
浅析SQL SERVER执行计划中的各类怪相
2014-07-11 15:30 潇湘隐者 阅读(5475) 评论(10) 收藏 举报在查看执行计划或调优过程中,执行计划里面有些现象总会让人有些疑惑不解:
1:为什么同一条SQL语句有时候会走索引查找,有时候SQL脚本又不走索引查找,反而走全表扫描?
2:同一条SQL语句,查询条件的取值不同,它的执行计划会一致吗?
3: 同一条SQL语句,其执行计划会变化,为什么
4: 在查询条件的某个或几个字段上创建了索引,执行计划就一定会走该索引吗?
5:同时存在几个索引,SQL语句会走那个索引?
............................................................
有时候如果要跟别人解释清楚这些问题,如果不通过一些案例或例子来解说,很难阐述清楚,一方面是表达能力问题。另外一方面,再华丽的语言也难敌眼见为实,毕竟人接受信息大部分通过眼睛,小部分通过耳朵。眼见为实耳听为虚吗!
下面来看一个简单的例子,为什么我在对应的查询字段上建有索引,但是它不走索引反而走全表扫描。
DROP TABLE TEST
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(8));
CREATE INDEX PK_TEST ON TEST(OBJECT_ID)
DECLARE @Index INT =0;
WHILE @Index < 20
BEGIN INSERT INTO TESTSELECT @Index, 'kerry';
SET @Index = @Index +1;
ENDUPDATE STATISTICS TEST WITH FULLSCAN
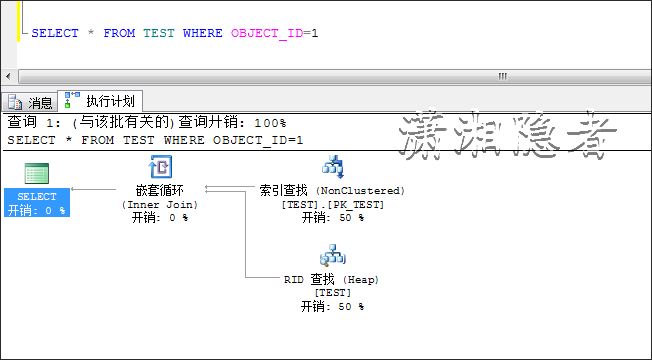
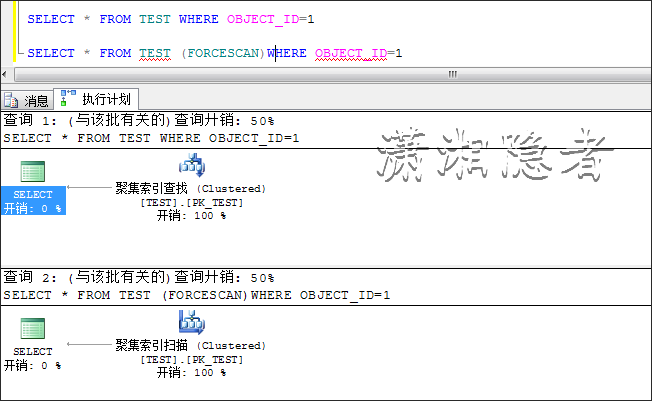
SELECT * FROM TEST WHERE OBJECT_ID=1

已经在查询字段OBJECT_ID上建立了索引,为什么SQL优化器不走索引,而要走全表扫描呢?为了说明白,那么我们借助于查询提示(Hints)强制优化器走索引查找来说明上述情况,对比走索引查找、全表扫描两者的代价开销,从下图,我们可以看到当前情况下,走全表扫描的开销要小于索引查找。因为当前情况下,走索引需要额外的IO开销,反而不如全表扫描。所以优化器选择了走全表扫描而非索引查找。很多开发人员有种根深蒂固的固执观念“走索引查找一定要优于全表扫描”(我跟他们解释的时候,很多人不相信,"慷慨激昂"的质疑我,以至于我的解释都显得苍白无力),大多数情况下,走索引查找要优于全表扫描,但是在特定的场景、特定数据情况下,会出现全表扫描优于索引查找的情况。尤其是ORACLE里面,很多做开发的同事一看到SQL执行计划走全表扫描,立马大呼小叫。其实完全是先入为主的观念作怪。
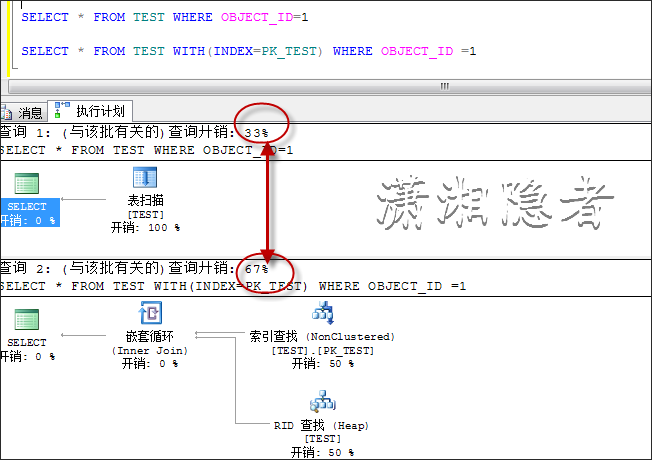
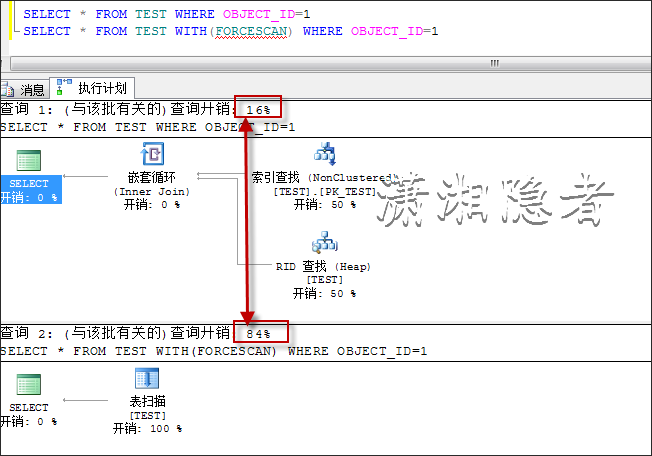
SELECT * FROM TEST WHERE OBJECT_ID=1
SELECT * FROM TEST WITH(INDEX=PK_TEST) WHERE OBJECT_ID =1

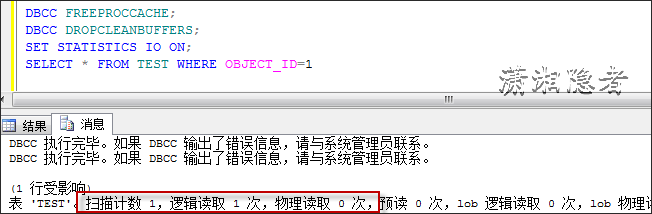
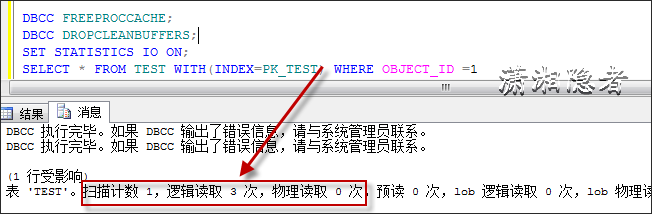
两者开销不一致,其实在IO开销这一块,可以从下面看出逻辑读取的差异。
DBCC FREEPROCCACHE;DBCC DROPCLEANBUFFERS;SET STATISTICS IO ON;
SELECT * FROM TEST WHERE OBJECT_ID=1

DBCC FREEPROCCACHE;DBCC DROPCLEANBUFFERS;SET STATISTICS IO ON;
SELECT * FROM TEST WITH(INDEX=PK_TEST) WHERE OBJECT_ID =1

那么接下来,我们将该表的数据从20条记录增长到10000条记录,你觉得执行计划会变化吗?大家不妨先思考一下这个问题,再看下文。
TRUNCATE TABLE TEST;
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN INSERT INTO TESTSELECT @Index, 'kerry';
SET @Index = @Index +1;
ENDUPDATE STATISTICS TEST WITH FULLSCAN
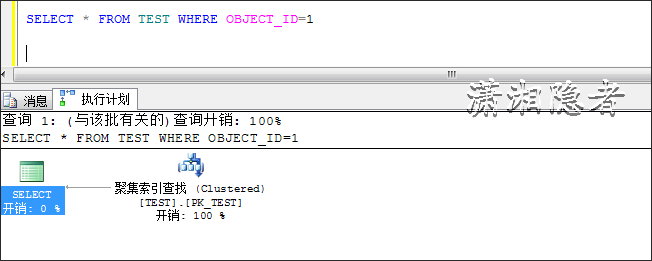
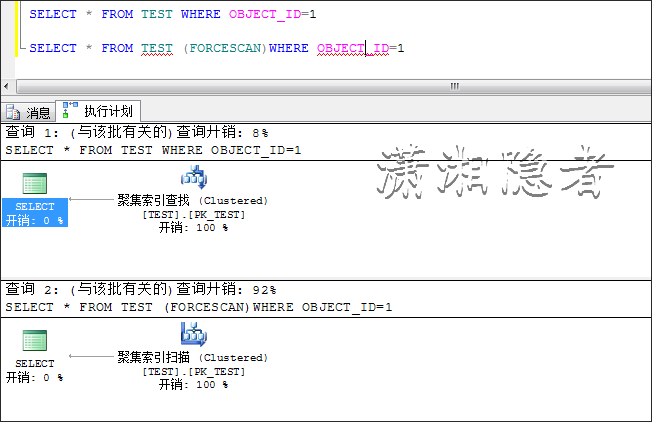
SELECT * FROM TEST WHERE OBJECT_ID=1
如下所示,当数据变化时,优化器认为走索引查找要优于全表扫描,所以选择了索引查找,说到底优化器是基于成本的优化器,在众多的执行计划中,它会选择代价开销最小的一个执行计划。

此时,强制优化器走全表扫描,对比开销结果,你会发现结果完全跟上面结果相反。

我如果更新该表数据,使其分布完全倾斜,那么你可以看到对于同一个SQL,不同的取值,它的执行计划也会完全不同。
UPDATE TEST SET OBJECT_ID =1 WHERE OBJECT_ID<9999
UPDATE STATISTICS TEST WITH FULLSCAN
SELECT OBJECT_ID,COUNT(1) SUM_COUNT FROM TEST GROUP BY OBJECT_ID
OBJECT_ID SUM_COUNT
----------- -----------1 9999
9999 1
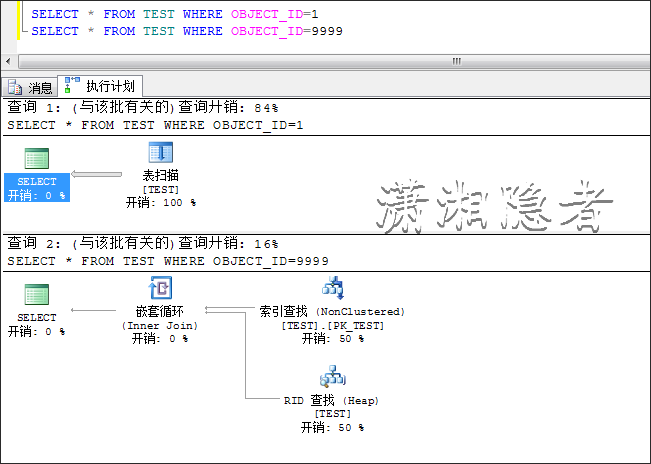
SELECT * FROM TEST WHERE OBJECT_ID=1
SELECT * FROM TEST WHERE OBJECT_ID=9999

可见同一条SQL语句,查询条件的取值不同,它的执行计划可能会不一样。
这几个例子,其实我想说的是执行计划往往会受数据变化的、数据分布(直方图)的影响,在统计信息正确的情况下,优化器会根据代价来判断选取最优的执行计划。前提是统计信息准确。在调优过程中,有时候遇到统计信息不正确导致执行计划很差的情况。我没有想到一个好的例子来让大家形象观察统计信息的不正确性导致执行计划的不同。在此不做详细讨论。
也许细心的朋友已经发现了我上面测试用例使用的是非聚集索引,也就是说该表是一个堆表。如果我创建的索引是聚集索引,情况会怎么样?如下所示,聚集索引下的执行计划跟非聚集索引情况又不一样。
DROP TABLE TEST;
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(8));
CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID)
DECLARE @Index INT =0;
WHILE @Index < 20
BEGIN INSERT INTO TESTSELECT @Index, 'kerry';
SET @Index = @Index +1;
ENDUPDATE STATISTICS TEST WITH FULLSCAN;

如下所示,这种情况下走聚集索引查找与聚集索引扫描的开销几乎接近。

若果我将数据增长到10000条记录后,情况又不同。这是一个显而易见的结果,仅仅为了说明数据对执行计划的影响。

下面我们删除TEST表, 新建另外一个TEST表, 如下所示
DROP TABLE TEST;
SELECT * INTO TEST FROM sys.objects
(2014 行受影响)
CREATE INDEX IDX_TEST_N1 ON TEST(CREATE_DATE, TYPE);
UPDATE STATISTICS TEST WITH FULLSCAN;
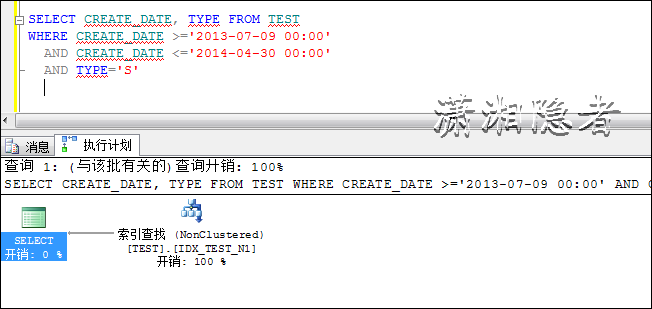
SELECT CREATE_DATE, TYPE FROM TEST
WHERE CREATE_DATE >='2013-07-09 00:00'
AND CREATE_DATE <='2014-04-30 00:00'
AND TYPE='S'
SELECT * FROM TEST
WHERE CREATE_DATE >='2013-07-09 00:00'
AND CREATE_DATE <='2014-04-30 00:00'
AND TYPE='S'
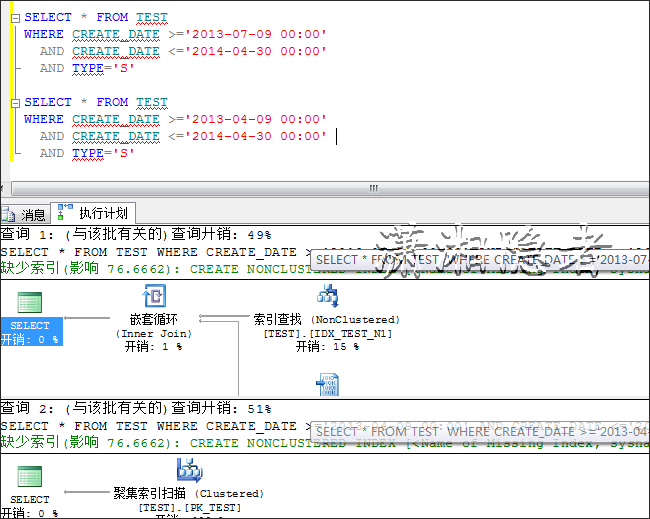
下面看看这两个SQL的执行计划的差异,这两个SQL略有差异,查询字段不同,一个是查询所有字段,一个是查询CREATE_DATE, TYPE两个字段

对比两者的执行计划

这里涉及索引覆盖所,想深入理解可以参考宋沄剑这篇博客T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤.
在这个简单例子中,我们可以用查询必须字段代替*,用索引覆盖避免其走RID查找,但是实际环境中往往比较复杂,有时候同一个表上的查询SQL,可能非常多,索引覆盖也往往不可能全部涉及。所以在写SQL代码中,我们要养成查询必要字段的习惯,不要生成SELECT *的习惯,因为它有下面一些弊端:
1:如果你只需要表中几个字段,SELECT * 会产生额外的IO,消耗额外的带宽资源。当数据库有大量这类SQL,就会产生量变到质变。慢慢影响整个数据库的性能。
2:习惯成必然(很多时候大部分人都是从SELECT * FROM开始的),养成了这样写SQL的习惯。
3:造成额外的书签查找或是由查找变为扫描
4: 产生潜在的BUG 例如 INSERT INTO T (COLUMN1,…… )SELECT * FROM M . 如果M表字段增加、或修改字段类型等都会导致错误。
上面仅仅是题外话,这里要说明的是你的SQL写法也有可能影响执行计划。
下面来看一个例子,突然某天有这么样一个需求(当然实际情况远比这个复杂),
DROP TABLE TEST;
SELECT * INTO TEST FROM sys.objects
CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID)
UPDATE STATISTICS TEST WITH FULLSCAN
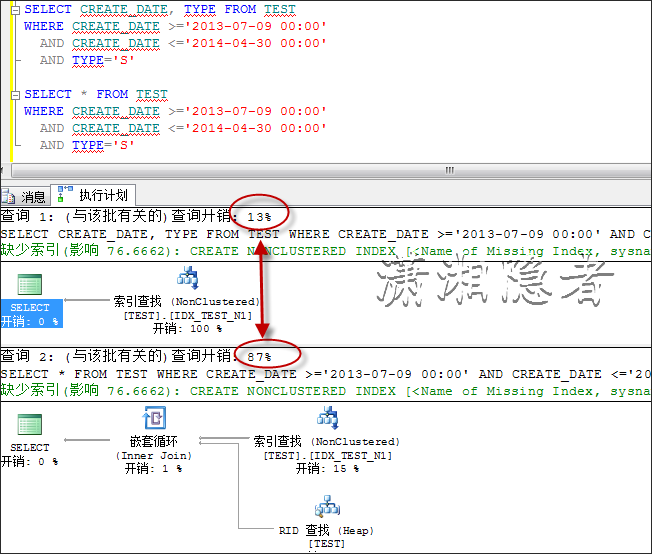
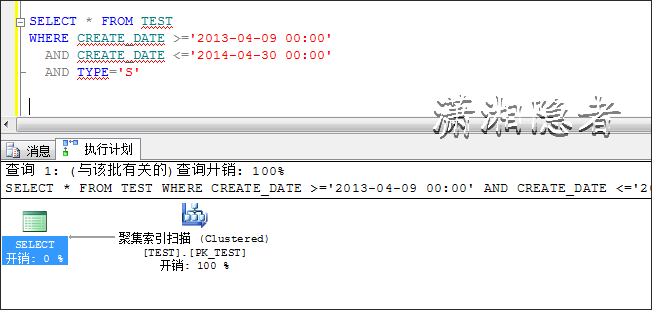
SELECT * FROM TEST
WHERE CREATE_DATE >='2013-04-09 00:00'
AND CREATE_DATE <='2014-04-30 00:00'
AND TYPE='S'

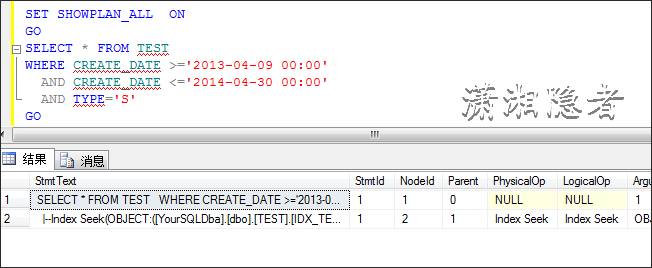
某个开发人员在测试、优化过程中,发现执行计划走聚集索引扫描,于是想如果给CREATE_DATE和TYPE字段建立一个索引,那么它会不会快一点?结果他发现他添加了索引,可是优化器根本不走他建立的索引,为什么呢?
CREATE INDEX IDX_TEST_N1 ON TEST(CREATE_DATE, TYPE)
UPDATE STATISTICS TEST WITH FULLSCAN
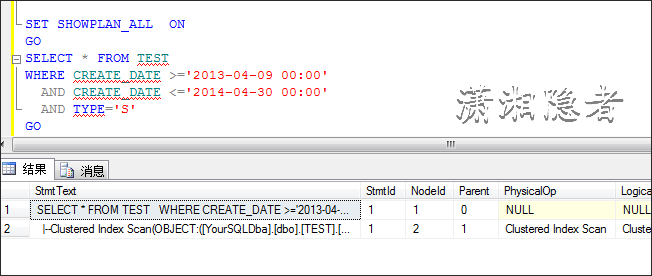
SET SHOWPLAN_ALL ON
GOSELECT * FROM TEST
WHERE CREATE_DATE >='2013-04-09 00:00'
AND CREATE_DATE <='2014-04-30 00:00'
AND TYPE='S'
GO

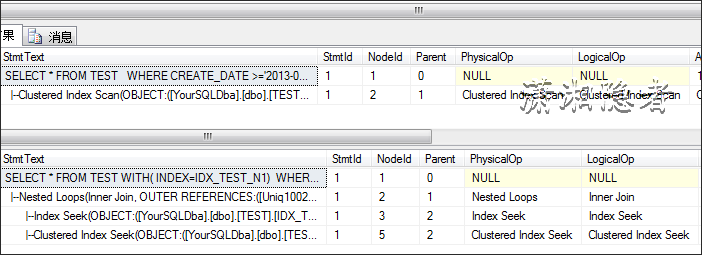
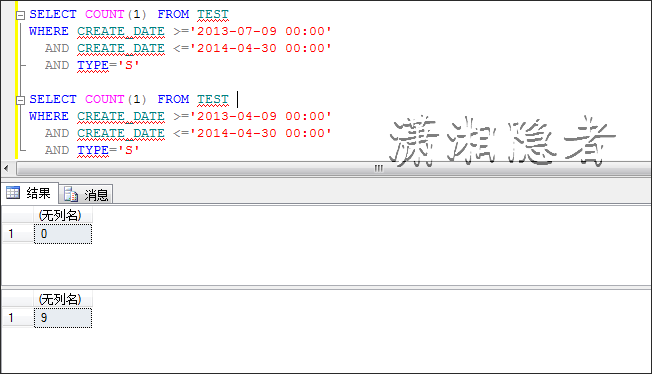
我们又要使用查询提示强制其走索引查找,来对比其开销代价
SET SHOWPLAN_ALL ON
GOSELECT * FROM TEST
WHERE CREATE_DATE >='2013-04-09 00:00'
AND CREATE_DATE <='2014-04-30 00:00'
AND TYPE='S'
GOSET SHOWPLAN_ALL OFF;
GOSET SHOWPLAN_ALL ON
GOSELECT * FROM TEST WITH( INDEX=IDX_TEST_N1)
WHERE CREATE_DATE >='2013-04-09 00:00'
AND CREATE_DATE <='2014-04-30 00:00'
AND TYPE='S'
GOSET SHOWPLAN_ALL OFF;
GO


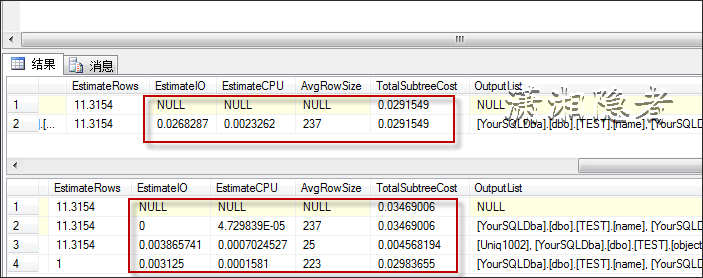
优化器发现走聚集索引的开销小于走IDX_TEST_N1索引查找,所以即使你在查询条件上建有索引,执行计划还是不会走这个索引。如果我创建索引时,覆盖这些字段,那么它就会走索引查找而不会是聚集索引。
DROP INDEX IDX_TEST_N1 ON TEST
CREATE NONCLUSTERED INDEX IDX_TEST_N1
ON [dbo].[TEST] ([type],[create_date])INCLUDE ([name],[object_id],[principal_id],[schema_id],[parent_object_id],[type_desc],[modify_date],[is_ms_shipped],[is_published],[is_schema_published])GO

另外还附上我测试过程中,查询条件取值不同,执行计划不同的案例(不然有些人也会觉得迷惑),还是那句话,数据会影响执行计划的选择。


后记:
生产环境的案例往往比我上面几个简单例子复杂得多,分析优化起来更加麻烦。我们优化时要透过现象看本质,多思考,多对比才能拨开迷雾见真相!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号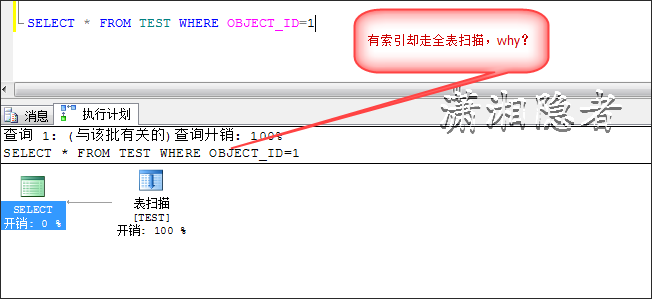{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}