【JDK1.8】JDK1.8集合源码阅读——HashMap
一、前言
笔者之前看过一篇关于jdk1.8的HashMap源码分析,作者对里面的解读很到位,将代码里关键的地方都说了一遍,值得推荐。笔者也会顺着他的顺序来阅读一遍,除了基础的方法外,还添加了很多其他补充内容。
二、HashMap结构概览
以下是HashMap的数据结构:
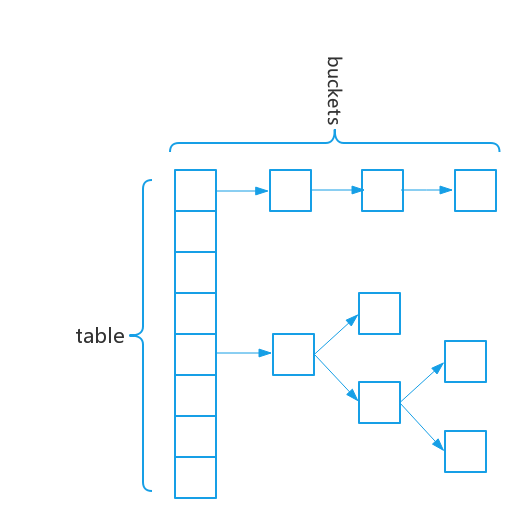
不同于之前的jdk的实现,1.8采用的是数组+链表+红黑树,在链表过长的时候可以通过转换成红黑树提升访问性能。大多数情况下,结构都以链表的形式存在,所以检查是否存在树节点会增加访问方法的时间,但是相较于其优点来说还是可以接受的。特别说明:树结构里还有很多指针引用,这里没画出来。将在后续的LinkedHashMap和TreeMap中讲解
三、HashMap源码阅读
3.1 类的继承关系
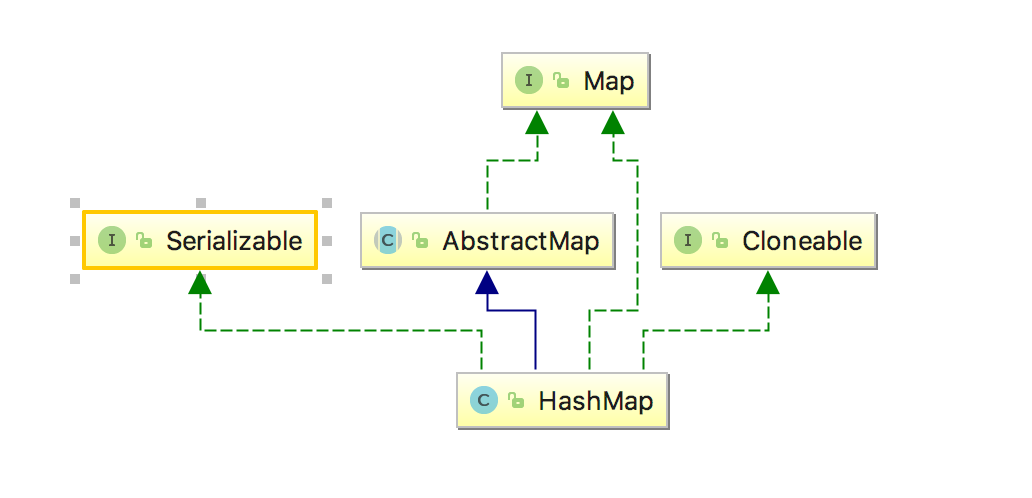
可以看到HashMap继承自AbstractMap,实现了Serializable和Cloneable。这里笔者不打算介绍AbstractMap的源码,因为阅读之后发现比较简单,有兴趣的园友们可以自行去看看,其中的keyset()和values()方法与HashMap中的类似。Serializable接口表示HashMap实现了的序列化,Cloneable接口表示可以合法的调用clone(),如果不实现该接口而调用clone,会报CloneNotSupportedException。关于Map接口的解析,可以看我之前的文章
3.2 HashMap的成员变量
下面我们先来看一下HashMap里面的成员变量:
//默认初始化map的容量:16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//map的最大容量:2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的填充因子:0.75,能较好的平衡时间与空间的消耗
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//将链表(桶)转化成红黑树的临界值
static final int TREEIFY_THRESHOLD = 8;
//将红黑树转成链表(桶)的临界值
static final int UNTREEIFY_THRESHOLD = 6;
//转变成树的table的最小容量,小于该值则不会进行树化
static final int MIN_TREEIFY_CAPACITY = 64;
//上图所示的数组,长度总是2的幂次
transient Node<K,V>[] table;
//map中的键值对集合
transient Set<Map.Entry<K,V>> entrySet;
//map中键值对的数量
transient int size;
//用于统计map修改次数的计数器,用于fail-fast抛出ConcurrentModificationException
transient int modCount;
//大于该阈值,则重新进行扩容,threshold = capacity(table.length) * load factor
int threshold;
//填充因子
final float loadFactor;
可以看到,HashMap里是以Node节点数组的形式存放数据的,Node数据结构比较简单,这里我们也来看一下:
//Entry接口在笔者的总章里有介绍。
static class Node<K,V> implements Map.Entry<K,V> {
// key & value 的 hash值
final int hash;
final K key;
V value;
//指向下一个节点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
由于比较简单,这里就不详细介绍了哈。
3.3 HashMap的构造函数
3.3.1 无参数构造函数
public HashMap() {
//其他成员变量也都是默认的
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
3.3.2 传初始化容量(建议如果知道要使用的map容量,都使用这种)
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
3.3.3 传初始化容量以及填充因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//tableSizeFor()是用来将初始化容量转化大于输入参数且最近的2的整数次幂的数,比如initialCapacity = 7,那么转化后就是8。
this.threshold = tableSizeFor(initialCapacity);
}
tableSizeFor(),将初始化容量转化大于或等于最接近输入参数的2的整数次幂的数:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
|是或运算符,比如说0100 | 0011 = 0111,>>>是无符号右移,忽略符号位,空位都以0补齐,比如说0100 >>> 2 = 0001,现在来说一下这么做的目的:
首先>>>和|的操作的目的就是把n从最高位的1以下都填充为1,以010011为例,010011 >>> 1 = 001001,然后001001 | 010011 = 011011,然后再把011011无符号右移两位:011011 >>> 2 = 000110,然后000110 | 011011 = 011111,后面的4、8、16计算过程就都省去了,int类型为32位,所以计算到16就全部结束了,最终得到的就是最高位及其以下的都为1,这样就能保证得到的结果肯定大于或等于原来的n且为奇数,最后再加上1,那么肯定是:大于且最接近输入值的2的整数次幂的数。
那么为什么要先cap - 1呢,我们可以先思考以下,如果传进来的本身就是2的整数幂次,比如说01000,10进制是8,那么如果不减,得到的结果就是16,显然不对。所以先减1的目的是cap如果恰好是2的整数次幂,那么返回的也是本身。
合起来得到这个tableSizeFor()方法的目的:返回大于或等于最接近输入参数的2的整数次幂的数。另外,笔者特意回去看了JDK1.7的源码,发现1.7用的是roundUpToPowerOf2()方法,里面用到里了>>以及减操作,性能上来说肯定还1.8的高。
3.3.4 传map转化为HashMap的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
putMapEntries():
//evict表示是不是初始化map,false表示是初始化map
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
//获取m中键值对的数量
int s = m.size();
if (s > 0) {
if (table == null) {
//计算map的容量,键值对的数量 = 容量 * 填充因子
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
//如果容量大于了阈值,则重新计算阈值。
if (t > threshold)
threshold = tableSizeFor(t);
}
//如果table已经有,且键值对数量大于了阈值,进行扩容
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
3.4 HashMap中重要的方法解析
3.4.1 get()
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//先是判断一通table是否为空以及根据hash找到存放的table数组的下标,并赋值给临时变量
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//总是先检查数组下标第一个节点是否满足key,满足则返回
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果第一个与key不相等,则循环查看桶
if ((e = first.next) != null) {
//检查是否为树节点,是的话采用树节点的方法来获取对应的key的值
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//do-while循环判断,直到找到为止
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
可以发现源码作者很喜欢在判断的时候赋值,不知道这个是不是个编程的好习惯。!?(・_・;?
3.4.2 put()
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
* @param hash key的hash值
* @param key
* @param value
* @param onlyIfAbsent 如果为true,则在有值的时候不会更新
* @param evict false表示在创建map
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果为空,则扩容。注意这里的赋值操作,关系到下面
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果tab对应的数组位置为空,则创建新的node,并指向它
if ((p = tab[i = (n - 1) & hash]) == null)
// newNode方法就是返回Node:return new Node<>(hash, key, value, next);
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果比较hash值和key的值都相等,说明要put的键值对已经在里面,赋值给e
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果p节点是树节点,则执行插入树的操作
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//不是树节点且数组中第一个也不是,则在桶中查找
else {
for (int binCount = 0; ; ++binCount) {
//找到了最后一个都不满足的话,则在最后插入节点。注意这里的e = p.next,赋值兼具判断都在if里了
if ((e = p.next) == null)
p.next = newNode(hash, key, value, null);
//之前field说明中的,如果桶中的数量大于树化阈值,则转化成树,第一个是-1
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
//在桶中找到了对应的key,赋值给e,退出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//没有找到,则继续向下一个节点寻找
p = e;
}
}
//上面循环中找到了e,则根据onlyIfAbsent是否为true来决定是否替换旧值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//钩子函数,用于给LinkedHashMap继承后使用,在HashMap里是空的
afterNodeAccess(e);
return oldValue;
}
}
//修改计数器+1
++modCount;
//实际大小+1, 如果大于阈值,重新计算并扩容
if (++size > threshold)
resize();
//钩子函数,用于给LinkedHashMap继承后使用,在HashMap里是空的
afterNodeInsertion(evict);
return null;
}
可以看到真正执行put的是里面的putVal()方法。里面的插入逻辑一步步下来还是很清晰的。
3.4.3 resize()
通过调用resize()对map进行扩容操作。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//扩容/缩容前的容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//旧的阈值
int oldThr = threshold;
int newCap, newThr = 0;
//说明之前已经初始化过map
if (oldCap > 0) {
//达到了最大的容量,则将阈值设为最大,并且返回旧的table
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//如果两倍的旧容量小于最大的容量且旧容量大于等于默认初始化容量,则旧的阈值也扩大两倍。
//oldCap << 1,其实就是*2的意思。
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//旧容量为0且旧阈值大于0,则赋值给新的容量(应该是针对初始化的时候指定了其容量的构造函数出现的这种情况)
else if (oldThr > 0)
newCap = oldThr;
//这种情况就是调用无参数的构造函数
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 新阈值为0,则通过:新容量*填充因子 来计算
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//根据新的容量来初始化table,并赋值给table
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//如果旧的table里面有存放节点,则初始化给新的table
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//将下标为j的数组赋给临时节点e
if ((e = oldTab[j]) != null) {
//清空
oldTab[j] = null;
//如果该节点没有指向下一个节点,则直接通过计算hash和新的容量来确定新的下标,并指向e
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//如果为树节点,按照树节点的来拆分
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//e还有其他的节点,将该桶拆分成两份(不一定均分)
else {
//loHead是拆分后的,链表的头部,tail为尾部
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//根据e的hash值和旧的容量做位与运算是否为0来拆分,注意之前是 e.hash & (oldCap - 1)
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
可以看到,resize()方法对整个数组以及桶进行了遍历,极其耗费性能,所以再次强调在我们明确知道map要用的容量的时候,使用指定初始化容量的构造函数。
在resize前和resize后的元素布局如下:
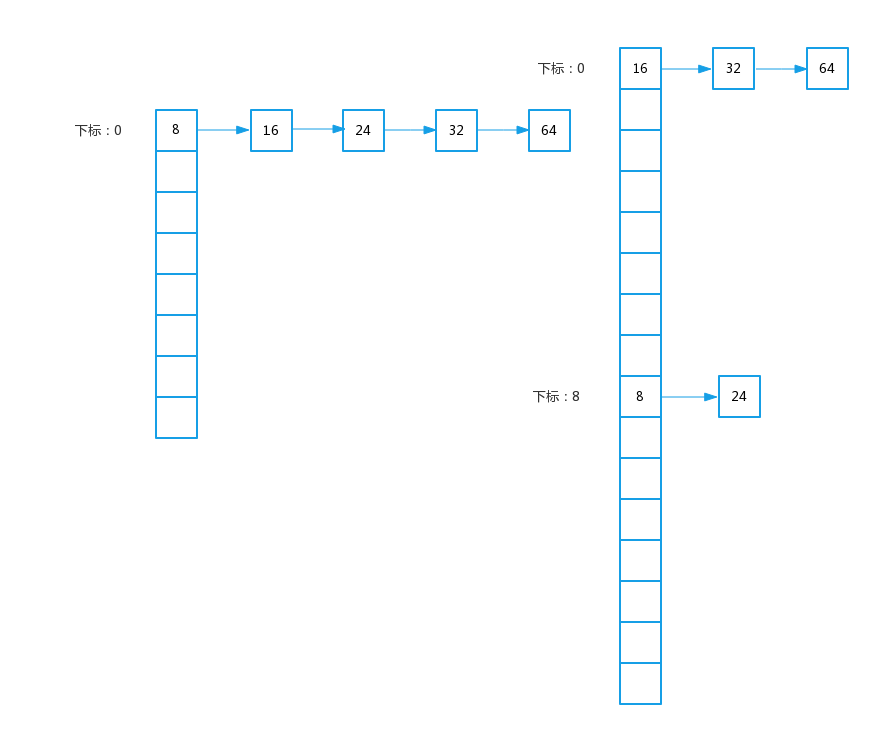
再次强调一下,拆分后的结果不一定是均分,要看你存的值
3.4.4 remove()
public V remove(Object key) {
Node<K,V> e;
//与之前的put、get一样,remove也是调用其他的方法
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash key的hash值
* @param key
* @param value 与下面的matchValue结合,如果matchValue为false,则忽略value
* @param matchValue 为true,则判断是否与value相等
* @param movable 主要跟树节点的remove有关,为false,则不移动其他的树节点
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//老规矩,还是先判断table是否为空之类的逻辑,注意赋值操作
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//对下标节点进行判断,如果相同,则赋给临时节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
//为树节点,则按照树节点的操作来进行查找并返回
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//do-while循环查找
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//如果找到了key对应的node,则进行删除操作
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//为树节点,则进行树节点的删除操作
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//如果p == node,说明该key所在的位置为数组的下标位置,所以下标位置指向下一个节点即可
else if (node == p)
tab[index] = node.next;
//否则的话,key在桶中,p为node的上一个节点,p.next指向node.next即可
else
p.next = node.next;
//修改计数器
++modCount;
--size;
//钩子函数,与上同
afterNodeRemoval(node);
return node;
}
}
return null;
}
这里提到里的remove的话,肯定与之联想到的就是其抛出ConcurrentModificationException。举个栗子:
Map<String, Integer> map = new HashMap<>();
map.put("GoddessY", 1);
map.put("Joemsu", 2);
for (String a : map.keySet()) {
if ("GoddessY".equals(a)) {
map.remove(a);
}
}
这里我们再来看一下其在循环过程中抛出该异常的源码(以keySet()为例):
public Set<K> keySet() {
Set<K> ks;
return (ks = keySet) == null ? (keySet = new KeySet()) : ks;
}
final class KeySet extends AbstractSet<K> {
public final Iterator<K> iterator() { return new KeyIterator(); }
}
final class KeyIterator extends HashIterator implements Iterator<K> {
public final K next() { return nextNode().key; }
}
abstract class HashIterator {
//指向下一个节点
Node<K,V> next;
//指向当前节点
Node<K,V> current;
//迭代前的修改次数
int expectedModCount;
//当前下标
int index;
HashIterator() {
//注意这里:将修改计数器值赋给expectedModCount
expectedModCount = modCount;
//下面一顿初始化。。。
Node<K,V>[] t = table;
current = next = null;
index = 0;
//在table数组中找到第一个下标不为空的节点。
if (t != null && size > 0) {
do {} while (index < t.length && (next = t[index++]) == null);
}
}
//通过判断next是否为空,来决定是否hasNext()
public final boolean hasNext() {
return next != null;
}
//这里就是抛出ConcurrentModificationException的地方
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
//如果modCount与初始化传进去的modCount不同,则抛出并发修改的异常
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//如果一个下标对应的桶空了,则接着在数组里找其他下标不为空的桶,同时赋值给next
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
//使用迭代器的remove不会抛出ConcurrentModificationException异常,原因如下:
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
//注意这里:对expectedModCount重新进行了赋值。所以下次比较的时候还是相同的
expectedModCount = modCount;
}
}
那么我们再回到上面的测试代码,我们再来看一个有趣的问题,如果我把"GoddessY".equals(a)换成"Joemsu".equals(a)还会抛出异常吗?有兴趣的园友们可以试一试,找出原因能够加深对源码的理解!(づ。◕‿‿◕。)づ
3.4.5 treeifyBin()
最后我们再来看一下将桶变成红黑树的代码吧,具体的树结构之类的大概会放在TreeMap里讲解,这里不仔细介绍。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//这里MIN_TREEIFY_CAPACITY派上了用场,及时单个桶数量达到了树化的阈值,总的容量没到,也不会进行树化
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
// 返回树节点 return new TreeNode<>(p.hash, p.key, p.value, next);
TreeNode<K,V> p = replacementTreeNode(e, null);
//为空说明是第一个节点,作为树的根节点
if (tl == null)
hd = p;
//设置树的前后节点
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
//对整棵树进行处理,形成红黑树
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
四、总结
下面是一些关于HashMap的特征:
-
允许key和value为null
-
基本上和Hashtable(已弃用)相似,除了非同步以及键值可以为null
-
不能保证顺序
-
访问集合的时间与map的容量和键值对的大小成比例
-
影响HashMap性能的两个变量:填充因子和初始化容量
-
通常来说,默认的填充因为0.75是一个时间和空间消耗的良好平衡。较高的填充因为减少了空间的消耗,但是增加了查找的时间
-
最好能够在创建HashMap的时候指定其容量,这样能存储效率比使其存储空间不够后自动增长更高。毕竟重新调整耗费性能
-
使用大量具有相同hashcode值的key,将降低hash表的表现,最好能实现key的comparable
-
注意hashmap是不同步的。如果要同步请使用
Map m = Collections.synchronizedMap(new HashMap(...)); -
除了使用迭代器的remove方法外其的其他方式删除,都会抛出ConcurrentModificationException.
-
map通常情况下都是hash桶结构,但是当桶太大的时候,会转换成红黑树,可以增加在桶太大情况下访问效率,但是大多数情况下,结构都以桶的形式存在,所以检查是否存在树节点会增加访问方法的时间
最后谢谢各位园友观看,如果有描述不对的地方欢迎指正,与大家共同进步!
作者:joemsu
出处:http://www.cnblogs.com/joemsu
如果您喜欢我的文章,请不吝点一下“推荐”按钮,您的支持将会是我不竭的动力。
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.

