

【JMeter】常用后置处理器性能比较(上)
前几天看了这篇文章 JMeter – Response Data Extractors – Comparison ,结论有点吓人

用了css提取器吞吐率降到不足1/15?!按作者结论最快的正则提取器也降到1/5?
如果真是那样那没法用了,就好像测水温,温度计一插下去降了80度那还测个毛……
让我觉得奇怪的是,作者没有放出每个提取器里写了什么,为啥用一段XML的报文能测这么多提取器
实验了一下发现,作者的测试方法就是提取器里什么都不写
当且仅当什么都没写时,作者的结论才是正确的……
但如果放到更贴近实际的场景里测试,会得出完全不一样的结论:
这些提取器在什么都没写时,比实际做了什么还慢得多,导致这么吓人的测试结果
下面来个正经点的测试,按不同返回类型比较提取器
环境:jmeter 2.13、JDK 1.8u73、JVM参数从来没动过、win 10 pro
测试计划如下:
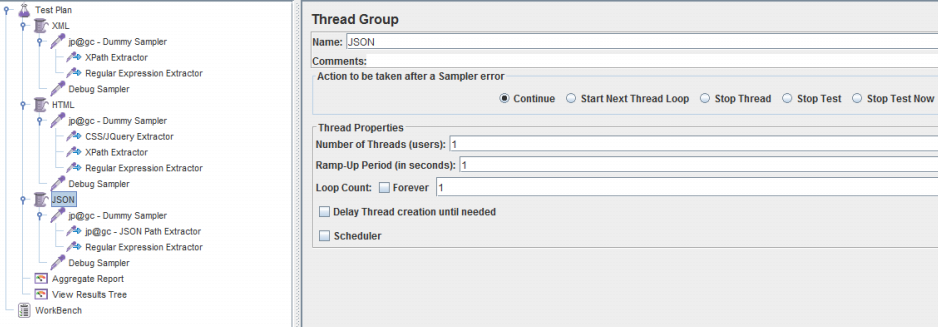
先用单线程单循环调试,调试采样器和查看结果树都打开
事前准备
所有dummy sampler都设成没有延时
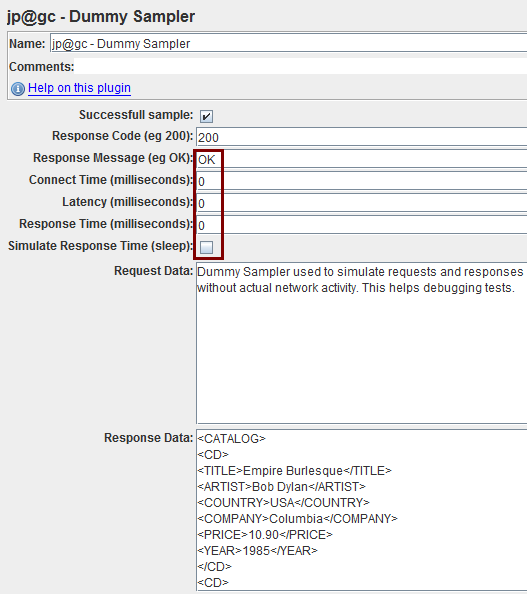
请求数据不用改,响应数据分别设置:
xml跟那文章的作者一样贴这个 http://www.w3schools.com/xml/cd_catalog.xml
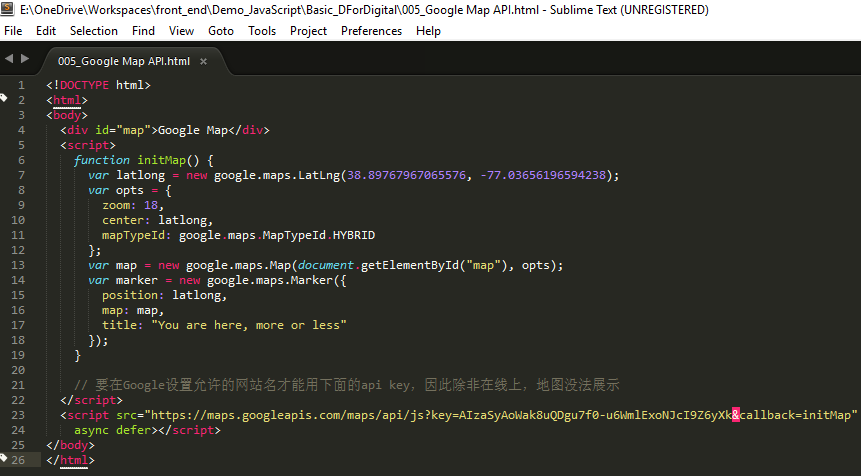
html随便来个google地图的示例
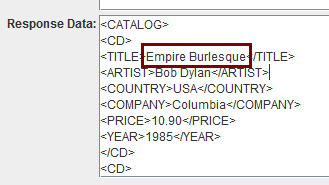
json用这里面的 http://goessner.net/articles/JsonPath/
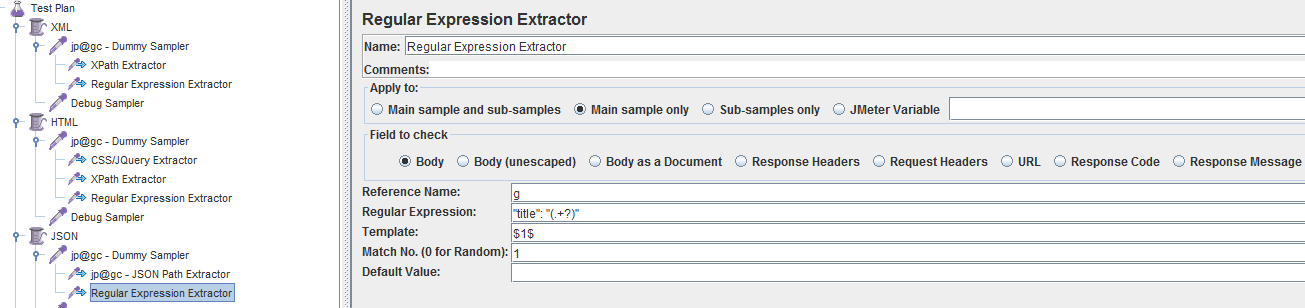
红框圈出的是分别想提取的数据:
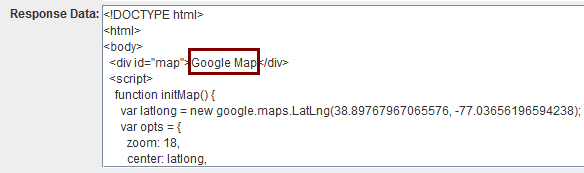
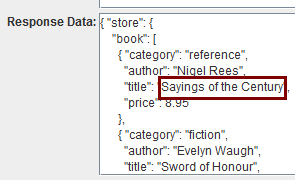
设置好各提取器,调试,发现xpath提取器报错了
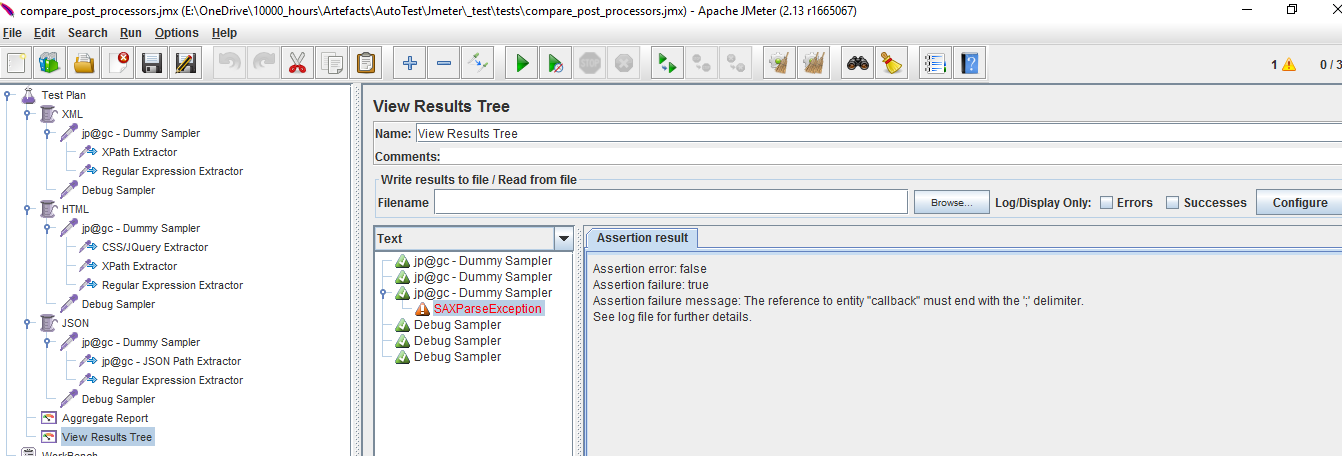
看看dummy sampler里的html,发现是 & 符号搞鬼,改成url编码 &

再试,还有错

把async和defer改成符合xhtml规范,搞定

调试通过后的各提取器设置如下:
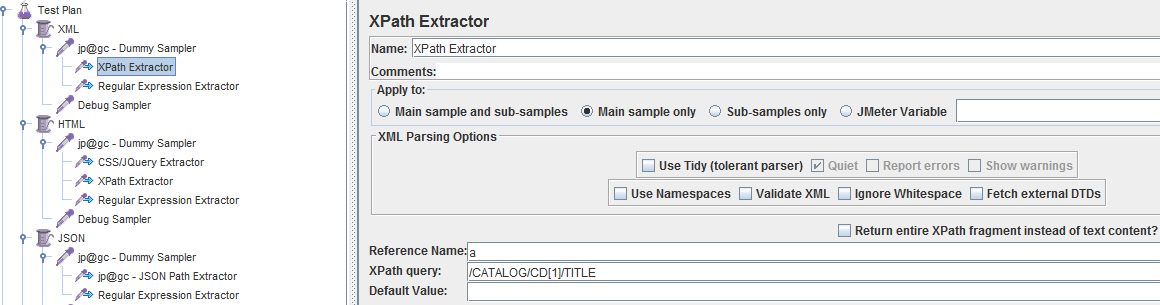
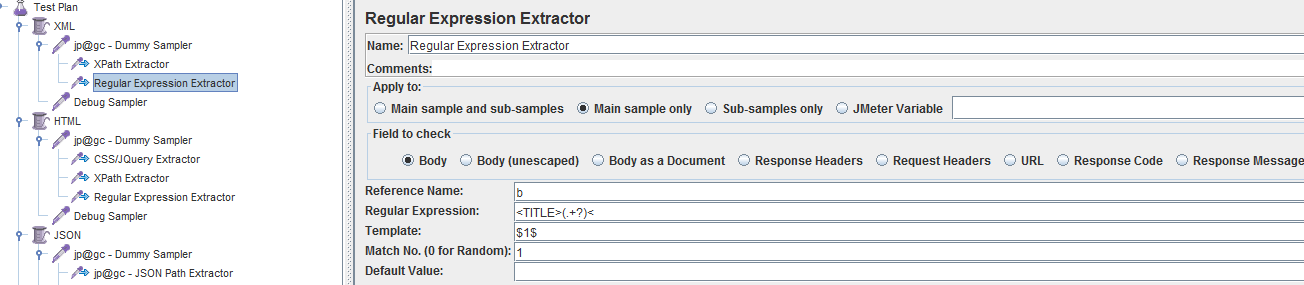
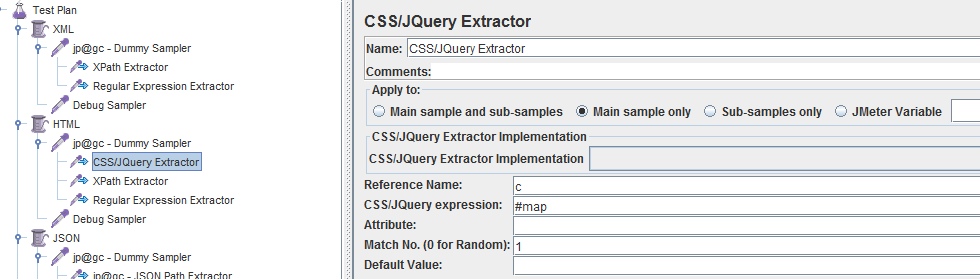
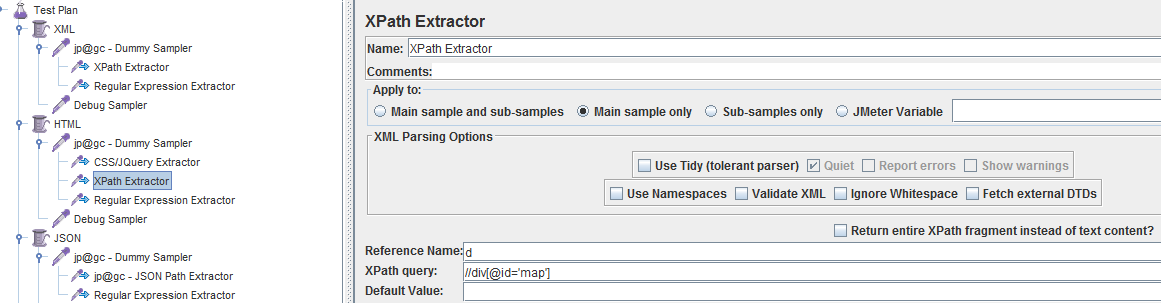
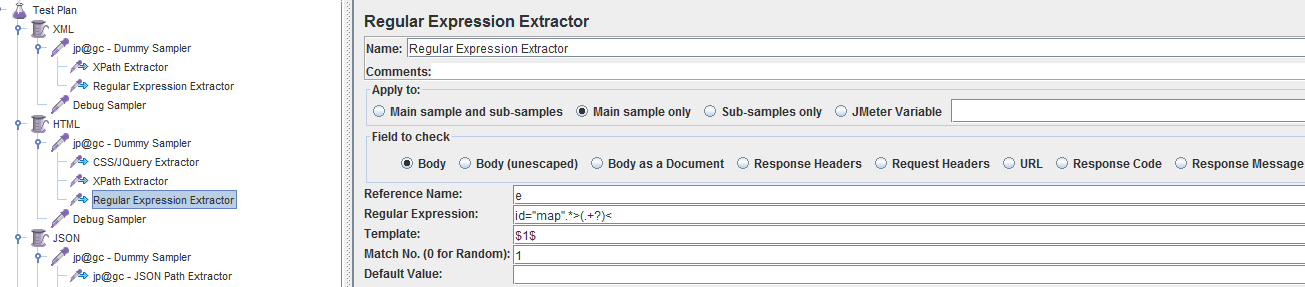

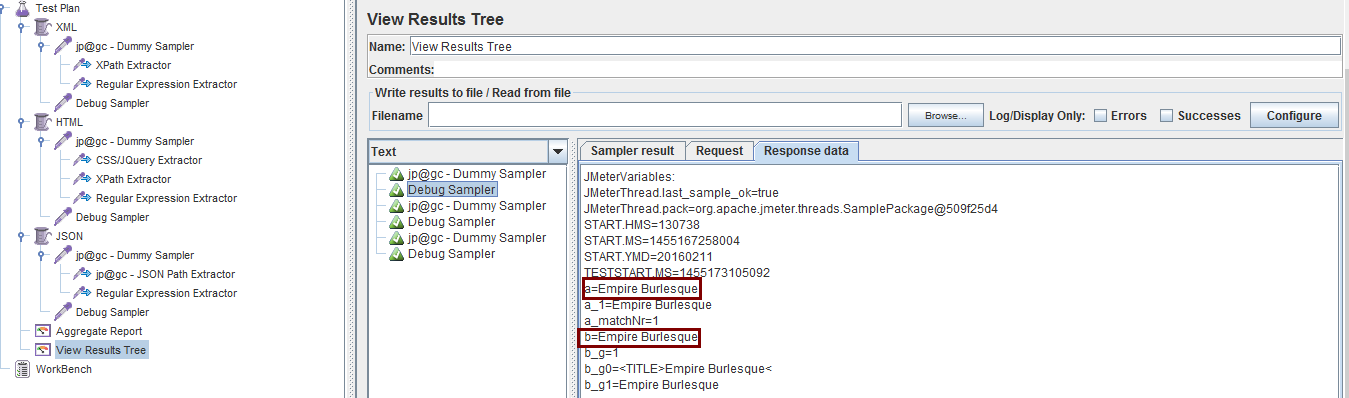
调试结果如下:
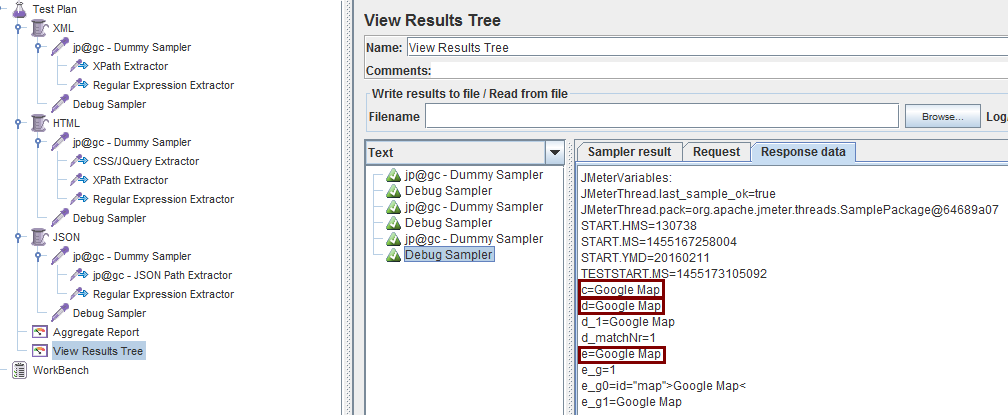
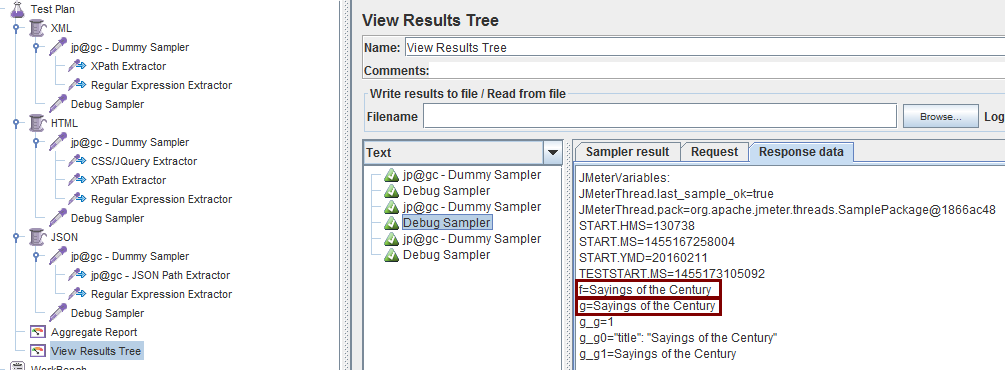
接下来修改各个线程组设置:
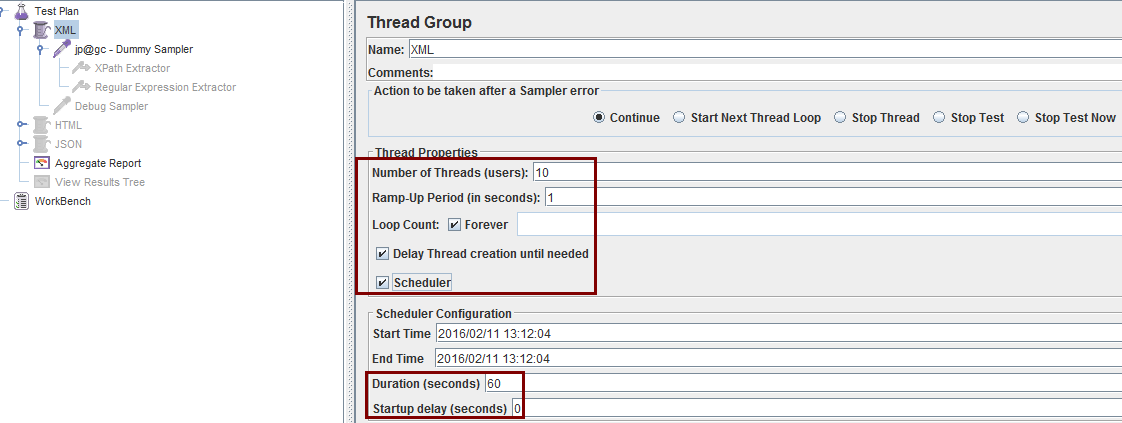
一律设成10线程,1秒集结(即每隔0.1秒来1个),持续60秒,没启动延迟。跟那文章作者的设置保持一致
(开始和结束时间是自动生成的,不用管,设了持续时间它们就用不上了)
最后选中用不着的组件,按ctrl + t禁用掉(就是图中变灰那些),就可以开始实际测试了
图有点多,测试过程及结果留到下一篇放出


【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· ASP.NET Core 模型验证消息的本地化新姿势
· 对象命名为何需要避免'-er'和'-or'后缀
· SQL Server如何跟踪自动统计信息更新?
· AI与.NET技术实操系列:使用Catalyst进行自然语言处理
· 分享一个我遇到过的“量子力学”级别的BUG。
· AI Agent爆火后,MCP协议为什么如此重要!
· Draw.io:你可能不知道的「白嫖级」图表绘制神器
· dotnet 源代码生成器分析器入门
· ASP.NET Core 模型验证消息的本地化新姿势
· Java使用多线程处理未知任务数方案