拨开字符编码的迷雾--字符编码概述
拨开字符编码迷雾系列文章链接:
为什么这样的
{"data":"颸颸"}JSON会解析失败?
为什么界面上韩文显示乱码?
ASCII和ANSI有什么区别?
相信不少人在字符编码上面摔过跟头,这篇文章针对开发中需要了解的字符编码知识进行了简要的讲解,希望能够对大家有所帮助。
1. ASCII及其扩展
1.1 什么是ASCII字符集
字符集就是一系列用于显示的字符的集合。ASCII字符集由美国国家标准协会(American National Standard Institute)于1968年制定一个字符映射集合。
ASCII使用7位二进制位来表示一个字符,总共可以表示128个字符(即2^7,二进制000 0000 ~ 111 1111 十进制0~127)。
ASCII字符集中每个数字对应一个唯一的字符,如下表:
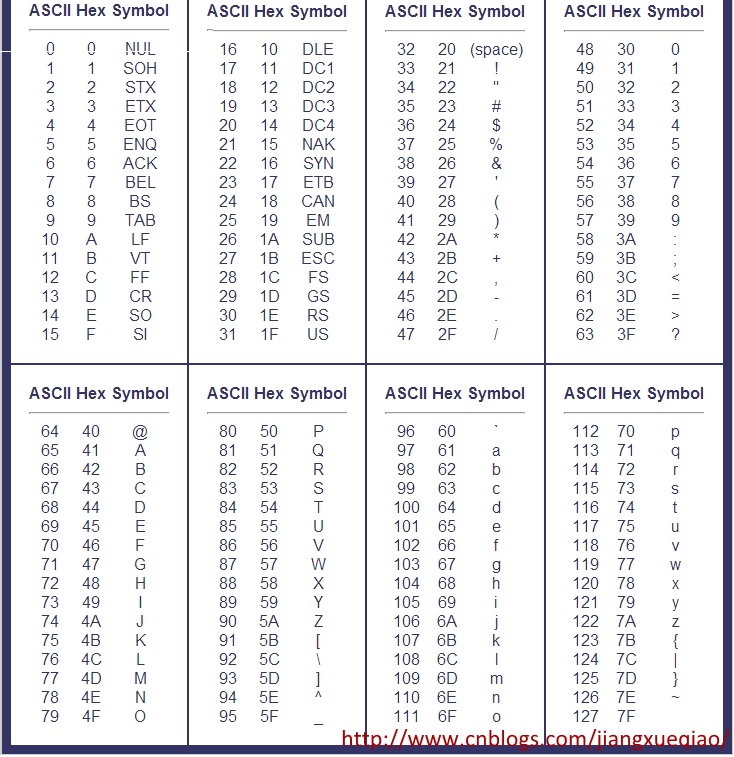
因为其对应关系非常简单,不需要特殊的编码规则,所以严格来讲ASCII不能算字符编码,因为它没有规定编码规则。我们只是习惯将ASCII字符集称之为ASCII码、ASCII编码。
1.2 ASCII的扩展
1.2.1 最高位扩展 - ISO/IEC 8859
ASCII字符集是美国人发明的,这些字符完全是为其量身定制的。但随着计算机技术的发展和普及,传到了欧洲(如法国、德国)各国。由于欧洲很多国家中使用的字符除了ASCII表中的128个字符之外,还有一些各国特有的字符,于是欧洲人民发现ASCII字符集表达不了他们所要表达的东西呀。怎么办了?他们发现ASCII只使用了一个字节(8位)之中的低7位,于是欧洲各国开始各显神通,打起了那1个最高位(第0位)的主意,将最高位利用了起来,这样又多了128个字符,从而满足了欧洲人民的需要。
但因为每个国家的需求不一样,各国都设计了不同的方案。为了结束这种混乱的局面,国际标准化组织(ISO)及国际电工委员会(IEC)联合制定了一系列8位字符集的标准,统称为ISO 8859(全称ISO/IEC 8859)。注意,这是一系列字符集的统称。如ISO/IEC 8859-1(也就是常听到的Latin-1)支持西欧语言,ISO/IEC 8859-4(Latin-4)支持北欧语言等。
完整列表如下(摘自百度百科):
ISO/IEC 8859-1 (Latin-1) - 西欧语言
ISO/IEC 8859-2 (Latin-2) - 中欧语言
ISO/IEC 8859-3 (Latin-3) - 南欧语言,世界语也可用此字符集显示。
ISO/IEC 8859-4 (Latin-4) - 北欧语言
ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
ISO/IEC 8859-6 (Arabic) - 阿拉伯语
ISO/IEC 8859-7 (Greek) - 希腊语
ISO/IEC 8859-8 (Hebrew) - 希伯来语(视觉顺序)
ISO 8859-8-I - 希伯来语(逻辑顺序)
ISO/IEC 8859-9 (Latin-5 或 Turkish) - 它把Latin-1的冰岛语字母换走,加入土耳其语字母。
ISO/IEC 8859-10 (Latin-6 或 Nordic) - 北日耳曼语支,用来代替Latin-4。
ISO/IEC 8859-11 (Thai) - 泰语,从泰国的 TIS620 标准字集演化而来。
ISO/IEC 8859-13 (Latin-7 或 Baltic Rim) - 波罗的语族
ISO/IEC 8859-14 (Latin-8 或 Celtic) - 凯尔特语族
ISO/IEC 8859-15 (Latin-9) - 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元符号。
ISO/IEC 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
我们在数据库中常见到的Latin-1、2、5、7其实就是上面提到的针对特定语言的ASCII扩展字符集。
1.2.2 多字节扩展 - GB系列
前面讲到了,欧洲各国有效利用闲置的最高位,对ASCII字符集进行了扩展。可是欧洲人民没有想到的是(当然他们也不用想这么多),在大洋彼岸有着一个拥有五千年历史的伟大民族,她拥有着成千上万的汉字,1个字节显然不够表达如此深厚的文化底蕴。
于是当计算机引入到中国之初,国家技术监督局就设计了GB系列编码方案(GB=guo biao)。
GB编码方案使用2个字节来表达一个汉字。同时为了兼容ASCII编码,规定各个字节的最高位(首位)必须为1,从而避免了和最高位为0的ASCII字符集的冲突。
GB系列字符集经历下面的几个发展过程:
| 编码名称 | 发布时间 | 字节数 | 汉字范围 |
|---|---|---|---|
| GB2312 | 1980年 | 变字节(ASCII 1字节,汉字2个字节) | 6763个汉字 |
| GB13000 | 1993年第一版 | 变字节(ASCII 1字节,汉字2个字节) | 20902个汉字 |
| GBK | Windows95中 | 2个字节 | 21886个汉字和图形符号(含GB2312,BIG5中所有字符) |
| GB18030 | 2000年第一版 | 变字节(ASCII 1字节,汉字2个或4个字节) | 27484个汉字 |
每一次迭代,支持的字符数量都会增加,而且每一次迭代都会保留之前版本支持的编码,所以做到了向上兼容。
1.2.3 全角与半角
因为汉字在显示器上的显示宽度要比英文字符的宽度要宽一倍,在一起排版显示时不太美观。所以GB编码不仅仅加入了汉字字符,而且包括了ASCII字符集中本来就有的数字、标点符号、字母等字符。这些被编入GB编码的数字、标点、字母在显示器上的显示宽度比ASCII字符集中的宽度宽一倍,所以前者称为全角字符,后者称为半角字符。
2. ANSI
2.1 ANSI与代码页
前面说到了世界各国针对ASCII的扩展方案(如欧洲的ISO/IEC 8859,中国的GB系列等),这些ASCII扩展编码方案的特点是:他们都兼容ASCII编码,但他们彼此之间是不兼容的。微软将这些编码方案统称为ANSI编码。故ANSI并不是特指某一种编码方案,只有知道了在哪个国家,哪个语言环境下,它表示具体的编码方案。
在windows操作系统上,默认使用ANSI来保存文件。那么操作系统是如何知道ANSI到底应该表示哪种编码了,是GBK,还是ASCII,或者还是EUC-KR了? windows通过一个叫"Code Page"(翻译为中文就叫代码页)的东西来判断系统的默认编码。
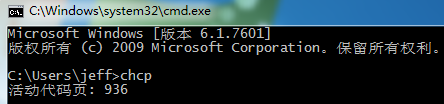
简体中文操作系统默认的代码页是936,它表示ANSI使用的是GBK编码。
GB18030编码对应的windows代码页为CP54936。
可以使用命令 chcp来查看系统默认的代码页:
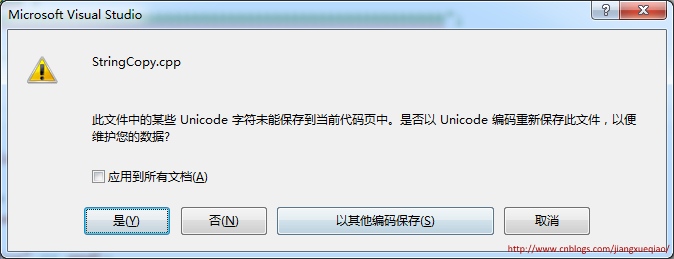
汉字"𤭢"只包含在GB18030中,GB2312、GB13000、GBK中均不包含。默认情况下,在Visual Studio中输入该汉字,visual studio会使用CP936(即GBK)来保存代码文件,但如果在代码文件中输入"𤭢",visual studio弹出如下提示要求用户选择代码页:
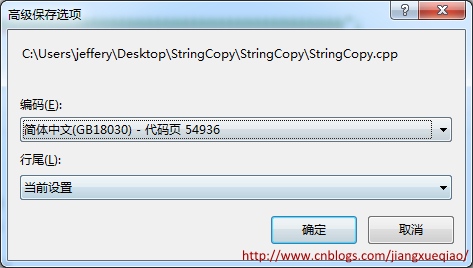
2.2 更改默认代码页
2.2.1 chcp命令
可以使用chcp命令来更改默认代码页,如chcp 437 将默认代码页更改为437(美国)。
2.2.2 控制面板
在“控制面板”-->“区域和语言”--> “更改系统区域设置”中更改系统默认的代码页。
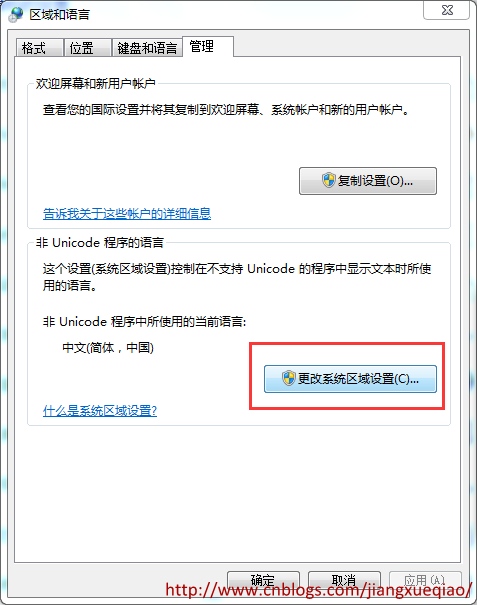
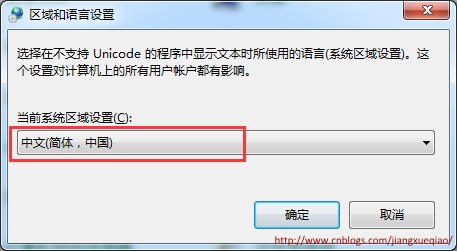
2.2.3 代码修改
也可以通过代码更改默认的代码页:
char *setlocale(
int category,
const char *locale
);
3. Unicode
3.1 Unicode产生背景
各个国家使用不同的编码规则,虽然他们都是兼容ASCII的,但它们相互却是不兼容的。
试想法国人Jack写了一封名为"love_you.txt"的信,传给了他的德国朋友Rose,Rose想要在windows系统上打开这个文件,她需要知道德国使用的字符编码是Latin-1,然后还要确保她的计算机上安装了该编码,才能顺利的打开这个文件。
如果上面这些还能忍受,那么随着网络的发展,你从互联网上获取的文件,你很有可能不知道它来自哪个国家,使用的哪种编码。这也就是Email刚诞生时常常出现乱码的原因,发信人和收信人使用的编码可能是不一样的。
于是The Unicode Standard(统一码标准)横空出世,它由The Unicode Consortium于1991年发布,我们习惯称它为Unicode字符集。
Unicode字符集和ASCII字符集一样,也只是一个字符集合,标记着字符和数字之间的映射关系,它不包含任何编码规则和方案。和ASCII不一样的是,Unicode字符集支持的字符数量是没有限制的(具体可以参考Unicode)。
我们通常认为的Unicode字符固定占用2个字节的观点是错误的。如“𤭢”Unicode码为
D852 DF62。
那么Unicode字符是怎样被编码成内存中的字节的了?它是通过UTF(Unicode Transformation Formats)实现的,比较常见得有UTF-8,UTF-16。
在windows系统上汉字默认使用CP936(即GBK编码),占2个字节。而大多数Unicode字符的Unicode码值也占2个字节,所以大多数人误以为汉字字符串在内存中的值就是Unicode值,这是错误的。
可以从 站长工具-Unicode 查询汉字的Unicode码值。
3.3 字符集与字符编码的区别
从ASCII、GB2312、GBK、GB18030、Big5(繁体中文)、Latin-1等采用的方案来看,它们都只是定义了单个字符与二进制数据的映射关系,一个字符在一个方案中只会存在一种表示方式,所以我们说GB2312是字符集还是字符编码方式都无所谓了。但是Unicode不一样,Unicode作为一个字符集可以采用多种编码方式,如UTF-8, UTF-16, UTF-32等。所以自Unicode出现之后,字符集与字符编码需要明确区分开来。
3.4 UTF-16编码的缺点
UTF-16编码方式规定用两个或四个字节来表示所有的字符。对于ASCII字符保持不变,只是将原来的7位扩展到了16位,其高9位永远是0。如字符'A':
ASCII: 100 0001
UTF-16: 0000 0000 0100 0001
可以看到对于ASCII字符,UTF-16的存储空间扩大了一倍,UTF-16并不是完全兼容ASCII字符集。这对于那些ASCII字符集已经满足需求的西方国家来说完全是没必要的,而且ASCII字符经过UTF-16编码之后高字节始终是0,导致很多C语言函数(如strcpy,strlen)会将此字节视为字符串的结束符'\0',从而出现错误的计算结果。
而且,UTF-16还存在大小端的问题,“𤭢”Unicode码在大端系统上为D852 DF62,小端系统上为52D8 62DF。
因此,UTF-16一开始推出的时候就遭到很多西方国家的抵制,影响了Unicode的推行。于是后来又设计了UTF-8编码方式,才解决了这些问题。
3.5. Unicode字符集常用编码方式:UTF-8
3.5.1 UTF-8概述
UTF-8是互联网上使用最广泛的Unicode字符集编码方式。UTF-8编码的最小单位由8位(1个字节)组成,UTF-8使用一个至四个字节来表示Unicode字符。另外,UTF-8是完美兼容ASCII字符集的,这一点可以通过下面的UTF-8的编码规则得到证明。
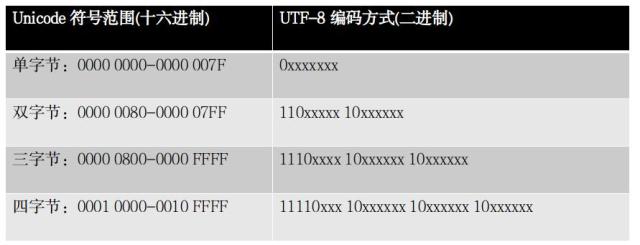
3.5.2 UTF-8编码规则
UTF-8编码规则很简单:
(1)对于ASCII(单字节字符)字符,采用和ASCII相同的编码方式,即只使用一个字节表示,且该字节第一位为0.
(2)对于多字节(2~4字节)字符,假设字节数为n(1<n<=4),第一个字节:前n位都设为1,第n+1位设为0;后面的n-1个字节的前两位一律设为10。所有字节中的没有提及的其他二进制位,全部为这个符号的unicode码。
3.5.2 UTF-8 BOM
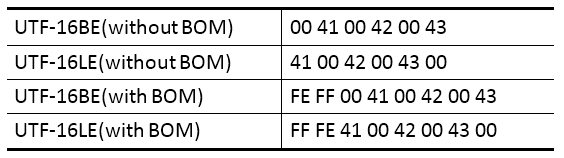
BOM(byte order mark)从字面意义来看是标记字节顺序的。最早出现的原因是因为UTF-16和UTF-32编码采用2个或4个字节表示一个字符,面临大小端的问题。为了区分是使用的大端(Big Endian,简称BE)还是小端(Little Endian,简称LE),采用了在串的前面加入指定的字节加以区分,UTF-16大端加入FE FF,小端加入FF FE. 比如, 字符串“ABC”的UTF-16编码为 00 41 00 42 00 43,对应的各种的字节序列如下:
因为UTF-8和ASCII都是单字节序列,二者不好区分,微软采用在UTF-8编码的字符串前也加入BOM(3个字节EF BB BF)来标记UTF-8编码的串。UTF-8 BOM这一规范大多在windows下被使用,在其他平台下用的很少使用,如:Linux全部采用UTF-8编码,不存在要区分的情况;HTTP协议中可以包含Content-Type:text/html; charset=utf-8这样的说明,也不需要区分。
