谈谈防御性编程
一提到“防御性编程”,大家都会感觉,这个话题很大,不知从何说起,该说哪些具体内容。
我做这篇文章的源头,是我已经做了很多很多相关前端及后端数据流校验的事情。对测试同学给我提出的所有bug做了整体的统计促使我对“防御性编程”的思考。我想绝大多数的程序bug都是因为代码“防御性”做得不够好而导致的,而导致代码“防御性”不够完善的原因又是多种多样的。
我们做防御性编程,无非一个目的——打造高质量的模块(或程序)。然而,相信大家都清楚,不可能仅凭做好了“防御性”来评价模块(或程序)的质量高与低。同样的,即使我们搭建了十分健壮的代码“防御性”,我们也不可能确保不会有任何bug的产生。
“防御性编程”——它更多的,是一种努力。
一、理解之
引入一篇文章——什么是防御性编程,它对“防御性编程”的定义——
防御性编程是一种细致、谨慎的编程方法。为了开发可靠的软件,我们要设计系统中的每个组件,以使其尽可能地“保护”自己。我们通过明确地在代码中对设想进行检查,击碎了未记录下来的设想。这是一种努力,防止(或至少是观察)我们的代码以将会展现错误行为的方式被调用。
防御性编程是一种编程习惯,是指预见在什么地方可能会出现问题,然后创建一个环境来测试错误,当预见的问题出现的时候通知你,并执行一个你指定的损害控制动作,如停止程序执行,将用户重指向到一个备份的服务器,或者开启一个你可以用来诊断问题的调试信息。
再次思考这个定义,其实它真正要做的,是“当预见的问题出现的时候通知你,并执行一个你指定的损害控制动作”。而对于的性质,可以理解为“是一种努力,是一种编程习惯”。
而对于“防御性编程”的作用,其中的两张图足以说明——
以前可能这样做——
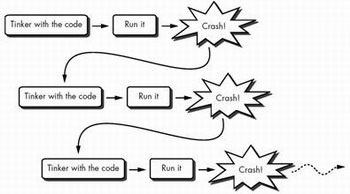
现在可能这样做——

“防御性编程”帮助我们从一开始就编写正确的软件,而不再需要经历“编写-尝试-编写-尝试……”的循环过程。
当然,防御性编程并不能排除所有的程序错误。但是问题所带来的麻烦将会减少,并易于修改。防御性程序员只是抓住飘落的雪花,而不是被埋葬在错误的雪崩中。
防御性编程是一种防卫方式,而不是一种补救形式。
OK,对于“防御性编程”概念的理解就说到这儿。不得不多说的一点是——每种防御性的做法都需要一些额外的工作,从而导致它降低了代码的效率。那么,具体有哪些去做“防御性编程”的技巧呢?
二、使用之
引入文章——防御性编程技巧,直接枚举出里面的技巧——
1> 使用好的编码风格和合理的设计
2> 不要仓促地编写代码
3> 不要相信任何人
4> 编码的目标是清晰,而不是简洁
5> 不要让任何人做他们不该做的修补工作
6> 编译时打开所有警告开关
7> 使用静态分析工具
8> 使用安全的数据结构
9> 检查所有的返回值
10>审慎地处理内存(和其他宝贵的资源)
11>在声明位置初始化所有变量
12>尽可能推迟一些声明变量
13>使用标准语言工具
14>使用好的诊断信息日志工具
15>审慎地进行强制转换
16>其他
a> 审慎地进行强制转换
b> 提供默认的行为
c> 检查数值的上下限
读到每一点,相信共性的问题,大家都亲身接触过,相信大家都有不同的感悟与理解。随着经验的积累,相信大家对具体问题如何去做“防御性”的方式也是不同的。总之,都是对程序的一种努力。
三、数据流处理
都知道“防御性编程”的范围很大,在这里,我想对其中的一点,做深入的研究说明——数据流处理。
拿web请求的流程来讲,用户首先从浏览器端输入数据、触发请求,到服务器端程序接收数据、处理业务逻辑,再到DB库对数据的持久化存储。整个数据流走下来,都需要经历“风风雨雨”的数据流的防御处理过程。
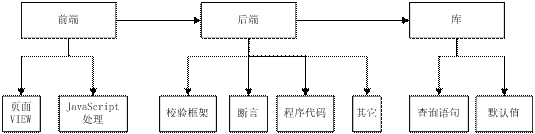
对于前端页面及js对数据流校验的处理,不妨看一下我的这两篇文章——谈谈代码健壮性之前端校验和谈谈代码健壮性之极限值处理(防御性编程)
对于后端(这里主要使用java)的处理,对于数据流的校验,我们多用断言(Assert)来进行校验处理。如——
//字符串propertyName不可为空 Assert.hasText(propertyName); //对象objectName不可为空 Assert.notNull(objectName); //……
我们当然也遇到赋予默认值的情况,如——
String propertyName = (StringUtils.isNotEmpty(name) ? name : null); //......
单单判空远远不够。举个例子,我们限制用户登录密码在6到16位且不可包含“,,.。%$”等特殊字符,具体的后端程序代码实现就不说了。只是想说明的是,可不要因为客户端做了校验,就忘记了在服务器端做校验。
需要额外提的是,对于面向用户的应用来说,我们确实需要在前端及后端同时进行数据流校验,且校验规则是相同的。如果我们的校验规则仅仅去写一次,就能够同时作用于前端及后端,那就很方便去维护了。我们需要一个中间件去配置这些校验的规则。简单举个xml的配置方式,如——
<!-- 这里的form的id对应表单的name属性值 --> <form id="loginForm"> <!-- 这里的name对应页面表单的name属性值,required="true"表示该数据项是必填项,msg代表提示文本 --> <input name="username" required="true" length="1,30" msg="30个字符以内"></input> <input name="password" required="true" length="6,16" msg="6到16个字符以内"></input> </form>
这样,不管是前端还是后端,我们可以通过解析这个xml文件来确保两者的校验规则是相同的。
OK,到这里,后端的数据流处理介绍就到这里了,紧接着就介绍数据库端如何处理数据流了(这里我以mysql为例)。
首先一点,便是插件数据时,对应的每一个数据项的默认值的处理。在创建表的语句中进行添加,如——
CREATE TABLE t_xxx { property_name VARCHAR(255) not NULL DEFAULT '' COMMENT '字段注释', … }
这样也就很大程度上避免了脏数据的存储。再举一个例子,我们在多表连接查询的时候,常常会碰到查询null项,这样我们就会用到查询赋予默认值这样类似的处理了,比如——
SELECT t1.xxx, IFNULL(yyy,0) FROM t1 LEFT JOIN t2 ON t1.id = t2.zzz_id
OK。数据库端的数据流校验处理介绍到这里。
四、总结
先引入这样一句话——
软件滥用者形形色色,从利用程序小缺陷的不守规则的用户,到想尽办法非法进入他人系统的职业黑客。有太多的程序员在不经意间为这些人留下了可随意通过的后门。随着网络化计算机的兴起,粗心大意所带来的后果变得愈来愈显著了。
许多大型软件开发公司终于意识到了这种威胁,开始认真思考这个问题,将时间和资源投入到严谨的防御性编码工作中。
相信大家都能够体会到做好“防御性编程”的重要性。同时,我们需要知道,做好“防御性编程”,我们往往要多花出3倍的时间去处理(远远不单单是数据流的处理,如思考代码严谨性、思考信息提示、思考代码走向等等等等)。
我想最重要的是,如果你想快速开发出高质量的模块,不仅需要经验的不断累积,培养数据流的防御性编程思维同样不可缺少。

