
带新手走进神秘的HTTP协议
在开发的时候经常需要访问网络,比如Android就有好多这方面的框架:Volley、OkHttp、Retrofit等,当你看这些框架源码时,可能会很好奇关于http的部分,它的首部字段是什么意思,http是如何工作的??等等,希望这篇文章会为你解惑。
一、概念
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。
HTTP协议,即超文本传输协议(Hypertext transfer protocol)。是一种详细规定了浏览器和万维网(WWW = World Wide Web)服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
HTTP协议是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
在Internet中所有的传输都是通过TCP/IP进行的。HTTP协议作为TCP/IP模型中应用层的协议也不例外。HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。如下图所示:

HTTP默认的端口号为80,HTTPS的端口号为443。
浏览网页是HTTP的主要应用,但是这并不代表HTTP就只能应用于网页的浏览。HTTP是一种协议,只要通信的双方都遵守这个协议,HTTP就能有用武之地。比如咱们常用的QQ,迅雷这些软件,都会使用HTTP协议(还包括其他的协议)。
二、简史
HTTP/0.9
HTTP 于 1990 年问世。那时的 HTTP 并没有作为正式的标准被建立。现在的 HTTP 其实含有 HTTP1.0 之前 版本的意思,因此被称为 HTTP/0.9。
HTTP/1.0
HTTP 正式作为标准被公布是在 1996 年的 5 月,版本被命名为 HTTP/1.0,并记载于 RFC1945。虽说是初 期标准,但该协议标准至今仍被广泛使用在服务器端。
RFC1945 - Hypertext Transfer Protocol -- HTTP/1.0
http://www.ietf.org/rfc/rfc1945.txt
HTTP/1.1
1997 年 1 月公布的 HTTP/1.1 是目前主流的 HTTP 协议版本。当初的标准是 RFC2068,之后发布的修订版 RFC2616 就是当前的最新版本。
RFC2616 - Hypertext Transfer Protocol -- HTTP/1.1
http://www.ietf.org/rfc/rfc2616.txt
可见,作为 Web 文档传输协议的 HTTP,它的版本几乎没有更新。新一代 HTTP/2.0 正在制订中,但要达到 较高的使用覆盖率,仍需假以时日。
三、统一资源定位符
URL 的一般形式是:
<URL的访问方式>://<主机>:<端口>/<路径>

四、HTTP 的操作过程
- 每个Web站点都运行一个服务器进程,它不断地监听TCP的端口80,以便发现是否有向它发来连接请求;
- 一旦收到请求并建立了TCP连接之后,浏览器就向服务器发出某个页面的请求,服务器接着就返回请求的页面作响应;
- 最后连接被释放。这之间一系列信息的传输都遵循HTTP。
五、Web工作过程
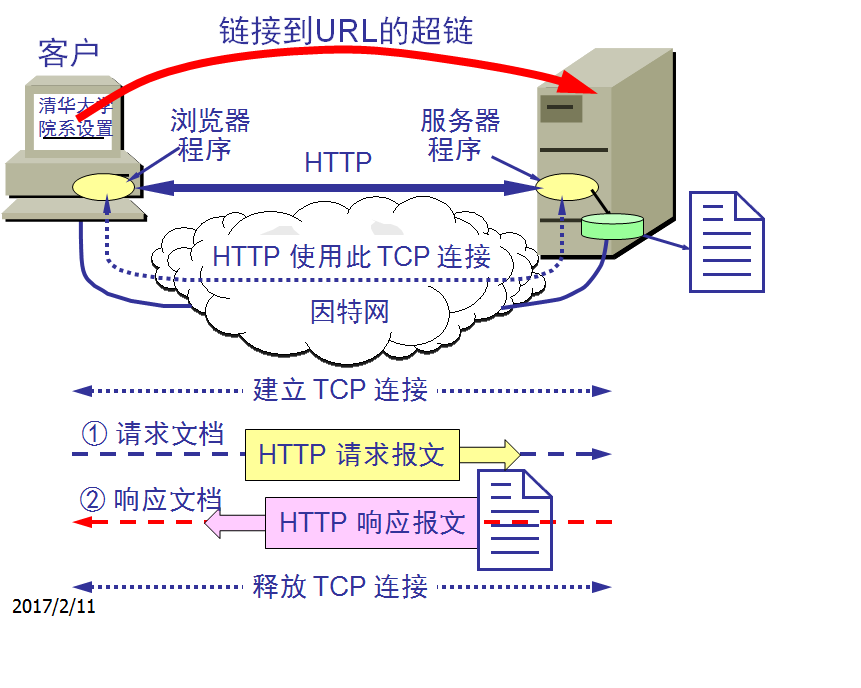
上图用户点击鼠标后所发生的事件:
(1) 浏览器分析超链指向页面的 URL;
(2) 浏览器向 DNS 请求解析 www.tsinghua.edu.cn 的 IP 地址;
(3) 域名系统 DNS 解析出清华大学服务器的 IP 地址;
(4) 浏览器与服务器建立 TCP 连接;
(5) 浏览器遵循HTTP协议发出取文件命令:
GET /chn/yxsz/index.htm;
(6) 服务器给出响应,把文件 index.htm 发给浏览器;
(7) TCP 连接释放;
(8) 浏览器显示“清华大学院系设置”文件 index.htm 中的所有文本。
六、HTTP 的报文种类
HTTP 有两类报文:
请求报文——从客户向服务器发送请求报文。
响应报文——从服务器到客户的回答。
6.1 HTTP 的报文结构
6.1 请求报文
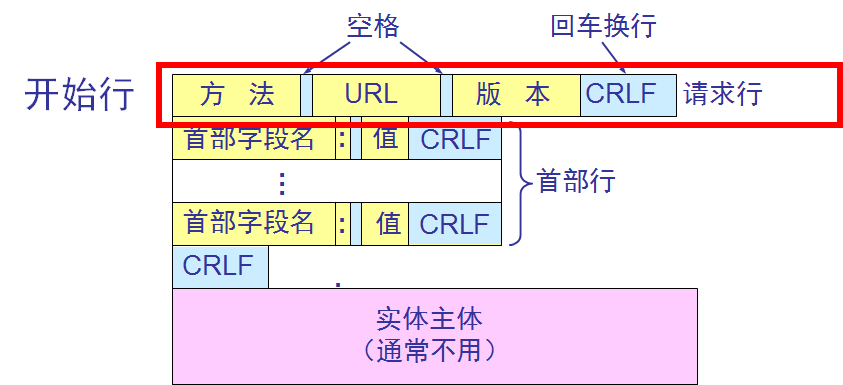
报文由三个部分组成,即开始行、首部行和实体主体。
在请求报文中,开始行就是请求行。
1. 方法:
“方法”是面向对象技术中使用的专门名词。所谓“方法”就是对所请求的对象进行的操作,因此这些方法实际上也就是一些命令。因此,请求报文的类型是由它所采用的方法决定的。
HTTP 请求报文的一些方法

2.URL
“URL”是所请求的资源的 URL。
3.版本
“版本”是 HTTP 的版本。
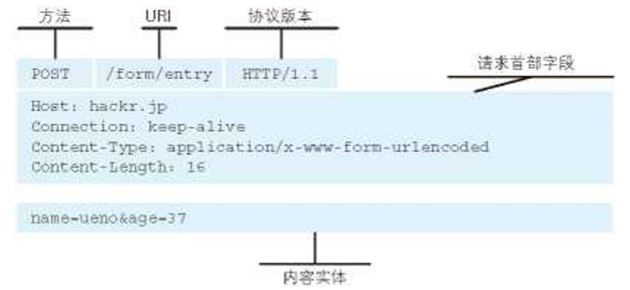
4.一个请求报文的例子:
6.2 响应报文
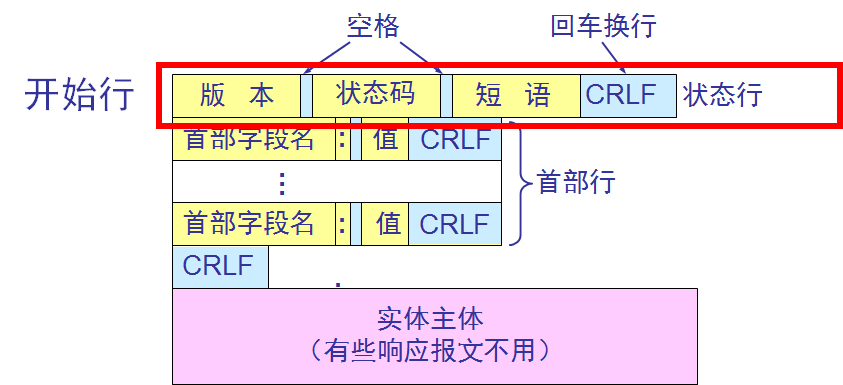
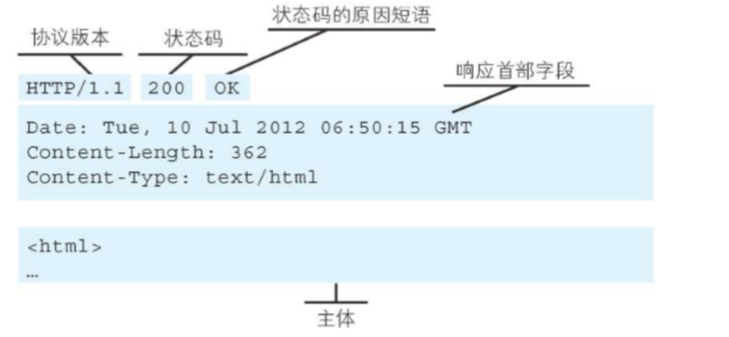
响应报文的开始行是状态行。
状态行包括三项内容,即 HTTP 的版本,状态码,以及解释状态码的简单短语。
状态码都是三位数字 :
- 1xx 表示通知信息的,如请求收到了或正在进行处理。
- 2xx 表示成功,如接受或知道了。
- 3xx 表示重定向,表示要完成请求还必须采取进一步的行动。
- 4xx 表示客户的差错,如请求中有错误的语法或不能完成。
- 5xx 表示服务器的差错,如服务器失效无法完成请求。
一个响应报文的例子:
6.3 使用WireShark实例分析
下面是一个用wireShark获取的http协议包:

可以看到这是post方法、url:/pcsuiteprofile/api/updateinfo?u=38e37ccd&len=24
版本:HTTP/1.1 \r\n:回车换行
首部字段:Host、Accept、Content-Type、Content-Length等等。
展开Post,具体分析,如图:
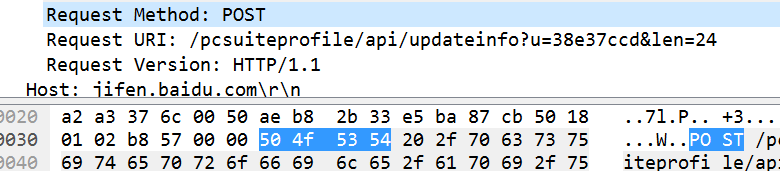
选中post,下边的16进制中显示的是:50 4f 53 54正好是POST四个字母对应的16进制ASCII,可以自行去对比ASCII。
如果你不会用wireShark,可以看下这篇文章:https://community.emc.com/message/818739#818739,只看一就够用了。
七、使用 Cookie 的状态管理
HTTP 是无状态协议,它不对之前发生过的请求和响应的状态进行管理。也就是说,无法根据之前的状态进行本次的请求处理。
Cookie 技术通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。
Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie 的首部字段信息,通知客户端保存 Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出去。
服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务 器上的记录,最后得到之前的状态信息。
1. 没有 Cookie 信信息状态下的请求
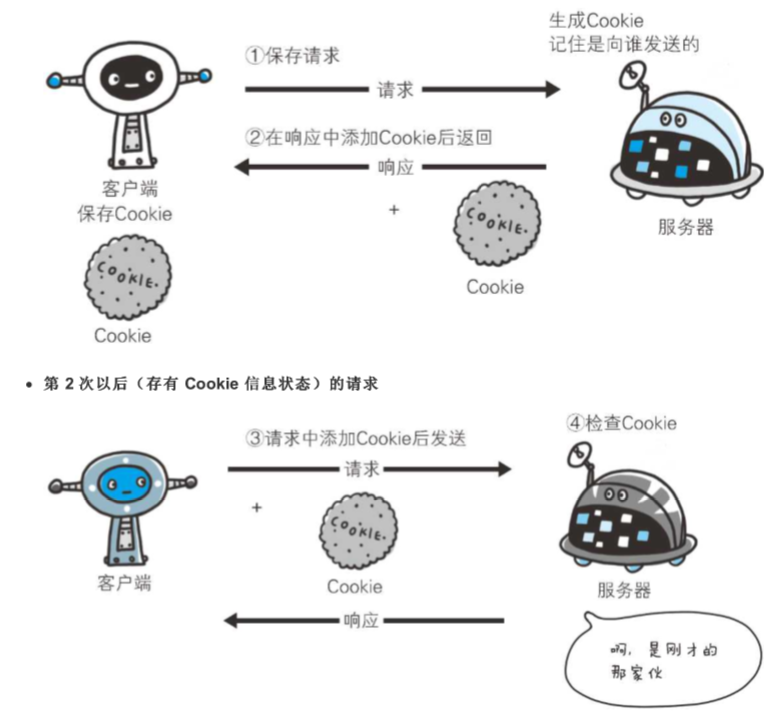
上图展示了发生 Cookie 交互的情景,HTTP 请求报文和响应报文的内容如下。
1. 请求报文(没有 Cookie 信息的状态)
GET/reader/HTTP/1.1 Host:hackr.jp *首部字段内没有Cookie的相关信息
2. 响应报文(服务器端生成 Cookie 信息)
HTTP/1.1200OK Date:Thu,12Jul201207:12:20GMT Server:Apache <Set-Cookie:sid=1342077140226724;path=/;expires=Wed,10-Oct-1207:12:20GMT> Content-Type:text/plain;charset=UTF-8
3. 请求报文(自动发送保存着的 Cookie 信息)
GET/image/HTTP/1.1 Host:hackr.jp Cookie:sid=1342077140226724
有关请求报文和响应报文内Cookie 对应的首部字段,请参考之后的章节。
八、特点
HTTP协议永远都是客户端发起请求,服务器回送响应。这样就限制了使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端。
HTTP协议的主要特点可概括如下:
1、支持客户/服务器模式。支持基本认证和安全认证。
2、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4、HTTP 0.9和1.0使用非持续连接:限制每次连接只处理一个请求,服务器处理完客户的请求,并收到客户的应答后,即断开连接。HTTP 1.1使用持续连接:不必为每个web对象创建一个新的连接,一个连接可以传送多个对象,采用这种方式可以节省传输时间。
5、无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。
无状态协议:
协议的状态是指下一次传输可以“记住”这次传输信息的能力。
http是不会为了下一次连接而维护这次连接所传输的信息,为了保证服务器内存。
比如客户获得一张网页之后关闭浏览器,然后再一次启动浏览器,再登陆该网站,但是服务器并不知道客户关闭了一次浏览器。
由于Web服务器要面对很多浏览器的并发访问,为了提高Web服务器对并发访问的处理能力,在设计HTTP协议时规定Web服务器发送HTTP应答报文和文档时,不保存发出请求的Web浏览器进程的任何状态信息。这有可能出现一个浏览器在短短几秒之内两次访问同一对象时,服务器进程不会因为已经给它发过应答报文而不接受第二期服务请求。由于Web服务器不保存发送请求的Web浏览器进程的任何信息,因此HTTP协议属于无状态协议(Stateless Protocol)。
HTTP协议是无状态的和Connection: keep-alive的区别:
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系。
HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)。
从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。
注:本篇文章只是对http进行了简单的介绍,如果你想知道http的首部字段是什么意思,Accept、User-Agent、Connection等,https又是什么,欢迎看之后的更新。
转发请注明出处:http://www.cnblogs.com/jycboy/p/http1.html

