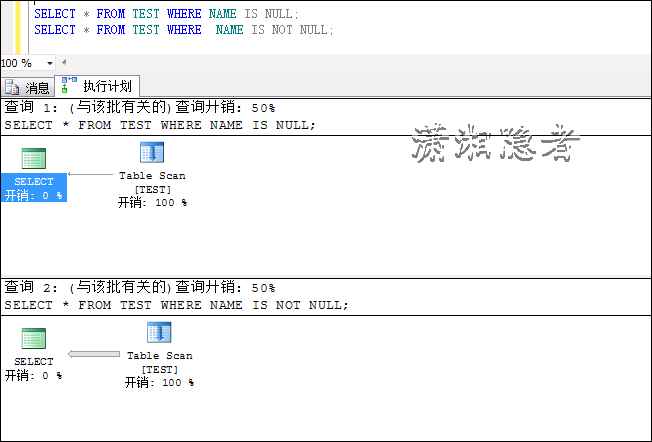
SELECT * FROM TEST WHERE NAME IS NULL;
SELECT * FROM TEST WHERE NAME IS NOT NULL;
![clipboard[5]](http://images0.cnblogs.com/blog/73542/201506/101443463942294.png "clipboard[5]")
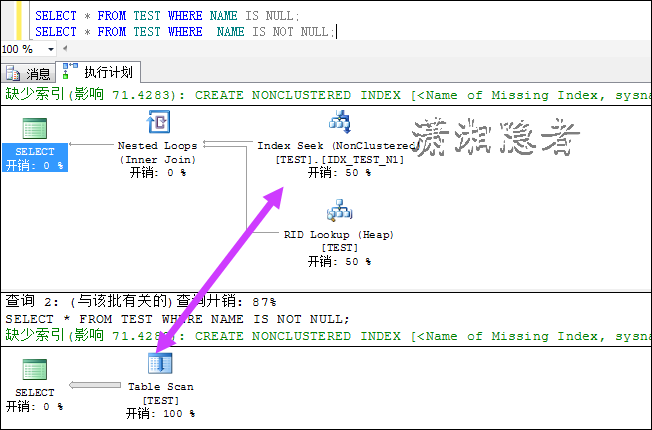
如果联合索引中,谓词位于联合索引的第二或更后位置,那么又是什么情况? 从下面我们可以看到,SQL走全表扫描了。
DROP INDEX IDX_TEST_N1 ON TEST;
CREATE INDEX IDX_TEST_N1 ON TEST( AGE,NAME);
UPDATE STATISTICS TEST WITH FULLSCAN;
![clipboard[6]](http://images0.cnblogs.com/blog/73542/201506/101443478794806.png "clipboard[6]")
4 聚集索引表 单独索引列
USE Test;GODROP TABLE TEST;
GOCREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12));
CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID)
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN INSERT INTO TESTSELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR);
SET @Index = @Index +1;
ENDINSERT INTO TESTSELECT NULL, 'only test1' UNION ALL
SELECT NULL, 'only test2'
SELECT * FROM TEST WHERE OBJECT_ID IS NULL;
SELECT * FROM TEST WHERE OBJECT_ID IS NOT NULL;
![clipboard[7]](http://images0.cnblogs.com/blog/73542/201506/101443493167034.png "clipboard[7]")
如果我在列NAME上面使用IS NULL 或IS NOT NULL进行查询,你会发现执行计划从聚集索引查找变为了聚集索引扫描。
INSERT INTO TEST SELECT 10000, NULL UNION ALL
SELECT 10001, NULL ;
SELECT * FROM TEST WHERE NAME IS NULL;
SELECT * FROM TEST WHERE NAME IS NOT NULL;
![clipboard[8]](http://images0.cnblogs.com/blog/73542/201506/101443509738261.png "clipboard[8]")
4 聚集索引表 联合索引列
USE Test;GODROP TABLE TEST;
GOCREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12), AGE INT);
CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID)
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN INSERT INTO TESTSELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR), floor(rand()*100) ;
SET @Index = @Index +1;
ENDINSERT INTO TESTSELECT 10001, 'NULL', 12 UNION ALL
SELECT 10002, 'NULL',24
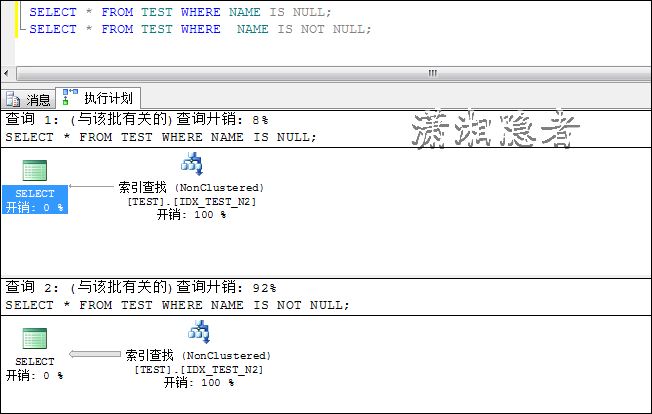
CREATE INDEX IDX_TEST_N2 ON TEST(NAME,AGE);
UPDATE STATISTICS TEST WITH FULLSCAN;
![clipboard[9]](http://images0.cnblogs.com/blog/73542/201506/101443520519831.png "clipboard[9]")
如果联合索引中,谓词位于不位于第一列,那么IS NULL 或IS NOT NULL有会不会走索引呢?
DROP INDEX IDX_TEST_N2 ON TEST;
CREATE INDEX IDX_TEST_N2 ON TEST(AGE,NAME);
UPDATE STATISTICS TEST WITH FULLSCAN;
![clipboard[10]](http://images0.cnblogs.com/blog/73542/201506/101443533486102.png "clipboard[10]")
如上所示,它从索引查找变成索引扫描了。
小结: 1:“is null 和 is not null 将会导致索引失效”这种教条完全是狗屎,SQL Server的索引是包含了null 值,而Oracle的索引是不包含null值的。不同数据库情况有所不同,不要生搬硬套。
2:如果谓词上面建立有索引的话,基本上都会走索引,至于是走索引查找还是索引扫描与索引类型有一定关系,也与字段位于联合索引中位置有关系。另外,数据分布倾斜得非常厉害也会导致其走全表扫描而不走索引,但是这并不是说IS NULL 和 IS NOT NULL导致索引失效。有一点非常重要,通过观察SQL语句而推断执行计划是很不现实的,需要综合考察SQL语句所涉及表的索引、数据分布、统计信息,才能综合判断,用通俗的话来说要结合具体场景。



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}