


第9章 scrapy-redis分布式爬虫
9-1 分布式爬虫要点
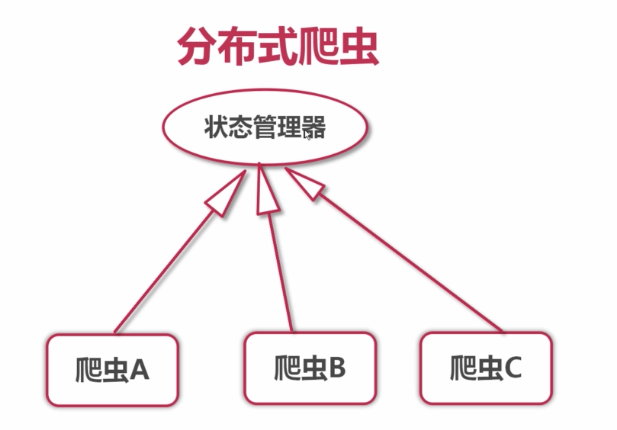
1.分布式的优点
- 充分利用多机器的宽带加速爬取
- 充分利用多机的IP加速爬取速度
问:为什么scrapy不支持分布式?
答:在scrapy中scheduler是运行在队列的,而队列是在单机内存中的,服务器上爬虫是无法利用内存的队列做任何处理,所以scrapy不支持分布式。
2.分布式需要解决的问题
- requests队列集中管理
- 去重集中管理
所以要用redis来解决。
9-2~3 redis基础知识
Ⅰ.redis的安装(windows 64位)
1.百度:redis for windows 找到github上的安装包
如图点进去下载
cmd切换到下载的目录中
输入以下命令即可运行
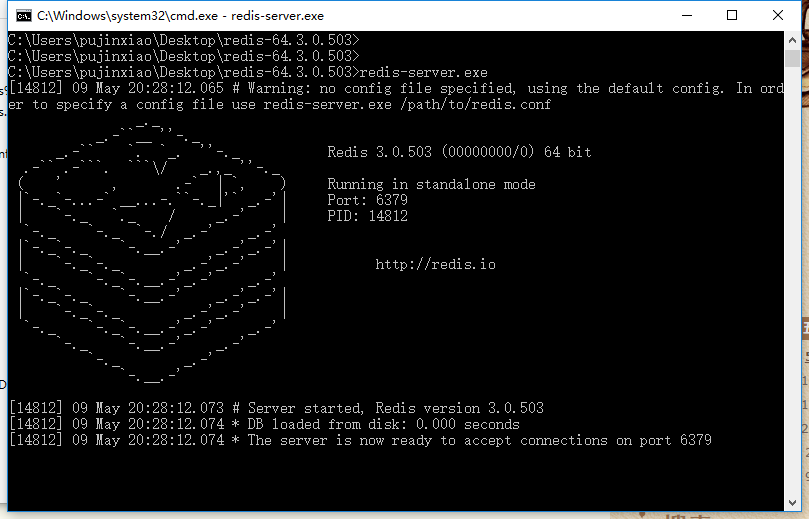

这样已经启动了,可以输入相关的命令进行测试。
Ⅱ、Redis的数据类型
- 字符串
- 散列/哈希
- 列表
- 集合
- 可排序集合
1.字符串命令
set mykey ''cnblogs'' 创建变量
get mykey 查看变量
getrange mykey start end 获取字符串,如:get name 2 5 #获取name2~5的字符串
strlen mykey 获取长度
incr/decr mykey 加一减一,类型是int
append mykey ''com'' 添加字符串,添加到末尾
2.哈希命令
hset myhash name "cnblogs" 创建变量,myhash类似于变量名,name类似于key,"cnblogs"类似于values
hgetall myhash 得到key和values两者
hget myhash name 得到values
hexists myhash name 检查是否存在这个key
hdel myhash name 删除这个key
hkeys myhash 查看key
hvals muhash 查看values
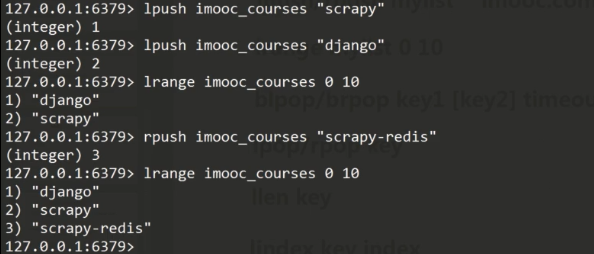
3.列表命令
lpush/rpush mylist "cnblogs" 左添加/右添加值
lrange mylist 0 10 查看列表0~10的值
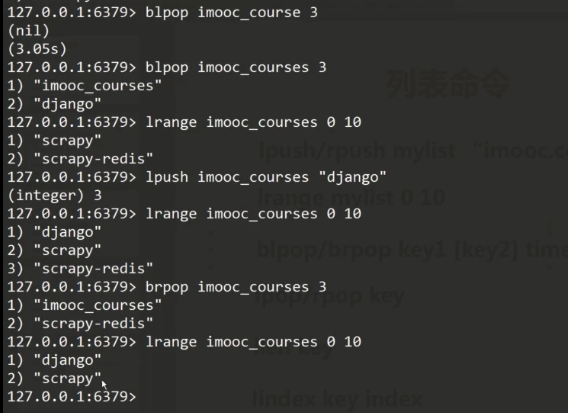
blpop/brpop key1[key2] timeout 左删除/右删除一个,timeout是如果没有key,等待设置的时间后结束。
lpop/rpop key 左删除/右删除,没有等待时间。
llen key 获得长度
lindex key index 取第index元素,index是从0开始的
4.集合命令(不重复)
sadd myset "cnblogs" 添加内容,返回1表示不存在,0表示存在
scard key 查看set中的值
sdiff key1 [key2] 2个set做减法,其实就是减去了交际部分
sinter key1 [key2] 2个set做加法,其实就是留下了两者的交集
spop key 随机删除值
srandmember key member 随机获取member个值
smember key 获取全部的元素
5.可排序集合命令
zadd myset 0 ‘project1’ [1 ‘project2’] 添加集合元素;中括号是没有的,在这里是便于理解
zrangebyscore myset 0 100 选取分数在0~100的元素
zcount key min max 选取分数在min~max的元素的个数
Ⅲ、Redis文档
- redis教程(菜鸟教程)
- redis命令参数
9-4~9 全部的小节主要是解读scrapy-redis
可以看github上的scrapy-redis的使用方法。
bloomfilter 布隆过滤器 集成到scrapy-redis中。
源码还没有理解透彻,先不写说明了。
相关代码的请移步我的github:scrapy-redis应用的项目
作者:今孝
出处:http://www.cnblogs.com/jinxiao-pu/p/6838011.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
觉得好就点个推荐把!

