JavaWeb基础—MySQL入门小结
一、数据库概述
RDBMS:关系型数据库管理系统 == 管理员(manager)+仓库(database)
常见数据库:
Oracle(神喻):甲骨文
MySQL: 归于甲骨文旗下(高版本系统已经开始收费)
DB2: IBM旗下
SQL Server:微软旗下
二、MySQL安装与卸载
安装MySQL:(安装目录不能有空格或者中文)——安装过程请勾选必要的几个勾:一个允许他人访问的勾,一个开启命令行的勾
选择几个next后选择custom(自定义),一般安装路径不用自己折腾,就把前面C盘的盘符改成D F等就OK
安装完后进行配置MySQL(精细配置),没有自动弹出找安装路径的bin目录下的Config开始配置
先选择开发者(内存占用低)、选择多用途、表空间最好不改,访问上限自定义、后项不变
然后选择编码(最后一个自定义utf8 没有-)
密码若出现三个框框,说明之前没有卸载干净!
最后四个对号才说明通过,否则重新卸载重装 root root
卸载MySQL:先停止服务(cmd或服务里点击停止)。
控制面板里添加和卸载程序进行卸载
再找到安装目录删除整个MySQL文件夹
再进C盘 C://programFile/MySQL删除数据目录
再清理注册表,运行regedit,找MACHINE/SYSTEM/CurrentcontrolSet/Services
找MACHINE/SYSTEM/controlSet001/Services
找MACHINE/SYSTEM/controlSet002/Services
找到后找到MySQL,删除整个目录
MySQL目录:
Service5.5的bin目录下mysqld 服务里查找有它则正常启动,服务端程序
mysql 客户端程序(可多开)
my.ini 配置信息(默认端口3306)
data目录,数据库的文件信息
开启——net start mysql

Q:cmd中输入net start mysql 提示:服务名无效 请键入NET HELPING 2185以获得更多的帮助 A:服务列表里没有MySQL服务,故出现该错误。
先根据错误信息排错,查找服务列表是否有相关服务(win+X),例如mysql5.7将服务名变更为MySQL57
请进入MySQL的bin目录,并在bin目录打开命令行窗口,
在命令行窗口输入:mysqld --install,回车,提示:Service successfully installed。表示安装MySQL服务成功,
命令行窗口输入:net start mysql ,可以正常启动。
(在bin目录快速打开命令行窗口小技巧:在bin目录上先按下shift,在单击右键,则右键菜单栏中多了很多菜单项,选择“在此处打开命令行窗口”即可。)
登陆——mysql -u -p进行登陆
退出 ——exit或者quit
三、SQL入门
【SQL】结构化查询语言,用来操作服务器的(ISO国际标准化组织,熟悉的8859-1...)——由IBM研发,IBM的大力支持是其成功发展的关键!
SQL标准:
SQL1——于89年发布(主要基于DB2 SQL),称为SQL-89
SQL2——于92年发布,称为SQL-92
注意:除了 SQL 标准之外,大部分 SQL 数据库程序都拥有它们自己的私有扩展!
【更新】:mysql的注释:
//在mysql中如何写注释语句 mysql> SELECT 1+1; # 这个注释直到该行结束 mysql> SELECT 1+1; -- 这个注释直到该行结束 mysql> SELECT 1 /* 这是一个在行中间的注释 */ + 1;
然后各大数据库实现的时候还留了一些"方言"
语法要求:
1.单行或者多行,分号结尾
2.MySQL不区分大小写,但建议大写
分类:
DDL(****):(Definition)数据库定义语言
:建、删、改表
DCL(****):(Control)数据库控制语言
:定义访问权限和安全级别
DML(****):(Manipulation)数据库操作语言
:增删改等对表记录的操作
DQL(**):(不是标准):(Query)数据库查询语言
:对记录的查询
1.DDL:
【更新】:示例DDL(请在写DDL时尽量加上必要的注释,必要的字段)——示例来自jeesite:
CREATE TABLE `test_data` (
`id` varchar(64) COLLATE utf8_bin NOT NULL COMMENT '编号',
`user_id` varchar(64) COLLATE utf8_bin DEFAULT NULL COMMENT '归属用户',
`office_id` varchar(64) COLLATE utf8_bin DEFAULT NULL COMMENT '归属部门',
`area_id` varchar(64) COLLATE utf8_bin DEFAULT NULL COMMENT '归属区域',
`name` varchar(100) COLLATE utf8_bin DEFAULT NULL COMMENT '名称',
`sex` char(1) COLLATE utf8_bin DEFAULT NULL COMMENT '性别',
`in_date` date DEFAULT NULL COMMENT '加入日期',
`create_by` varchar(64) COLLATE utf8_bin NOT NULL COMMENT '创建者',
`create_date` datetime NOT NULL COMMENT '创建时间',
`update_by` varchar(64) COLLATE utf8_bin NOT NULL COMMENT '更新者',
`update_date` datetime NOT NULL COMMENT '更新时间',
`remarks` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '备注信息',
`del_flag` char(1) COLLATE utf8_bin NOT NULL DEFAULT '0' COMMENT '删除标记',
PRIMARY KEY (`id`),
KEY `test_data_del_flag` (`del_flag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='业务数据表';
一、数据库的操作([]内为可选操作(实际选择时不要打这个方括号[])
查看所有数据库:SHOW DATABASES
切换数据库:USE 数据库名称
创建数据库:CREATE DATABASE 新数据库名 [CHARSET=UTF8]
删除数据库:DROP DATABASE 将删的数据库
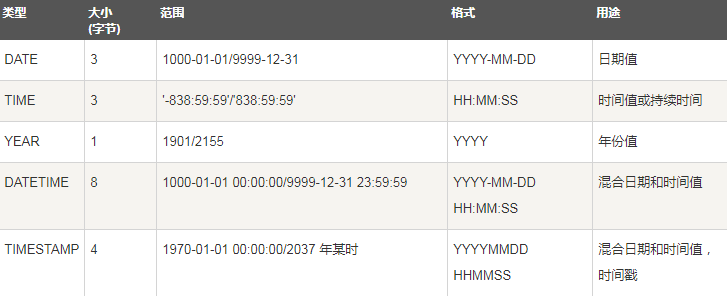
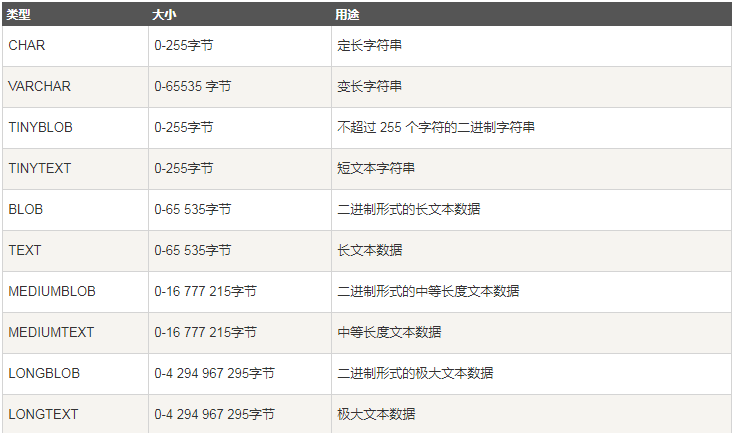
二、数据类型
【更新】:Mysql数据类型更多介绍请参见:http://www.cnblogs.com/linguoguo/p/4092209.html

三、对表的操作
一般而言,每张表必备主键字段id,还有一些应当加上的必备字段:
protected String remarks; // 备注 protected User createBy; // 创建者 protected Date createDate; // 创建日期 protected User updateBy; // 更新者 protected Date updateDate; // 更新日期 protected String delFlag; // 删除标记(0:正常;1:删除;2:审核)
创建表(记得进入数据库USE) CREATE TABLE 表名(
名称 类型,
名称 类型,
...
)
查看表结构 DESC 表名
删除表 DROP 表名
修改表 ALTER TABLE 表名 ADD ();其它MODIFY等类同
2.DML:【在数据库中字符串类型甚至时间类型都需要使用'',不使用双引号,字段不要使用,VALUES使用】
一、增加记录
INSERT INTO 表名 (列名1,列名2) VALUES('值1','值二')
没有给定的列默认值为NULL
没有给出列名直接给出VALUES,默认所有列。(不推荐)
二、修改记录
UPDATE 表名 SET 列名 = 列值 WHRER 列名= 列值
UPDATE stu SET sex = 'female' WHERE sname = 'zhangsan' OR ...注意单引号
BETWEEN ... AND,当然也可以用>= and <=
IN('','')后面跟一集合,满足一即可
判断为空不能用= 必须用is ,比如age = null;本身就是false,必须用age is null
若不加条件则为所有
三、删除记录
DELETE FROM 表名 WHERE 条件
3.DCL;一般一个项目创建一个用户
一、创建用户
CREATE USER 用户名@IP地址 IDENTIFIED BY '密码'
登陆需要把上一个退出exit(quit)
若改成 用户名@'%' 则用户不受IP限制
二、给用户授权
GRANT 权限1...权限n(select,delete,update...甚至all等的权限) ON 数据库.* TO 用户名@IP地址
GRANT CREATE,ALTER,DROP,INSERT,UPDATE,DELETE,SELECT ON mydb1.* TO user1@localhost;
三、撤销授权
REVOKE 权限1...权限n(select,delete,update...甚至all等的权限) ON 数据库.* FROM 用户名@IP地址
四、查看权限
SHOW GRANTS FOR 用户名@IP地址
五、删除用户
DROP USER 用户名@IP地址
4.DQL:(只做查询的事,不做数据库的改动操作等)
一、字段控制:
SELECT 列 FROM 表 WHERE 条件
先把三个关键字列出,对应填入列名、表名等
查询所有列:
SELECT * FROM emp;
查询指定列:
SELECT 列1,列2 FROM emp
完全重复的记录只记录一次
SELECT DISTINCT job FROM emp(查询一列的时候可能用到)
列运算:
原始(+一行对比)SELECT *,sal FROM emp
工资涨50%
SELECT *,sal*1.5 FROM emp;
由于任意值+NULL都为NULL,使用一个if处理NULL
SELECT *,sal+ifnull(con,0) FROM emp;若为NULL,当作0处理
MySQL 不支持+进行字符串的拼接,连接使用CONCAT(name,id)函数
SELECT CONCAT(name,id) as '别名' FROM emp;直接空格也表示后面的是别名
条件查询:注意与或非的选择 AND OR 等 注意中文的和、还有翻译成OR等的,注意斟酌
SELECT * FROM emp WHERE sal>1000;
SELECT * FROM emp WHERE con IS NOT NULL //查询不符合某些结果的直接在WHERE 后面取个反 WHERE NOT ...
SELECT * FROM emp WHERE job IN('','',...); //查询一列的条件考虑
模糊查询:关键字 LIKE 注意两个特殊字符_ %
SELECT * FROM emp WHERE ename LIKE '张_'
记住下划线,一个下划线表示张后面再加一个字符。张__
%匹配任意个字符 如查名字末尾带刚的 LIKE '%刚' 上同理
灵活使用,如查询2000年入职的员工,模糊查询使用2000-开头的
SELECT * FROM emp WHERE time LIKE '2000-%';
排序:
关键字 ORDER BY 排序列 如:ORDER BY sal
升降序 默认升序
升序 ORDER BY sal ASC
降序 ORDER BY sal DESC
多列排序(首列未出结果)
SELECT * FROM emp ORDER BY sal ASC,con DESC
二、聚合函数(纵向运算,工资总和等)
l COUNT():统计指定列不为NULL的记录行数;
l MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
l MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
l SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
l AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
三、分组查询 关键字GROUP BY ,一般与聚合函数合起来使用才有意义
分组是什么?所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。——一般适用于关键字“每”
【更新】:分组请参见:http://www.cnblogs.com/allensun-193/p/5897925.html
查询的必须是组信息,查询各个部门,每个部门等的联想分组,使用别名
关键字的先后排序
SELECT
FROM
WHERE 查询数据——过滤特定的行
HAVING 筛选数据——常跟聚合函数,过滤特定的组
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
ORDER BY
示例SQL:
select avg(Degree) from score where Cno like '3%' and group by Cno having count(*)>=5
SELECT 分组列,聚合函数 聚合函数 ... FROM emp GROUP BY 分组列
SELECT job,count(*) 别名 FROM emp GROUP BY job;
可以在分组前进行一些条件的筛选 WHERE
求显示工资大于10000的按职业划分的部门的数量
SELECT job,count(*) FROM emp WHERE sal>10000 GROUP BY job;
还可以加一些分组后的条件,要求显示工资大于10000的人数不低于2人的部门信息
SELECT job,count(*) FROM emp WHERE sal>10000 GROUP BY job HAVING COUNT(*)>=2;
四、LIMIT ——Mysql方言
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,
第一个参数指定第一个返回记录行的偏移量,
第二个参数指定返回记录行的最大数目
LIMIT 限定查询的起始行以及总行数(0起始)
SELECT * FROM emp LIMIT 5,8 第6行开始查,要8行
每页8行,第17页
SELECT * FROM LIMIT (17-1)*8,8
MySQL编码问题:
查看编码(DOS下):SHOW VARIABLES LIKE 'char%'; 查看以char开头的变量
要注意的编码:client 客户端 结果集 results
设置临时编码:SET character_set_client = utf8;
SET character_set_client = utf8;
但是每次关完窗口就又回去了
设置永久编码:配置文件的修改 my.ini
[client]
port=3306
[mysql]
default-character-set=utf8
client results connection三个都变了
修改完后重启完成配置信息的生效
MySQL的数据备份与恢复:
数据库->sql语句
sql->数据库
核心就是数据库与SQL脚本的互转
使用命令行:(无需登录,下面已经登陆了) 注意不要加:
备份:mysqldump -u -p -h 数据库名>生成的SQL脚本路径
恢复:mysql -u -p -h 数据库名<SQL文件路径
注意<>的区分,恢复的是数据库的内容,可以新建数据库恢复内容
也可以使用登陆后的source命令
source SQL文件路径 如:source c:/1.sql
约束:(加在列上约束列上的)
主键约束(唯一标识)
**唯一**
**非空**
**被引用**
创建主键 CREATE TABLE stu (
name char(20) PRIMARY KEY,
...
或者
PRIMARY KEY(name);
)
修改主键:ALTER TABLE 表名 ADD PRIMARY KEY(主键);
删除主键:ALTER TABLE 表名 DROP PRIMARY KEY
主键自增长:CREATE TABLE 表名(
id INT PRIMARY KEY AUTO_INCREMENT
)
自然主键(身份证号) VS 代理主键(ID) 为了保证逻辑上的正确 不妨使用UUID作为主键
非空约束
name INT NOT NULL 非空但是可重复
唯一约束
name INT UNIQUE
概述模型、对象模型、关系模型
概念模型:在Java中称为实体类
实体之间存在着关系:
1对1:不常见,从表的主键即是外键
1对多:常见 需要建立一张关系表,作为专门存外键的
多对多
双向关联
外键必须引用主键 (另外一张表的主键值)
外键可以重复
外键可以为空(刚报名的学生还没班级)
总之外键需有一个依赖的表,当然这个表可以是本身
创建外键的语句
foreign key(o_buyer_id) references s_user(u_id), #外链到s_user表的u_id字段
更为规范的推荐写法是给外键起个名字:
CONSTRAINT fk_t_user FOREIGN KEY(u_id) REFERENCES t_user(uid)
多表查询:
多表查询字段都应该使用表进行选中 e.ename d.deptno
多注意别名的选取,注意IFNULL的情况
条件一定切记去除笛卡尔积
1.合并结果集(了解)
2.连接查询
3.子查询
1.合并结果集
要求两表列类型和列数量要一样,即两表结构要相同
使用关键字UNION ALL 不加ALL完全相同的结果集会被合并
SELECT * FROM ab;
UNION ALL
SELECT * FROM cd;
SQL2的交并补:但是MYSQL没有实现差集、交集
关于使用纯SQL的实现,可以参考:http://www.linuxidc.com/Linux/2014-06/103551.htm

2.连接查询
1.内连接 (自然连接): 只有两个表相匹配的行才能在结果集中出现
方言:SELECT * FROM 表1 别名1,表2,别名2 ,生成笛卡尔积的表(乘积效果的表)
没用信息太多,叫条件去除 WHERE 别名1.depto=别名2.depto
记得多表带个前缀
标准形式【推荐】:SELECT * FROM 表1 别名1 INNER JOIN 表2 别民2 ON 别名1.xx=别名2.xx
(标准的使用ON,链了一张表马上用ON),基本是见名知意
自然连接:SELECT * FROM 表1 别名2 NATURAL JOIN 表2 别名2
大家也都知道,连接查询会产生无用笛卡尔积,我们通常使用主外键关系等式来去除它。而自然连接无需你去给出主外键等式,它会自动找到这一等式:
l 两张连接的表中名称和类型完成一致的列作为条件
2.外连接
左外连接,以左为主,不满足条件时使用NULL补位,当然可以使用IFNULL函数替换NULL值
SELECT a.aid,IFNULL(c.cid,'无ID') FROM ab a LEFT OUTER JOIN cd c ON a.aid=c.cid;
SELECT * FROM 表1 别名1 LEFT OUTER JOIN 表2 别名2 ON 别名1.xx = 别名2.xx
【更新】:如何连接多字段
SELECT * FROM customer c LEFT JOIN user u ON c.cid = u.uid LEFT JOIN items i ON c.cid = i.iid (举例稍显不当)
右外连接,右表为主
右 RIGHT 外OUTER 连接JOIN 条件ON
全外连接 通过合并结果集,合并左外右外 使用UNION
3.子查询
不知道另外一张表的信息,通过子查询解决
一条SQL语句中有多个SELECT关键字,就是二次查询
可以出现的位置:FROM 后(查询结果还是一张表) WHRER后
例:查询工资最高的人的全部信息(依照之前的,又不能在条件中使用聚合函数)
SELECT * FROM WHERE sal=MAX(sal);错误
SELECT * FROM emp WHERE sal=(SELECT MAX(sal FROM emp));
例:大于平均工资的全部员工
SELECT * FROM emp WHERE sal>(SELECT AVG(sal) FROM emp);
查询结果是一列多行的结果集时,在查询结果前可以加关键字ALL ANY等
SELECT * FROM emp WHERE (job,sal) IN (SELECT job,sal FROM emp WHERE name='张三');少见
单表的多次查询 自连接
SELECT * FROM emp e1,emp e2 再利用条件去除笛卡尔积
查询三步走:列(哪些列) 表(哪些表) 条件(什么条件)
存储过程和函数参见:http://www.cnblogs.com/4php/p/4109491.html
MySQL索引请参见:http://database.51cto.com/art/201505/476869.htm
索引需要注意的地方:
1.对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。
比如我们对title,content 添加了复合索引
select * from table_name where title = 'test';会用到索引
select * from table_name where content = 'test';不会用到索引
2.对于使用like的查询,查询如果是 ‘%a’不会使用到索引 ,而 like 'a%'就会用到索引。最前面不能使用%和_这样的变化值
3.如果条件中有or,即使其中有条件带索引也不会使用。
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步