
[Bayesian] “我是bayesian我怕谁”系列 - Variational Inference
涉及的领域可能有些生僻,骗不了大家点赞。但毕竟是人工智能的主流技术,在园子却成了非主流。
不可否认的是:乃值钱的技术,提高身价的技术,改变世界观的技术。
写在前面
关于变分,通常的课本思路是:
GMM --> EM --> VI --> Variational Bayesian Gaussian Mixture
GMM是个好东西,实用的模型,也是讲解收敛算法的一个好载体。
关于这部分内容,如果你懂中文,推荐一个人,徐亦达老师。中文教学,亲手推算公式给读者的视频,是需要珍惜和珍藏的。
因为提供了ppt,也有配套的视频,于是上半年将链接中的内容都走了一遍,感觉棒棒哒~
基本上涵盖了该领域主流技术七成的基础内容,同时也节省了我大量的时间,学完后内力通常都能提高一两成的样子。
再次道一句:“好人一生平安“
GMM --> EM
From: http://www-staff.it.uts.edu.au/~ydxu/ml_course/em.pdf
解决的问题也很简单,一堆点,你通过平移或是缩放,用几个高斯去拟合数据。到底用几个高斯,这是个问题,而且是个高级问题。能提出这个问题,说明你是一只有潜力变成凤凰的菜鸡。
我们目前先考虑采用固定个数的高斯去”尽量地”拟合。
已知高斯的个数
这里“通过肉眼”观察然后知道了“是三个高斯”。

Figure, fitting with three Gaussian distribution
注意,这里的高斯是多维高斯;
总有人说数学基础很重要,确实如此,问问自己两个最最基本的问题:
- 多维高斯的表达形式是?
- 有一个满足多维高斯的变量x,那么x2满足的分布以及参数是?
暂时不会也没关系,毕竟不是每个人都想当牛人拿高薪求创业。怕得就是不愿懂但还是想当牛人拿高薪求创业的孩子们。
如何懂?可以拿一本《多元变量分析》or《矩阵论》打基础。
公式解析
说到底,就是个如何估参的问题。
考虑每个点属于各个高斯的概率。

公式1
图中的每个点,你可以说属于任何一个高斯,只是概率不同罢了。
自然而然地,需要加上一个隐变量z来表示这个意思: p(Z|X, Θ) #某个点X属于哪一个高斯的概率

公式2:更新θ
关于这个更新theta的公式,其实这么想会容易理解一些:
A君:我觉得目前的Θ(g)已经是最优了。
B君:真得?如果你说的没错,那么argmax后对p(Z,X|Θ)中Θ的求解结果就应该是你说的这个最优Θ(g),你确定?赌一把?
A君:这个嘛,你说的没错,如果得出的结论Θ(g+1)不等于我这个最优Θ(g),那么我就说错了,得修正Θ(g) = Θ(g+1)。
B君:问题来了,我也不知道如此更新下去,收敛的目的地是否是最优的Θ。
A君:恩,需要去证明。
B君:是的。
权衡关系
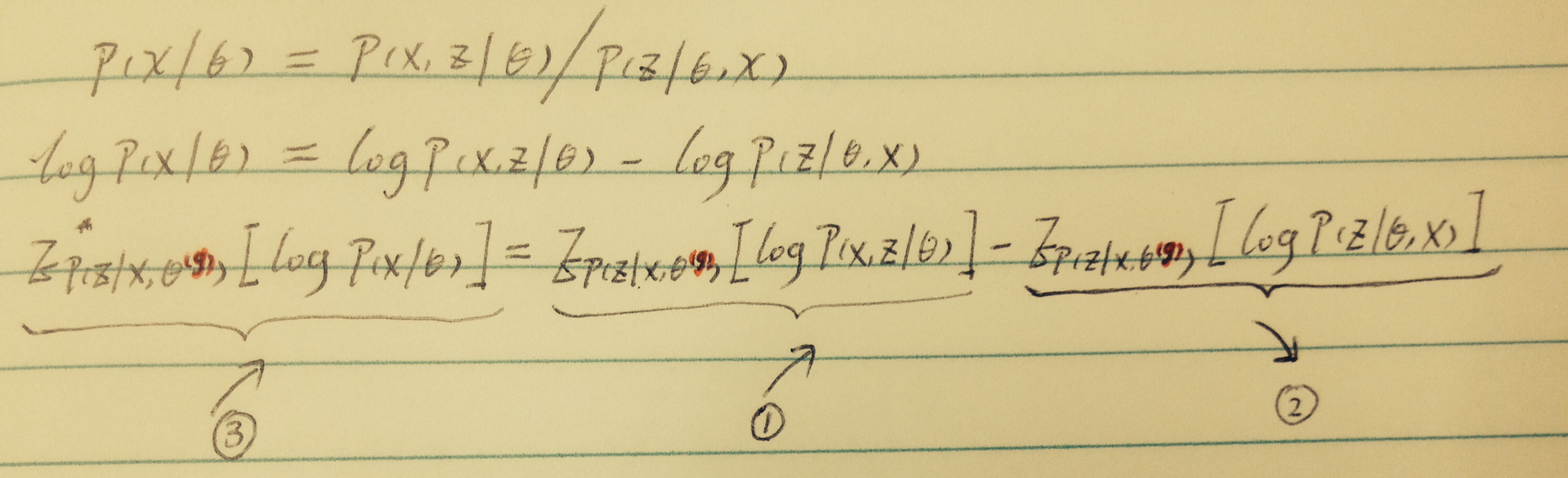
3涨是目的;更新Θ后,若1涨,2跌就能达到目的
先证明了:只要θ在变,【2】就会跌;【详见原视频讲解,有用到Jensen's inequality】
所以,【1】涨【3】肯定也涨。
那么,如何让【1】涨呢?这不就是【公式2】的意思么(argmax)!
注意数学基础,【公式2】就是【1】部分,只是表达方式不同,一个是期望的形式,一个是积分的形式。
【公式2】中明显有两个概率,把每个概率展开,写出具体的形式:

Likelihood 形式
把这个具体的形式带入【公式2】,然后……<看视频中计算过程>……,【公式2】变为了:

这就是EM方法中的likelihood,使其最大化即可;同时也是更新θ的公式。
通常,有了likelihood也就有了一切,之后求导便是。
对谁求导?你想优化谁就对谁求导!
要优化谁?当然是θ这个向量代表的各个具体的参数咯!
Θ = {α1, . . . αk , µ1, . . . µk , Σ1, . . . Σk }
EM过程
既然是EM,那么,
Iterate:
1. [E-step] Infer missing values {latent variables} given current parameters --> 根据公式求p(Z|X,θ),其实有点高斯采样的感觉,得到了下图中每个采样点的p(l|Xi,θ(g))
2. [M-step] Optimize parameters {θ} given the “filled-in” data --> 套入下面公式即可;公式通过求导的结果而来,具体会用到“拉格朗日乘子法+KKT条件”

就是这么一回事,感觉也没什么可说。 但细细想来有一个问题,上述过程中涉及到大量的贝叶斯定理,也就会有求后验分布这样的过程,如果涉及的分布不是高斯这样的友好分布,导致求后验分布困难,那上述的这段流程岂不是走不下来了么?
整体思路
简单易懂的理解变分其实就是一句话:用简单的分布q去近似复杂的分布p。
首先,为什么要选择用变分推断?
因为,大多数情况下后验分布很难求啊。如果后验概率好求解的话我们直接EM就搞出来了。
当后验分布难于求解的时候我们就希望选择一些简单的分布来近似这些复杂的后验分布,至于这种简单的分布怎么选,有很多方法比如:Bethe自由能,平均场定理。而应用最广泛的要数平均场定理。为什么?
因为它假设各个变量之间相互独立砍断了所有变量之间的依赖关系。这又有什么好处呢?
我们拿一个不太恰当的例子来形象的说明一下:用古代十字军东征来作为例子说明一下mean field。十字军组成以骑兵为主步兵为辅,开战之前骑兵手持重标枪首先冲击敌阵步兵手持刀斧跟随,一旦接战就成了单对单的决斗。那么在每个人的战斗力基本相似的情况下某个人的战斗力可以由其他人的均值代替这是平均场的思想。这样在整个军队没有什么战术配合的情况下军队的战斗力可以由这些单兵的战斗力来近似这是变分的思想。
当求解Inference问题的时候相当于积分掉无关变量求边际分布,如果变量维度过高,积分就会变得非常困难,而且你积分的分布p又可能非常复杂因此就彻底将这条路堵死了。采用平均场就是将这种复杂的多元积分变成简单的多个一元积分,而且我们选择的q是指数族内的分布,更易于积分求解。如果变量间的依赖关系很强怎么办?
那就是structured mean field解决的问题了。
说到这里我们就知道了为什么要用变分,那么怎么用?
过程很简单,推导很复杂。整个过程只需要:
- 根据图模型写出联合分布
- 写出mean filed 的形式(给出变分参数及其生成隐变量的分布)
- 写出ELBO(为什么是ELBO?优化它跟优化KL divergence等价,KL divergence因为含有后验分布不好优化)
- 求偏导进行变分参数学习
EM --> VI
From: http://www-staff.it.uts.edu.au/~ydxu/ml_course/variational.pdf
该页表述很清晰,p是未知的真实分布,如何找一个q分布来尽可能地近似p,以下就是理论依据。
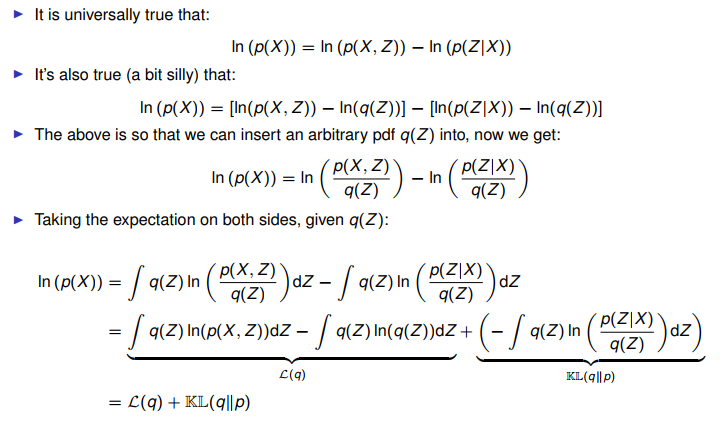
Figure, ln (p(X)) = Evidence Lower Bound (ELOB) + KL divergence
近似方法
做一个iid假设来近似真实分布p:
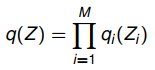
之后,将L(q)替换为iid假设后,成为如下形式。

Figure, Evidence Lower Bound (ELOB)
到此,菜鸡可能会有点迷惑,这么做到底为了什么?不用怕,其实当初我也迷惑,:)
但到此,我们至少知道做了一个iid的假设,这个很重要,记住这一步。
那么,为了理解这个假设,趁热先直接上个例子如何:[Bayes] Variational Inference for Bayesian GMMs
链接中的目的:
-
- 推导出近似各个变量的公式。
为什么不能用EM?
-
- 例子中涉及的分布除了高斯还有好多,情况太复杂,一看就是后验不好求。
为什么要折腾这个复杂的东东?
-
- 示意图很明了,与普通GMM相比,模型加了dirichlet,就跟突然有了大脑。
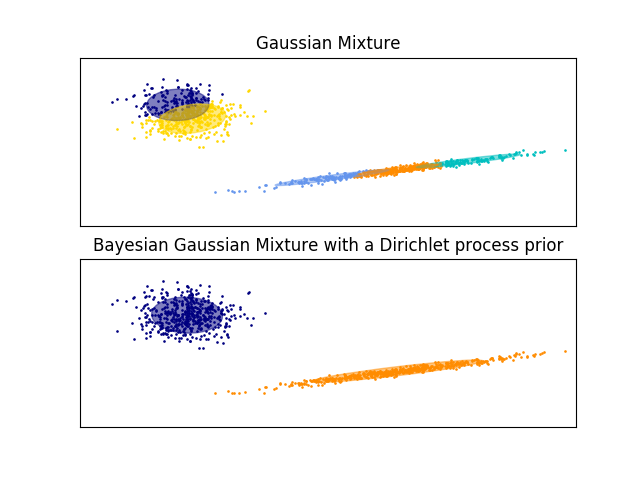
变分的必要性
看来,模型加了先验(变得复杂),对 performance 确实有莫大的好处。
模型复杂就不好估参,其中后验计算复杂也是原因之一。
看上去,变分推断的必要性成了显而易见的常识。
写到这里,希望菜鸡对变分有了更深的认识,本文的初衷不是教材,更多的是充当tutor,帮助大家理清思路,加深认识,建立知识体系。
“学习”这种东西,最终还是自己的事儿,但“引导”确实需要他人来给予。
书归正传,这个结论就是使用变分的核心:
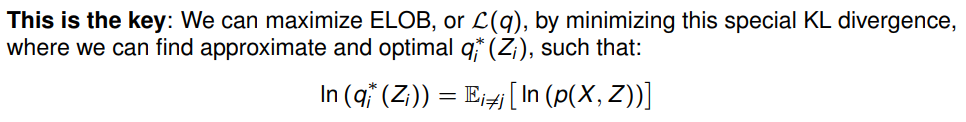
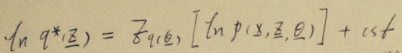
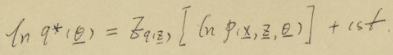
迭代过程:注意一一对应的关系,变量命名有区别,注意分辨
求近似公式的方法用起来很方便啊,如何得到的呢?
这就要回头到 Figure, Evidence Lower Bound (ELOB) ,继续我们的思路。
“做了一个iid的假设,这个很重要”,实例中也就是:

为什么一定要做这个假设?
因为变分中迭代过程两部分变量的关系:第一部分迭代结果给第二部分;第二部分迭代结果给第一部分;
当然,这两部分变量要假设为iid咯。
突然,就这么好理解了……
至于具体的原理推导过程,在此不添加“网络信息冗余”,建议看原视频讲解。
VI --> Variational Bayesian GMM
From: http://www.cnblogs.com/jesse123/p/7501743.html
Ref: 公式推导过程
这部分内容得请高人,为什么会自动调整拟合混合分布,涉及到Dirichlet process的研究,读者姑且把Dirichlet看做是每个高斯的权重调整,就相当于图像中的透明属性。
不太清楚目前研究的进展如何,理论基础可能还未完备,但实践效果往往挺好。
不管是GMM还是Variational Bayesian GMM,都是一种聚类方法,聚类方法除了贝叶斯统计派,还有其他很多种,如下:
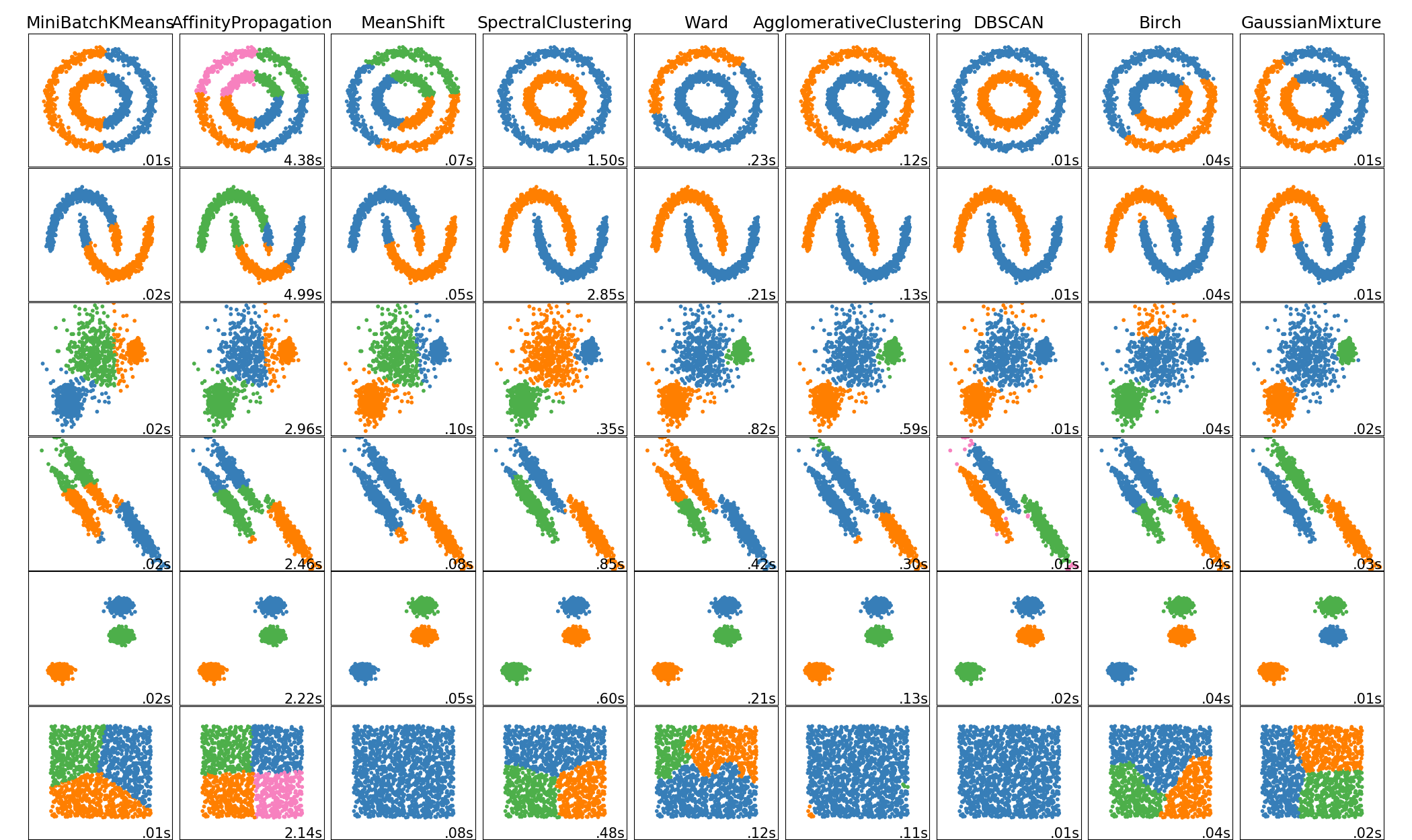
Comparing different clustering algorithms on toy datasets
本篇就到这里,关于变分的使用,未来还会有涉及,慢慢体会。
愿菜鸡们建立起人工智能的知识体系,与硅谷接轨,而非被路人忽悠。
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号