

scrapy爬虫部署
在开始之前先要吐槽一下CSDN,昨晚怀着激动得心情写下了我人生中的第一篇博文,今天审核通过后发现所有的图片都不见了,瞬间就不开心了。所以不得不又申请了博客园的账号,重新开始。
前段时间一直研究通用爬虫,做的过程中也是各种问题,不过好在磕磕绊绊搞出点眉目,中间学到了不少东西,感觉互联网真的好神奇。
但是接下来问题来了,写的爬虫不能老在自己机器上跑吧,如何部署到服务器上呢,然后就开始研究scrapyd。网上搜了很多资料,都在介绍scrapy deploy命令,但是我在机器上安装上scrapyd之后,怎么运行都是提示没有deploy这个命令,真是奇怪,为什么别人都可以呢。经过几番波折,终于在最新的官方文档里面找到了答案。附上地址和截图:http://doc.scrapy.org/en/latest/topics/commands.html

原来1.0版本以后这个命令已经废弃了,再一查我安装的版本是1.0.3。然后就根据提示去下载scrapyd-client。
本以为往后就会顺利一点,但是安装了scrapyd-client以后运行,还是一直提示没有scrapy-client命令。群里请教,网上查资料都没有解决,在我快绝望的时候终于在stack overflow上找到了答案。附上地址和截图:http://stackoverflow.com/questions/22646323/windows-scrapyd-deploy-is-not-recognized
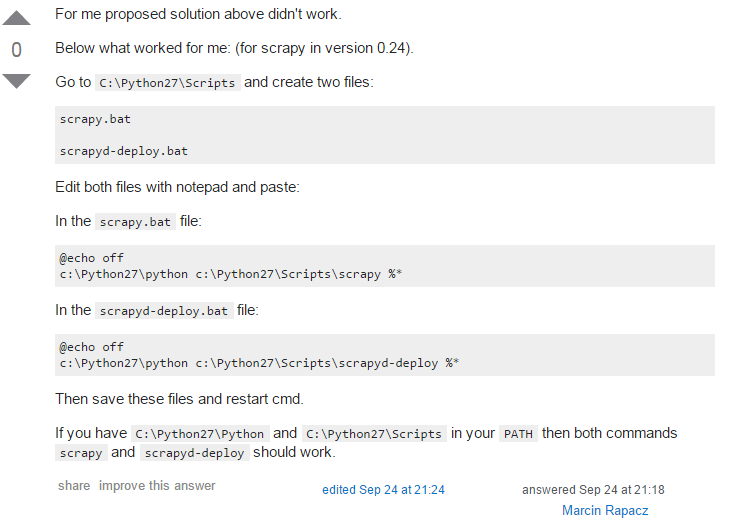
根据人家提供的方法一试,果然OK,感觉SO真的好强大。
解决了以上问题,下面的部署就顺利的多了。记一下以方便以后查阅,也给像我一样的菜鸟一点参考。
我的scrapy.cfg设置如下:
[deploy:scrapyd1]
url = http://192.168.2.239:6800/
project = Crawler
1. 启动scrapyd
在要部署的服务器上启动scrapyd。显示以下内容表示启动成功。

默认的端口是6800。可以在浏览器中查看结果,比如:http://192.168.2.239:6800/。显示效果如下:

可以点击jobs查看爬虫运行情况:
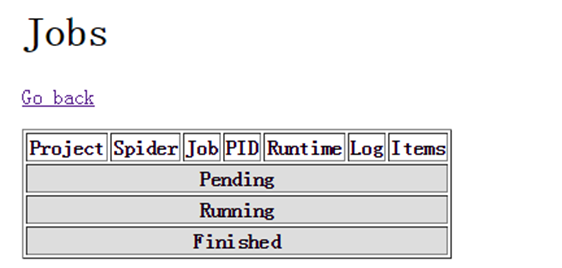
2. 发布工程到scrapyd
scrapyd-deploy <target> -p <project>
首先要切换目录到项目所在路径,然后执行下列指令:
scrapyd-deploy scrapyd1 -p Crawler

3. 验证是否发布成功
scrapyd-deploy -L <target>
如果现实项目名称,表示发布成功。
scrapyd-deploy -L scrapyd1

也可以用scrapyd-deploy -l

4. 启动爬虫
curl http://192.168.2.239:6800/schedule.json -d project=Crawler -d spider=CommonSpider

通过页面可以实时监控爬虫运行效果:

5. 终止爬虫
curl http://192.168.2.239:6800/cancel.json -d project=Crawler -d job= 8270364f9d9811e5adbf000c29a5d5be

部署过程中可能会有很多错误,包括缺少第三方库啥的,自己根据提示即可解决。
以上只是对scrapyd的初步了解,很多深层的内容等慢慢研究以后会持续更新总结。如果以上内容哪里有不对的地方,请各位朋友及时回复交流,小弟在此谢过。
作者:jinhaolin
出处:http://www.cnblogs.com/jinhaolin/>
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出,如有问题,可邮件(woshijinhaolin@163.com)咨询.

