

python 正则表达提取方法 (提取不来的信息print不出来 加个输出type 再print信息即可)
1,正则表达提取 (findall函数提取)
import re
a= "<div class='content'>你大爷</div>"
x=re.findall("<div class='content'>(.*)</div>",a)
这样也可以:
x=re.findall(" class='content'>(.*)</d",a) 其中" class='content'>(.*)</d" 是匹配左边为class='content'> 右边为</d ,取其中的字符
print x[0]
后记: 今天傻逼了 这个api 可以从中间去匹配字符
如:
x=re.findall("content'>(.*)</",a)
也可以取到中间的你大爷 ,下次遇到很长的字符 记得从中间截取的取匹配哟!!
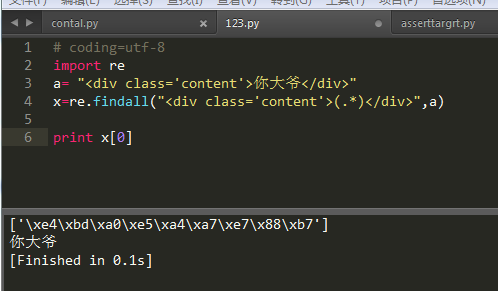
有时候发现输出list的字符时会展示不出:
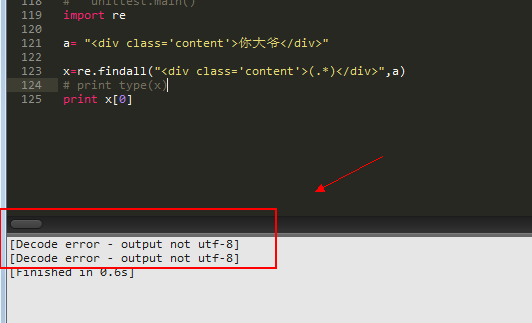
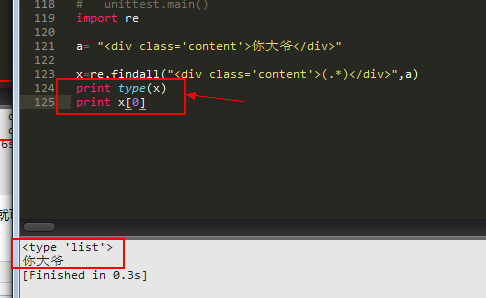
加上print typ(x),就可以了
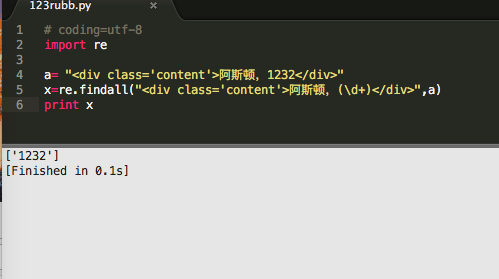
取中间的数字方法:
目标
{'_id': {'created': '2022-11-24 14:32:26', 'platform': '后端'}, 'Count': 1}
取数
re.findall("(.\d*)-",trend["_id"]["created"])[1]
['2022', '11']
第二种方法:python类似正则表达式的函数
Url:http://www.jb51.net/article/54281.htm
startswith()函数
此函数判断一个文本是否以某个或几个字符开始,结果以True或者False返回。
text='welcome to qttc blog'
print text.startswith('w') # True
endswith()函数
此函数判断一个文本是否以某个或几个字符结束,结果以True或者False返回。
判断文件是否为exe执行文件
我们可以利用endswith()函数判断文件名的是不是以.exe后缀结尾判断是否为可执行文件
另外一种截取字符的: https://www.cnblogs.com/kaibindirver/p/7488885.html
