


浮点数的二进制表示学习笔记
转载于http://blog.163.com/yql_bl/blog/static/847851692008112013117685/
因为要参加软考了(当然也只有考试有这种魅力),我得了概浮点数转化为二进制表示这个最难的知识点(个人认为最难)。俺结合大量的从网上收集而来的资料现整理如下,希望对此知识点感兴趣的pfan有所帮助。
基础知识:
十进制转十六进制;
十六进制转二进制;
IEEE制定的浮点数表示规则;
了解:
目前C/C++编译器标准都遵照IEEE制定的浮点数表示法来进行float,double运算。这种结构是一种科学计数法,用符号、指数和尾数来表示,底数定为2——即把一个浮点数表示为尾数乘以2的指数次方再添上符号。下面是具体的规格:
符号位 阶码 尾数 长度
float 1 8 23 32
double 1 11 52 64
以下通过几个例子讲解浮点数如何转换为二进制数
例一:
已知:double类型38414.4。
求:其对应的二进制表示。
分析:double类型共计64位,折合8字节。由最高到最低位分别是第63、62、61、……、0位:
最高位63位是符号位,1表示该数为负,0表示该数为正;
62-52位,一共11位是指数位;
51-0位,一共52位是尾数位。
步骤:按照IEEE浮点数表示法,下面先把38414.4转换为十六进制数。
把整数部和小数部分开处理:整数部直接化十六进制:960E。小数的处理:
0.4=0.5*0+0.25*1+0.125*1+0.0625*0+……
实际上这永远算不完!这就是著名的浮点数精度问题。所以直到加上前面的整数部分算够53位就行了。隐藏位技术:最高位的1不写入内存(最终保留下来的还是52位)。
如果你够耐心,手工算到53位那么因该是:38414.4(10)=1001011000001110.0110011001100110011001100110011001100(2)
科学记数法为:1.001011000001110 0110011001100110011001100110011001100,右移了15位,所以指数为15。或者可以如下理解:
1.001011000001110 0110011001100110011001100110011001100×2^15
于是来看阶码,按IEEE标准一共11位,可以表示范围是-1024 ~ 1023。因为指数可以为负,为了便于计算,规定都先加上1023(2^10-1),在这里,阶码:15+1023=1038。二进制表示为:100 00001110;
符号位:因为38414.4为正对应 为0;
合在一起(注:尾数二进制最高位的1不要):
01000000 11100010 11000001 110 01100 11001100 11001100 11001100 11001100
例二:
已知:整数3490593(16进制表示为0x354321)。
求:其对应的浮点数3490593.0的二进制表示。
解法如下:
先求出整数3490593的二进制表示:
H: 3 5 4 3 2 1 (十六进制表示)
B: 0011 0101 0100 0011 0010 0001 (二进制表示)
│←───── 21────→│
即:
1.1010101000011001000012×221
可见,从左算起第一个1后有21位,我们将这21为作为浮点数的小数表示,单精度浮点数float由符号位1位,指数域位k=8位,小数域位(尾数)n=23位构成,因此对上面得到的21位小数位我们还需要补上2个0,得到浮点数的小数域表示为:
1 0101 0100 0011 0010 0001 00
float类型的偏置量Bias=2k-1-1=28-1-1=127,但还要补上刚才因为右移作为小数部分的21位,因此偏置量为127+21=148,就是IEEE浮点数表示标准:
V = (-1)s×M×2E
E = e-Bias
中的e,此前计算Bias=127,刚好验证了E=148-127=21。
将148转为二进制表示为10010100,加上符号位0,最后得到二进制浮点数表示1001010010101010000110010000100,其16进制表示为:
H: 4 A 5 5 0 C 8 4
B: 0100 1010 0101 0101 0000 1100 1000 0100
|←──── 21 ─────→ |
1|←─8 ─→||←───── 23 ─────→ |
这就是浮点数3490593.0(0x4A550C84)的二进制表示。
例三:
0.5的二进制形式是0.1
它用浮点数的形式写出来是如下格式
0 01111110 00000000000000000000000
符号位 阶码 小数位
正数符号位为0,负数符号位为1
阶码是以2为底的指数
小数位表示小数点后面的数字
下面我们来分析一下0.5是如何写成0 01111110 00000000000000000000000
首先0.5是正数所以符号位为0
再来看阶码部分,0.5的二进制数是0.1,而0.1是1.0*2^(-1),所以我们总结出来:
要把二进制数变成(1.f)*2^(exponent)的形式,其中exponent是指数
而由于阶码有正负之分所以阶码=127+exponent;
即阶码=127+(-1)=126 即 01111110
余下的小数位为二进制小数点后面的数字,即00000000000000000000000
由以上分析得0.5的浮点数存储形式为0 01111110 00000000000000000000000
注:如果只有小数部分,那么需要右移小数点. 比如右移3位才能放到第一个1的后面, 阶码就是127-3=124.
例四 (20.59375)10 =(10100.10011 )2
首先分别将整数和分数部分转换成二进制数:
20.59375=10100.10011
然后移动小数点,使其在第1,2位之间
10100.10011=1.010010011×2^4 即e=4
于是得到:
S=0, E=4+127=131, M=010010011 [感觉有错误!!!!]
最后得到32位浮点数的二进制存储格式为:
0100 1001 1010 0100 1100 0000 0000 0000=(41A4C000)16
例五:
-12.5转为单精度二进制表示
12.5:
1. 整数部分12,二进制为1100; 小数部分0.5, 二进制是.1,先把他们连起来,从第一个1数起取24位(后面补0):
1100.10000000000000000000
这部分是有效数字。(把小数点前后两部分连起来再取掉头前的1,就是尾数)
2. 把小数点移到第一个1的后面,需要左移3位(1.10010000000000000000000*2^3), 加上偏移量127:127+3=130,二进制是10000010,这是阶码。
3. -12.5是负数,所以符号位是1。把符号位,阶码和尾数连起来。注意,尾数的第一位总是1,所以规定不存这一位的1,只取后23位:
1 10000010 10010000000000000000000
把这32位按8位一节整理一下,得:
11000001 01001000 00000000 00000000
就是十六进制的 C1480000.
例六:
2.025675
1. 整数部分2,二进制为10; 小数部分0.025675, 二进制是.0000011010010010101001,先把他们连起来,从第一个1数起取24位(后面补0):
10.0000011010010010101001
这部分是有效数字。把小数点前后两部分连起来再取掉头前的1,就是尾数: 00000011010010010101001
2. 把小数点移到第一个1的后面,左移了1位, 加上偏移量127:127+1=128,二进制是10000000,这是阶码。
3. 2.025675是正数,所以符号位是0。把符号位,阶码和尾数连起来:
0 10000000 00000011010010010101001
把这32位按8位一节整理一下,得:
01000000 00000001 10100100 10101001
就是十六进制的 4001A4A9.
例七:
(逆向求十进制整数)一个浮点二进制数手工转换成十进制数的例子:
假设浮点二进制数是 1011 1101 0100 0000 0000 0000 0000 0000
按1,8,23位分成三段:
1 01111010 10000000000000000000000
最后一段是尾数。前面加上"1.", 就是 1.10000000000000000000000
下面确定小数点位置。由E = e-Bias,阶码E是01111010,加上00000101才是01111111(127),
所以他减去127的偏移量得e=-5。(或者化成十进制得122,122-127=-5)。
因此尾数1.10(后面的0不写了)是小数点右移5位的结果。要复原它就要左移5位小数点,得0.0000110, 即十进制的0.046875 。
最后是符号:1代表负数,所以最后的结果是 -0.046875 。
注意:其他机器的浮点数表示方法可能与此不同. 不能任意移植。
再看一例(类似例七):
比如:53004d3e
二进制表示为:
01010011000000000100110100111110
按照1个符号 8个指数 23个小数位划分
0 10100110 00000000100110100111110
正确的结果转出来应该是551051722752.0
该怎么算?
好,我们根据IEEE的浮点数表示规则划分,得到这个浮点数的小数位是:
00000000100110100111110
那么它的二进制表示就应该是:
1.000000001001101001111102 × 239
这是怎么来的呢? 别急,听我慢慢道来。
标准化公式中的M要求在规格化的情况下,取值范围1<M<(2-ε)
正因为如此,我们才需要对原始的整数二进制表示做偏移,偏移多少呢?偏移2E。
这个“E”怎么算?上面的239怎么得来的呢?浮点数表示中的8位指数为就是告诉这个的。我们知道:
E = e-Bias
那么根据指数位:
101001102=>16610
即e=166,由此算出E=e-Bias=166-127=39,就是说将整数二进制表示转为标准的浮点数二进制表示的时候需要将小数点左移39位,好,我们现在把它还原得到整数的二进制表示:
1 00000000100110100111110 0000000000000000
1│←───── 23─────→│← 16─→│
23+16=39,后面接着就是小数点了。
拿出计算器,输入二进制数1000000001001101001111100000000000000000
转为十进制数,不正是:551051722752么!
通过这例六例七,介绍了将整数二进制表示转浮点数二进制表示的逆过程,还是希望大家不但能掌握转化的方法,更要理解转化的基本原理。
浮点数在计算机中存储方式
作者: jillzhang
联系方式:jillzhang@126.com http://www.cnblogs.com/jillzhang/archive/2007/06/24/793901.html
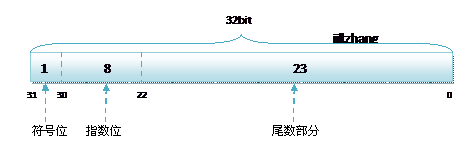
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
而双精度的存储方式为:

R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*![]() ,而120.5可以表示为:1.205*
,而120.5可以表示为:1.205*![]() ,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.0001*
,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.0001*![]() ,1110110.1可以表示为1.1101101*
,1110110.1可以表示为1.1101101*![]() ,任何一个数都的科学计数法表示都为1.xxx*
,任何一个数都的科学计数法表示都为1.xxx*![]() ,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
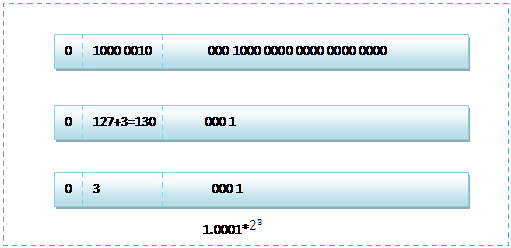
首先看下8.25,用二进制的科学计数法表示为:1.0001*![]()
按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示:
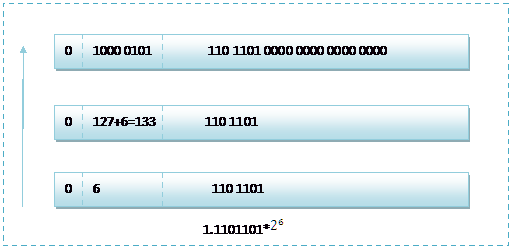
而单精度浮点数120.5的存储方式如下图所示:
那么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:
![]()
根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101*![]() =120.5
=120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的
![]()
下面我就这个基础知识点来解决一个我们的一个疑惑,请看下面一段程序,注意观察输出结果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0 100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2=1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列 00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:
![]()
但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。

