RNN梯度消失和爆炸的原因 以及 LSTM如何解决梯度消失问题
RNN梯度消失和爆炸的原因
经典的RNN结构如下图所示:
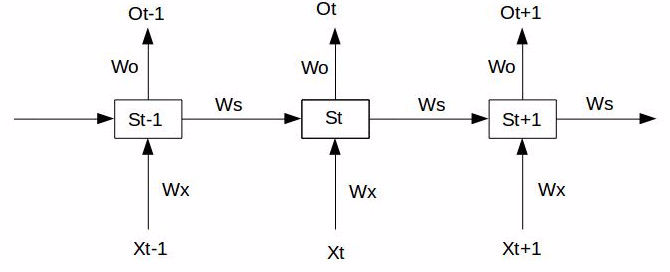
假设我们的时间序列只有三段, 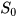 为给定值,神经元没有激活函数,则RNN最简单的前向传播过程如下:
为给定值,神经元没有激活函数,则RNN最简单的前向传播过程如下:
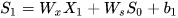
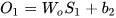
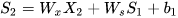
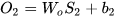
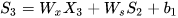
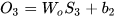
假设在t=3时刻,损失函数为 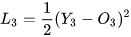 。
。
则对于一次训练任务的损失函数为 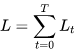 ,即每一时刻损失值的累加。
,即每一时刻损失值的累加。
使用随机梯度下降法训练RNN其实就是对 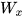 、
、 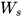 、
、 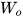 以及
以及 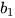
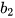 求偏导,并不断调整它们以使L尽可能达到最小的过程。
求偏导,并不断调整它们以使L尽可能达到最小的过程。
现在假设我们我们的时间序列只有三段,t1,t2,t3。
我们只对t3时刻的 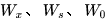 求偏导(其他时刻类似):
求偏导(其他时刻类似):
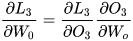
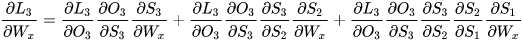
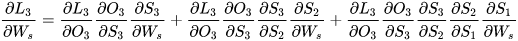
可以看出对于 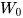 求偏导并没有长期依赖,但是对于
求偏导并没有长期依赖,但是对于 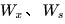 求偏导,会随着时间序列产生长期依赖。因为
求偏导,会随着时间序列产生长期依赖。因为 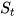 随着时间序列向前传播,而
随着时间序列向前传播,而 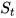 又是
又是 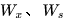 的函数。
的函数。
根据上述求偏导的过程,我们可以得出任意时刻对 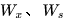 求偏导的公式:
求偏导的公式:
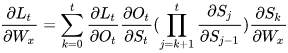
任意时刻对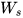 求偏导的公式同上。
求偏导的公式同上。
如果加上激活函数, 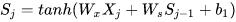 ,
,
则 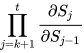 =
= 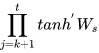
激活函数tanh和它的导数图像如下。
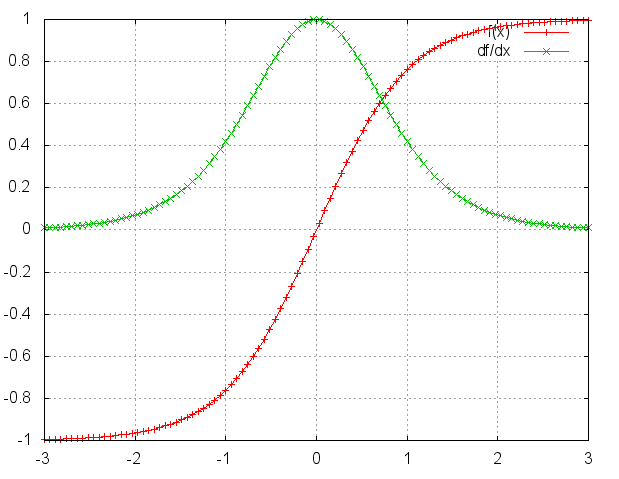
由上图可以看出 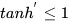 ,对于训练过程大部分情况下tanh的导数是小于1的,因为很少情况下会出现
,对于训练过程大部分情况下tanh的导数是小于1的,因为很少情况下会出现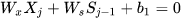 ,如果
,如果 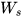 也是一个大于0小于1的值,则当t很大时
也是一个大于0小于1的值,则当t很大时 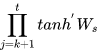 ,就会趋近于0,和
,就会趋近于0,和 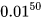 趋近与0是一个道理。同理当
趋近与0是一个道理。同理当 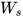 很大时
很大时 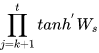 就会趋近于无穷,这就是RNN中梯度消失和爆炸的原因。
就会趋近于无穷,这就是RNN中梯度消失和爆炸的原因。
至于怎么避免这种现象,让我在看看 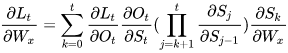 梯度消失和爆炸的根本原因就是
梯度消失和爆炸的根本原因就是 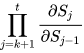 这一坨,要消除这种情况就需要把这一坨在求偏导的过程中去掉,至于怎么去掉,一种办法就是使
这一坨,要消除这种情况就需要把这一坨在求偏导的过程中去掉,至于怎么去掉,一种办法就是使 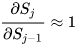 另一种办法就是使
另一种办法就是使 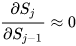 。其实这就是LSTM做的事情。
。其实这就是LSTM做的事情。
LSTM如何解决梯度消失问题
先上一张LSTM的经典图:
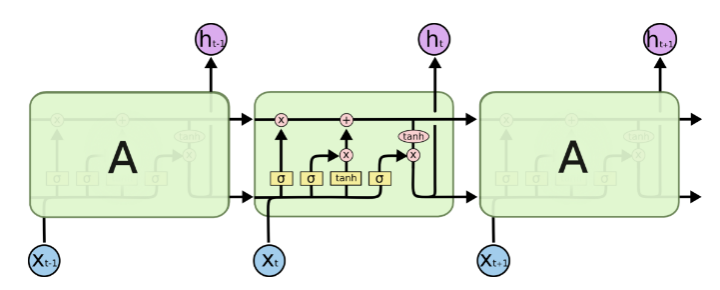
至于这张图的详细介绍请参考:Understanding LSTM Networks
下面假设你已经阅读过Understanding LSTM Networks这篇文章了,并且了解了LSTM的组成结构。
RNN梯度消失和爆炸的原因这篇文章中提到的RNN结构可以抽象成下面这幅图:
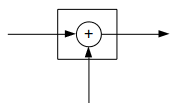
而LSTM可以抽象成这样:
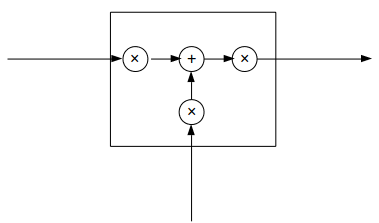
三个×分别代表的就是forget gate,input gate,output gate,而我认为LSTM最关键的就是forget gate这个部件。这三个gate是如何控制流入流出的呢,其实就是通过下面 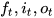 三个函数来控制,因为
三个函数来控制,因为 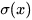 (代表sigmoid函数) 的值是介于0到1之间的,刚好用趋近于0时表示流入不能通过gate,趋近于1时表示流入可以通过gate。
(代表sigmoid函数) 的值是介于0到1之间的,刚好用趋近于0时表示流入不能通过gate,趋近于1时表示流入可以通过gate。
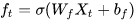
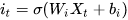
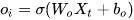
当前的状态 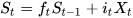 类似与传统RNN
类似与传统RNN 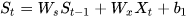 。将LSTM的状态表达式展开后得:
。将LSTM的状态表达式展开后得:
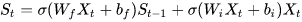
如果加上激活函数, ![S_{t}=tanh\left[\sigma(W_{f}X_{t}+b_{f})S_{t-1}+\sigma(W_{i}X_{t}+b_{i})X_{t}\right]](https://img2018.cnblogs.com/blog/1470684/201905/1470684-20190512212756938-1269577977.png)
RNN梯度消失和爆炸的原因这篇文章中传统RNN求偏导的过程包含 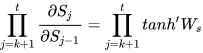
对于LSTM同样也包含这样的一项,但是在LSTM中 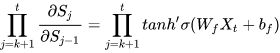
假设 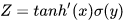 ,则
,则 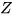 的函数图像如下图所示:
的函数图像如下图所示:
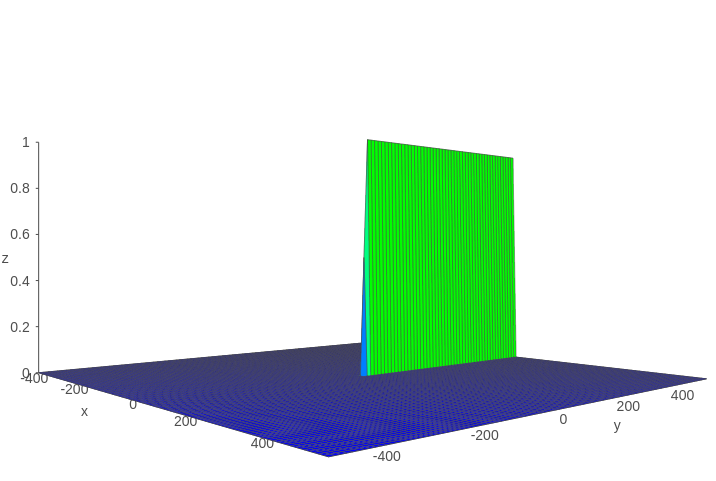
可以看到该函数值基本上不是0就是1。
传统RNN的求偏导过程:
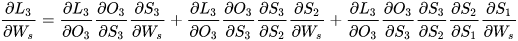
如果在LSTM中上式可能就会变成:
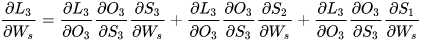
因为 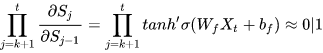 ,这样就解决了传统RNN中梯度消失的问题。
,这样就解决了传统RNN中梯度消失的问题。
https://zhuanlan.zhihu.com/p/28687529
欢迎转载,转载请保留页面地址。帮助到你的请点个推荐。
