
python - bilibili(一)获取直播间标题
近几年,直播平台蛮火的。小时候,经过各种日漫的洗礼,在直播平台自然而然的就盯上了B站。
目前还是python菜鸟一枚,各位大佬请轻拍。
最终效果图:

闲话不说,我们来一步步解析B站的弹幕。
工具:python3.5 平台:windows10
首先,浏览器打开B站直播180房间(2017-07-07更新:少寒主播已离开B站在YY直播,180房间号已不能访问),房间主播是:少寒Shine。
接着,按f12获取网站的源代码

看<head>标签中,编码是utf-8;<title>标签是房间的标题,正是程序所需要的,所以我们只需要用python提取<title></title>这个标签的内容就行了。
思路:
1、导入urllib.request库和re库
2、获取直播的地址。
3、用到python中urllib.request库来请求网页,获取源代码并解码。
4、用正则表达式或者其他方式提取所需要内容。
5、打印所提取的内容。
鉴于正则表达式提取的代码比较长,我选择使用xpath一步到位。xpath是从XML 文档中提取信息,所以要将请求的网页转换成xml文档。xml是第三方库,而不是python自带的库,那么就需要安装xml。python3中xml库的名字叫lxml,具体安装过程请自行百度一下。
那么,我们重新理一下思路:
1、导入urllib.request库和lxml库
2、获取直播的地址。
3、用到python中urllib.request库来请求网页,获取源代码并解码。
4、将网址转换成xml格式。
5、用xpath来提取<title>中的内容。
6、打印所提取的内容。
代码:
1 import urllib.request 2 from lxml import etree 3 4 roomId = input('请输入房间号:') 5 roomUrl = 'http://live.bilibili.com/'+ str(roomId) 6 webPage=urllib.request.urlopen(roomUrl) 7 html = webPage.read().decode('utf-8') 8 html = etree.HTML(html) 9 title = html.xpath('//title/text()') 10 print('房间名称:%s'%title[0])
效果图:

不过,这段代码是有bug的,假如我输入的房间号不是数字或者我输入的数字并不是一个直播间的房间号,那么程序会报错
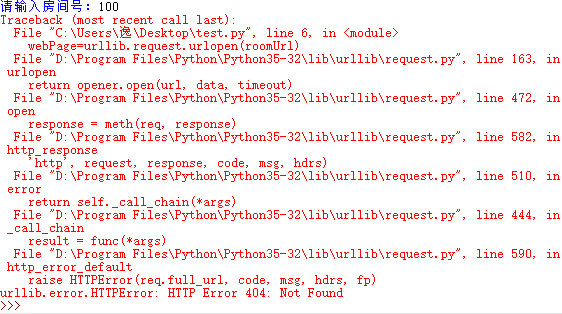
遇到这种报错,我们就解决bug,让这种错误不再出现。
系列下一章:python - bilibili(二)房间号格式出错

