
字符串编码与项目编码问题
最近项目设计到java项目与c项目基于tcp通信的数据交互,在发送数据的过程中由java发送数据给c项目,出现了乱码,彻底学习了下字符串编码与文件编码之间的关系,关于编码的什么ASCII、UTF-8(Unicode的一种实现)、GBK之间的关系网上一搜一箩筐,不在详细阐述,可以参看这里。
每个项目都有工程编码,java工程可以项目->属性(properties)查看其编码,而我们在写c项目的时候好像从来都没有注意这些。在vs2010默认的是ANSI(即GBK)的,CodeBlock默认的也是GBK。我们先来看下c项目字符串的编码与文件编码的关系。
使用CodeBlock建了两个c项目,一个编码是GBK的,一个是UTF-8,(CodeBlock项目编码设置setting->editor->other setting),使用相同的代码
int main()
{
int i = 0;
char* str = "中文";
while(str[i++] != '\0')
{
printf("%0x\n",str[i]&0xFF);
}
printf("%s", str);
return 0;
}
打印"中文"在内存中的编码,在UTF的c项目中输出结果为: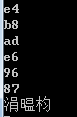 ,用二进制文件查看其.c和.exe文件编码
,用二进制文件查看其.c和.exe文件编码

可以看到.exe文件和.c中char* str都是UTF-8编码,与输出的字符串编码是一致的。
再来看GBK的c项目中的输出情况: ,文件.c、.exe二进制编码情况:
,文件.c、.exe二进制编码情况:

那么可以肯定:在c项目中,字符串的编码char* str与文件.c的编码是一致的,而文件的编码一般默认与项目编码一致。这里有必要就UTF-8项目输出的是乱码进行解释,因为win操作系统环境是中文GBK的,控制台默认输出的是GBK,所以当输出UTF-8的字符串时就出现了乱码。
----------------------------------------------------------------java分割线-------------------------------------------------------------------------------------------------------------------------
再来看java项目中.class与.java文件之间的编码关系,我们先建一个GBK的java项目,代码如下:
import java.io.UnsupportedEncodingException;
public class test {
public static void main(String[] args) {
String str = "中文";
try {
byte[] bs = str.getBytes("GBK");
for(int i = 0; i < bs.length; i++){
System.out.println(Integer.toHexString(bs[i]));
}
String str2 = new String(bs,"GBK");
System.out.println(str2);
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
java对字符串的编码处理支持就好的多了,你可以获取任何自己想要字符编码,并指定其输出编码(一般编码用什么,解码就用什么)。在GBK的项目中.java文件用的是ANSI的存储方式,.class文件是以何种编码呢?GBK吗?,我们来看下.java和.class文件的二进制:

String str在.java文件中是GBK存储,但是生成的二进制.class文件其编码却是UTF-8的!!!也就是我们说的java采用的是Unicode编码,在生成.class文件的时候编译器帮我们把各种不同编码的.java文件全部生成统一的Unicode编码的.class文件,那么在java平台所有字符在内存中的表示都是统一的(不管你的项目是什么编码,字符串内存表示都一样,与项目编码无关)。
至于UTF-8的java项目其.java和.class一定都是一样的编码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号