storm介绍,核心组件,编程模型
一、流式计算概念
利用分布式的思想和方法,对海量“流”式数据进行实时处理,源自业务对海量数据,在“时效”的价值上的挖掘诉求,随着大数据场景应用场景的增长,对流式计算的需求愈发增多,流式计算的一般架构图如下:

Flume获取数据-->Kafka传递数据-->Strom计算数据-->Redis保存数据
二、storm介绍
Apache Storm是一个分布式实时大数据处理系统。Storm设计用于在容错和水平可扩展方法中处理大量数据。它是一个流数据框架,具有最高的摄取率。Storm是无状态的,它通过Apache ZooKeeper管理分布式环境和集群状态。它很简单,您可以并行地对实时数据执行各种操作,成为实时数据分析的领导者。
通俗的说,Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
三、storm应用场景和典型案例
应用场景:
(1)监控日志分析:从海量日志中分析出特定的数据,并将分析的结果用来辅佐决策,或存入外部存储器。
(2)用户行为:实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
(3)用户画像:收集,维护用户兴趣,并在此基础上向对应受众的用户投放不同的数据和信息。
典型案例:
(1)广告投放:为了更加精准投放广告,后台计算引擎需要维护每个用户的兴趣点(理想状态是,你对什么感兴趣,就向你投放哪类广告)。用户兴趣主要基于用户的历史行为、用户的实时查询、用户的实时点击、用户的地理信息而得,其中实时查询、实时点击等用户行为都是实时数据。考虑到系统的实时性,许多厂商使用Storm维护用户兴趣数据,并在此基础上进行受众定向的广告投放
(2)淘宝:实时分析用户行为,将用户搜索的宝贝反馈给搜索引擎,通过实时数据分析,为用户展现最贴近其当前需求的结果,或是卖家在后台看到自己的店铺有巨大的用户访问量,但实际买单却很少,则可以借助此数据分析进行一定的打折促销活动。
(3)大型系统监控:收集和分析系统运行过程中的各指标和产生的日志,进行实时分析处理,并作出下一步的决策或告警。
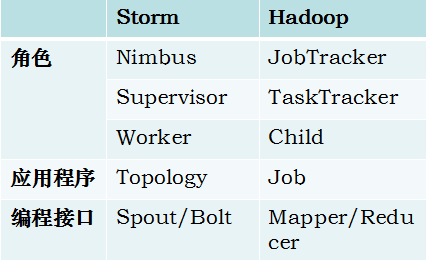
四、storm核心组件
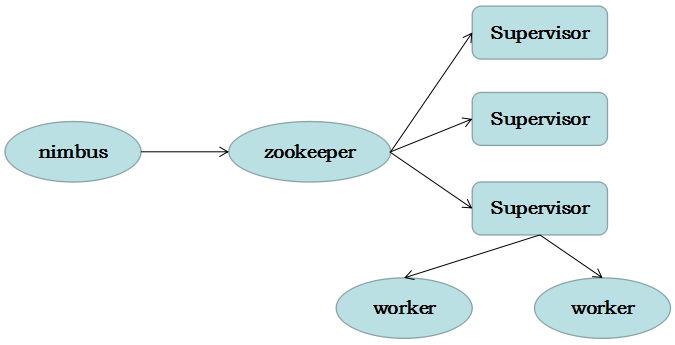
(1)Nimbus:负责资源分配和任务调度。
(2)Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。
(3)Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
(4)Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
五、storm编程模型及Stream Grouping
下面讲述storm的编程模型,同时也是worker的工作流程
Topology:Storm中运行的一个实时应用程序的名称。
Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple,一个Tuple单元会包含一个list对象。
Stream:表示数据的流向。
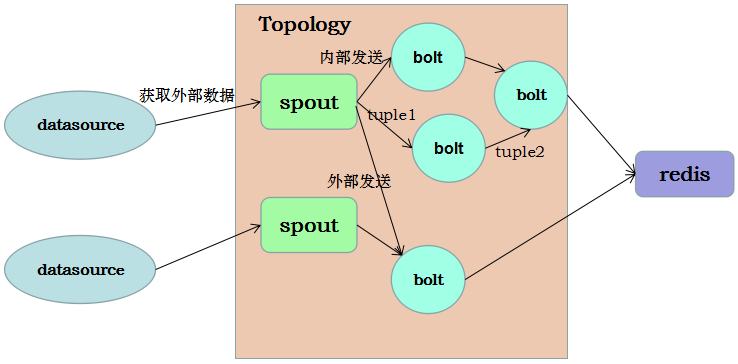
可以注意到,一个spout可以向内部的bolt发送数据,也可以向外部的bolt发送,这里即产生一个数据流向的策略问题,Storm里面有7种类型的stream流向策略Stream Grouping
(1)Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
(2)Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
(3)All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
(4)Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
(5)Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
(6)Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id(OutputCollector.emit方法也会返回task的id)。
(7)Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
六、storm和Hadoop的核心组件对比