
数据结构整理(一) 线性结构
一、前言
自己挖的坑还是得自己来填,当年学数据结构(C++版本)天天打酱油,课程结业的时候还以为->是一个字符,自己还纳闷这东西是怎么键入的,直到做结业设计的时候看团支书的代码才突然醒悟,特此感谢下团支书MM,我想如果老师知道了应该不会打我...,后来尝试看过两次数据结构,都没坚持看完。现找了一本C#版本的数据结构,预计在月底前看完并针对五个模块(线性结构、树、图、排序、查找)各出一篇博客,也算是对自己的一种督促。在此吐槽一下虽然书上的思路很清晰但是示例代码坑好深。
实践源码:https://github.com/Nik364/DataStructure.git
声明:文中信息大量摘自数据结构图书(暂不知作者,因为没有编者,网上搜索关键字【C#数据结构】即可找到),后续就不做其他说明了
二、相关概念
- 线性结构作为最常用的数据结构,其特点是数据元素之间存在一对一的线性关系。
- 线性结构拥有两种不同的存储结构,即顺序存储结构和链式存储结构。顺序存储的线性表称为顺序表,顺序表中的存储元素是连续的,链式存储的线性表称为链表,链表中的存储元素不一定是连续的,元素节点中存放数据元素以及相邻元素的地址信息。
- 线性结构中存在两种操作受限的使用场景,即队列和栈。栈的操作只能在线性表的一端进行,就是我们常说的先进后出(FILO),队列的插入操作在线性表的一端进行而其他操作在线性表的另一端进行,先进先出(FIFO),由于线性结构存在两种存储结构,因 此队列和栈各存在两个实现方式。
三、部分实现
- 顺序表(顺序存储)
按照我们的习惯,存放东西时,一般是找一块空间,然后将需要存放的东西依次摆放,这就是顺序存储。计算机中的顺序存储是指在内存中用一块地址连续的空间依次存放数据元素,用这种方式存储的线性表叫顺序表其特点是表中相邻的数据元素在内存中存储位置也相邻,如下图:
1 // 倒置线性表 2 public void Reverse() 3 { 4 T tmp = default(T); 5 6 int len = GetLength() - 1; 7 for (int i = 0; i <= len / 2; i++) 8 { 9 if (i.Equals(len - i)) 10 { 11 break; 12 } 13 14 tmp = data[i]; 15 data[i] = data[len - i]; 16 data[len - i] = tmp; 17 } 18 }
- 链表(链式存储)
假如我们现在要存放一些物品,但是没有足够大的空间将所有的物品一次性放下(电脑中使用链式存储不是因为内存不够先事先说明一下...,具体原因后续会说到),同时设定我们因为脑容量很小,为了节省空间,只能记住一件物品位置。此时我们很机智的找到了解决方案:存放物品时每放置一件物品就在物品上贴一个小纸条,标明下一件物品放在那里,只记住第一件物品的位置,寻找的时候从第一件物品开始寻找,通过小纸条我们可以找到所有的物品,这就是链式存储。链表实现的时候不再像线性表一样只存储数据即可,还有下一个数据元素的地址,因此先定义一个节点类(Node),记录物品信息和下一件物品的位置,我们把物品本身叫做数据域,存储下一件物品地址信息的小纸条称为引用域。链表结构示意图如下: 寻找物品的时候发现了一个问题,我们从一件物品找下一件物品的时候很容易,但是如果要找上一件物品就得从头开始找,真的很麻烦。为了解决这个问题我们又机智了一把,模仿之前的做法,在存放物品的时候多放置一个小纸条记录上一件物品的位置,这样就可以很快的找到上一件物品了。我们把这种方式我们称为双向链表,前面只放置一张小纸条的方式称为单向链表。
寻找物品的时候发现了一个问题,我们从一件物品找下一件物品的时候很容易,但是如果要找上一件物品就得从头开始找,真的很麻烦。为了解决这个问题我们又机智了一把,模仿之前的做法,在存放物品的时候多放置一个小纸条记录上一件物品的位置,这样就可以很快的找到上一件物品了。我们把这种方式我们称为双向链表,前面只放置一张小纸条的方式称为单向链表。
1 // 倒置单链表 2 public void Reverse() 3 { 4 Node<T> oldHead = Head; 5 Node<T> tmp ; 6 Head = null; //清空链表,解除Head跟oldHead之间的相同引用 7 8 while (oldHead != null) 9 { 10 tmp = Head; 11 Head = oldHead; 12 //解除Head跟oldHead之间的相同引用 13 oldHead = oldHead.Next; 14 Head.Next = tmp; 15 } 16 }
由于数据存储结构不同导致使用场景上的巨大差异,顺序表由于元素连续具有随机存储的特点,所以查找数据很方便效率很高,但是插入、删除操作为了确保数据元素连续,需要移动大量的数据导致效率很低。而链表由于存储空间不要求连续,插入、删除只需修改相邻元素的引用域地址即可,所以效率很高,但查询需要从头引用开始遍历链表,效率很低。因此,如果只是进行查找操作而不经常插入、删除线性表中的数据元素,则使用顺序存储结构,反之,使用链式存储结构。
- 栈
其实成功完成顺序表和链表之后,栈已经没太多可说的了,主要是逻辑上的不同,毕竟栈也是一种特殊的线性结构。栈是一种操作限定在表尾部进行的线性表,表尾称为栈顶(Top),另一端固定不动,称为栈底(Bottom)。进栈、出栈示意图如下: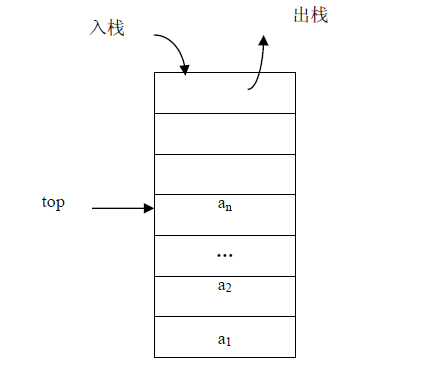
1 //链栈入驻 2 public void Push(T item) 3 { 4 Node<T> tmp = new Node<T>(item); 5 if (Top == null) 6 { 7 Top = tmp; 8 } 9 else 10 { 11 tmp.Next = Top; 12 Top = tmp; 13 } 14 Num++; 15 } 16 17 //顺序栈入栈 18 public void Push(T item) 19 { 20 if (IsFull()) 21 { 22 throw new Exception("Stack is full"); 23 } 24 25 data[++Top] = item; 26 }
- 队列
队列与栈类似,仅仅是逻辑有一丢丢不同。队列是一种插入操作限定在表尾其他操作限定在表头的线性表。把进行插入操作的表尾称为队尾(Rear),把进行其它操作的头部称为队首(Front)。入队、出队示意图如下:
1 //链队入队 2 public void In(T item) 3 { 4 Node<T> node = new Node<T>(item); 5 if (Rear == null) 6 { 7 Rear = node; 8 Front = Rear; 9 } 10 else 11 { 12 Rear.Next = node; 13 Rear = Rear.Next; 14 } 15 ++num; 16 } 17 18 //循环队列入队 19 public void In(T item) 20 { 21 if (IsFull()) 22 { 23 throw new Exception("Queue is full"); 24 } 25 data[++Rear] = item; 26 }
最后说一句,临渊羡鱼不如退而结网,只有自己动手实践才知道是不是真的理解了,实现链式结构的时候才发现原来自己对于对象地址的理解并没有那么的透彻...

