
Lucene 6.5.0 入门Demo
Lucene 6.5.0 要求jdk 1.8
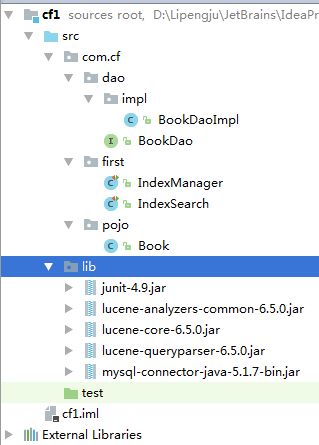
1.目录结构;
2.数据库环境;

private int id; private String name; private float price; private String pic; private String description
3.
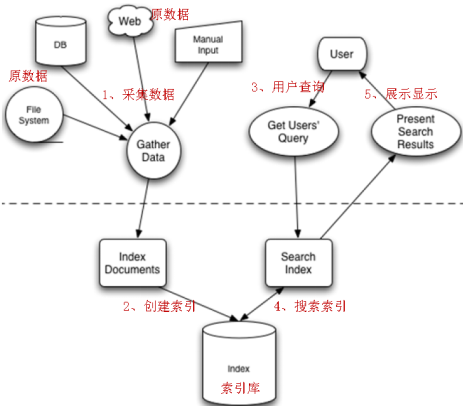
Lucene是Apache的一个全文检索引擎工具包,它不能独立运行,不能单独对外提供服务。
/**
* Created by on 2017/4/25.
*/
public class IndexManager {
@Test
public void createIndex() throws Exception {
// 采集数据
BookDao dao = new BookDaoImpl();
List<Book> list = dao.queryBooks();
// 将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<Document>();
Document document;
for (Book book : list) {
document = new Document();
// store:如果是yes,则说明存储到文档域中
// 图书ID
// Field id = new TextField("id", book.getId().toString(), Store.YES);
Field id = new TextField("id", Integer.toString(book.getId()), Field.Store.YES);
// 图书名称
Field name = new TextField("name", book.getName(), Field.Store.YES);
// 图书价格
Field price = new TextField("price", Float.toString(book.getPrice()), Field.Store.YES);
// 图书图片地址
Field pic = new TextField("pic", book.getPic(), Field.Store.YES);
// 图书描述
Field description = new TextField("description", book.getDescription(), Field.Store.YES);
// 将field域设置到Document对象中
document.add(id);
document.add(name);
document.add(price);
document.add(pic);
document.add(description);
docList.add(document);
}
//JDK 1.7以后 open只能接收Path/////////////////////////////////////////////////////
// 创建分词器,标准分词器
Analyzer analyzer = new StandardAnalyzer();
// 创建IndexWriter
// IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_6_5_0,analyzer);
IndexWriterConfig cfg = new IndexWriterConfig(analyzer);
// 指定索引库的地址
// File indexFile = new File("D:\\L\a\Eclipse\\lecencedemo\\");
// Directory directory = FSDirectory.open(indexFile);
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lpj\\JetBrains\\lucenceIndex1\\"));
IndexWriter writer = new IndexWriter(directory, cfg);
writer.deleteAll(); //清除以前的index
// 通过IndexWriter对象将Document写入到索引库中
for (Document doc : docList) {
writer.addDocument(doc);
}
// 关闭writer
writer.close();
}
}
/**
* Created by on 2017/4/25.
*/
public class IndexSearch {
private void doSearch(Query query) {
// 创建IndexSearcher
// 指定索引库的地址
try {
// File indexFile = new File("D:\\Lpj\\Eclipse\\lecencedemo\\");
// Directory directory = FSDirectory.open(indexFile);
// 1、创建Directory
//JDK 1.7以后 open只能接收Path
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lpj\\JetBrains\\lucenceIndex1\\"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
// 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = searcher.search(query, 10);
// 根据查询条件匹配出的记录总数
int count = topDocs.totalHits;
System.out.println("匹配出的记录总数:" + count);
// 根据查询条件匹配出的记录
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档的ID
int docId = scoreDoc.doc;
// 通过ID获取文档
Document doc = searcher.doc(docId);
System.out.println("商品ID:" + doc.get("id"));
System.out.println("商品名称:" + doc.get("name"));
System.out.println("商品价格:" + doc.get("price"));
System.out.println("商品图片地址:" + doc.get("pic"));
System.out.println("==========================");
// System.out.println("商品描述:" + doc.get("description"));
}
// 关闭资源
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void indexSearch() throws Exception {
// 创建query对象
Analyzer analyzer = new StandardAnalyzer();
// 使用QueryParser搜索时,需要指定分词器,搜索时的分词器要和索引时的分词器一致
// 第一个参数:默认搜索的域的名称
QueryParser parser = new QueryParser("description", analyzer);
// 通过queryparser来创建query对象
// 参数:输入的lucene的查询语句(关键字一定要大写)
Query query = parser.parse("description:java AND lucene");
doSearch(query);
}


