
[Tensorflow] Object Detection API - retrain mobileNet
前言
一、专注话题
- 重点话题
Retrain mobileNet (transfer learning).
Train your own Object Detector.
这部分讲理论,下一篇讲实践。
- 其他资料
Convolutional neural networks on the iPhone with VGGNet
看上去有实践借鉴价值:
http://blog.csdn.net/muwu5635/article/details/75309434
https://github.com/zunzhumu/darknet-mobilenet
Google’s MobileNets on the iPhone
Image retraining
一、概念
- Tensorflow tutorial
参考:tensorflow tutorial,有借鉴价值。
https://www.tensorflow.org/tutorials/image_retraining
- 与 Fine-tuning 之区别
Ref: https://stackoverflow.com/questions/45134834/fine-tuning-vs-retraining
[Fine-tuning]
Usually in the ML literature we call fine tuning the process of:
- Keep a trained model. Model = feature extractor layers + classification layers
- Remove the classification layers
- Attach new classification layer 【清空最后一层】
- Retrain the whole model end-to-end. 【训练整个网络】
This allow to start from a good configuration of the feature extract layers weights and thus reach an optimum value in a short time.
You can think about the fine tuning like a way to start a new train with a very good initialization method for your weights (although you have to initialize your new classification layers).
[Retraining]
When, instead, we talk about retrain of a model, we usually refer to the the process of:
- Keep a model architecture
- Change the last classification layer in order to produce the amount of classes you want to classify 【只改变最后一层】
- Train the model end to end.
In this case you don't start from a good starting point as above, but instead you start from a random point in the solution space.
This means that you have to train the model for a longer time because the initial solution is not as good as the initial solution that a pretrained model gives you.
二、论文
2017.4 release,https://arxiv.org/pdf/1704.04861.pdf

三、应用
Not hot dog: June 23, 2017,The app is available in the Play Store today.

From: https://techcrunch.com/2017/06/28/thinking-about-hotdogs/
Fortunately, Google had just published their MobileNets paper, putting forth a novel way to run neural networks on mobile devices. The solution presented by Google offered a middle ground between the bloated Inception and the frail SqueezeNet. And more importantly, it allowed Anglade to easily tune the network to balance accuracy and compute availability.
Anglade used an open source Keras implementation from GitHub as a jumping off point. He then made a number of changes to streamline the model and optimize it for a single specialized use case.
The final model was trained on a dataset of 150,000 images.
A majority, 【40:1】
-
- 147,000 images, were not hotdogs,
- 3,000 of the images were of hotdogs.
This ratio was intentional to reflect the fact that most objects in the world are not hotdogs.
You can check out the rest of the story here, where Anglade discusses all of his approach in detail. He goes on to explain a fun technique for using CodePush to live-inject updates to his neural net after submitting it to the app store. And while this app was created as a complete joke, Anglade saves time at the end for an insightful discussion about the importance of UX/UI and the biases he had to account for when during the training process.
三、训练
- 不能从轮子开始训练
How HBO’s Silicon Valley built “Not Hotdog” with mobile TensorFlow, Keras & React Native
直接使用传统网络,不太适合
It only took a day of work to integrate TensorFlow’s Objective-C++ camera example in our React Native shell.
It took slightly longer to use their transfer learning script, which helps you retrain the Inception architecture to deal with a more specific image problem. Inception is the name of a family of neural architectures built by Google to deal with image recognition problems. Inception is available “pre-trained” which means the training phase has been completed and the weights are set. Most often for image recognition networks, they have been trained on ImageNet, a yearly competition to find the best neural architecture at recognizing over 20,000 different types of objects (hotdogs are one of them). However, much like Google Cloud’s Vision API, the competition rewards breadth as much as depth here, and out-of-the-box accuracy on a single one of the 20,000+ categories can be lacking.
- 迁移学习 / retraining
As such, retraining (also called “transfer learning”) aims to take a full-trained neural net, and retrain it to perform better on the specific problem you’d like to handle. This usually involves some degree of “forgetting”, either by excising entire layers from the stack, or by slowly erasing the network’s ability to distinguish a type of object (e.g. chairs) in favor of better accuracy at recognizing the one you care about (i.e. hotdogs).
While the network (Inception in this case) may have been trained on the 14M images contained in ImageNet, we were able to retrain it on a just a few thousand hotdog images to get drastically enhanced hotdog recognition.
The big advantage of transfer learning are you will get better results much faster, and with less data than if you train from scratch. A full training might take months on multiple GPUs and require millions of images, while retraining can conceivably be done in hours on a laptop with a couple thousand images.
- 重难点在哪里
One of the biggest challenges we encountered was understanding exactly what should count as a hotdog and what should not.
Defining what a “hotdog” is ends up being surprisingly difficult (do cut up sausages count, and if so, which kinds?) and subject to cultural interpretation.
【不同形态的同一个object是否可以直接当成是多个目标来识别,这样可以么?】
Similarly, the “open world” nature of our problem meant we had to deal with an almost infinite number of inputs.
While certain computer-vision problems have relatively limited inputs (say, x-rays of bolts with or without a mechanical default), we had to prepare the app to be fed selfies, nature shots and any number of foods.
Suffice to say, this approach was promising, and did lead to some improved results, however, it had to be abandoned for a couple of reasons.
First The nature of our problem meant a strong imbalance in training data: there are many more examples of things that are not hotdogs, than things that are hotdogs.
In practice this means that if you train your algorithm on 3 hotdog images and 97 non-hotdog images, and it recognizes 0% of the former but 100% of the latter, it will still score 97% accuracy by default! This was not straightforward to solve out of the box using TensorFlow’s retrain tool, and basically necessitated setting up a deep learning model from scratch, import weights, and train in a more controlled manner.
At this point we decided to bite the bullet and get something started with Keras, a deep learning library that provides nicer, easier-to-use abstractions on top of TensorFlow, including pretty awesome training tools, and a class_weights option which is ideal to deal with this sort of dataset imbalance we were dealing with.
- 需要适合手机的CNN
We used that opportunity to try other popular neural architectures like VGG, but one problem remained. None of them could comfortably fit on an iPhone.
They consumed too much memory, which led to app crashes, and would sometime takes up to 10 seconds to compute, which was not ideal from a UX standpoint. Many things were attempted to mitigate that, but in the end it these architectures were just too big to run efficiently on mobile.
四、小网络:Keras & SqueezeNet 方案
- 参数、指标
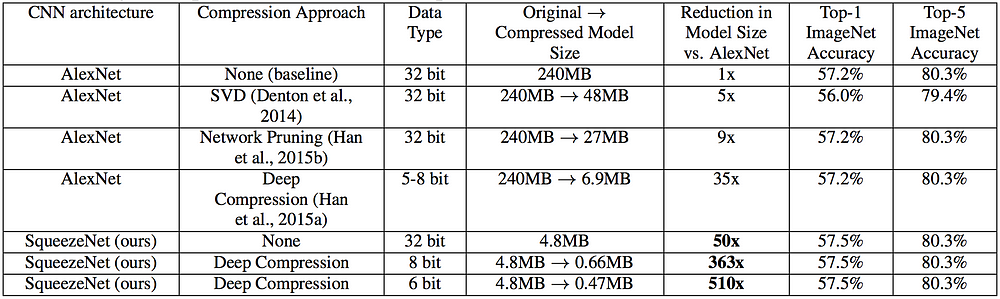
The problem directly ahead of us was simple: if Inception and VGG were too big, was there a simpler, pre-trained neural network we could retrain?
At the suggestion of the always excellent Jeremy P. Howard (where has that guy been all our life?), we explored Xception, Enet and SqueezeNet. We quickly settled on SqueezeNet due to its explicit positioning as a solution for embedded deep learning, and the availability of a pre-trained Keras model on GitHub (yay open-source).
So how big of a difference does this make? An architecture like VGG uses about 138 million parameters (essentially the number of numbers necessary to model the neurons and values between them).
Inception is already a massive improvement, requiring only 23 million parameters.
SqueezeNet, in comparison only requires 1.25 million.
This has two advantages:
- During the training phase, it’s much faster to train a smaller network. There’s less parameters to map in memory, which means you can parallelize your training a bit more (larger batch size), and the network will converge (i.e., approximate the idealized mathematical function) more quickly.
- In production, the model is much smaller and much faster. SqueezeNet would require less than 10MB of RAM, while something like Inception requires 100MB or more. The delta is huge, and particularly important when running on mobile devices that may have less than 100MB of RAM available to run your app. Smaller networks also compute a result much faster than bigger ones.
There are tradeoffs of course:
- A smaller neural architecture has less available “memory”: it will not be as efficient at handling complex cases (such as recognizing 20,000 different objects), or even handling complex subcases (like say, appreciating the difference between a New York-style hotdog and a Chicago-style hotdog)
As a corollary, smaller networks are usually less accurate overall than big ones. When trying to recognize ImageNet’s 20,000 different objects, SqueezeNet will only score around 58%, whereas Vgg will be accurate 72% of the time. - It’s harder to use transfer learning on a small network. Technically, there is nothing preventing us from using the same approach we used with Inception & Vgg, have SqueezeNet “forget” a little bit, and retrain it specifically for hotdogs vs. not hotdogs. In practice, we found it hard to tune the learning rate, and results were always more disappointing than training SqueezeNet from scratch. This could also be caused or worsened by the open-world nature of our problem.
- Supposedly, smaller networks rarely overfit, but this happened to us with several “small” architectures. Overfitting means that your network specializes too much, and instead of learning how to recognize hotdogs in general, it learns to recognize exactly & only the specific hotdog images you were training with. A human analogue would be visually-memorizing exactly which of the images presented to you were of a “hotdog” without abstracting that a hotdog is usually composed of a sausage in a bun, possibly with condiments, etc. If you were presented with a brand new hotdog image that wasn’t one of the ones you memorized, you would be inclined to say it’s not a hotdog. Because smaller networks usually have less “memory”, it’s easy to see why it would be harder for them to specialize. But in several cases, our small networks’ accuracy jumped up to 99% and suddenly became unable to recognize images it had not seen in training. This usually disappeared once we added enough data augmentation(stretching/distorting input images semi-randomly so instead of being trained 1,00 times on each of the 1,000 images, the network is trained on meaningful variations of the 1,000 images making it unlikely the network will memory exactly the 1,000 images and instead will have to learn to recognize the “features” of a hotdog (bun, sausage, condiments, etc.) while staying fluid/general enough not to get overly attached to specific pixel values of specific images in the training set. 【这里涉及到了CS231n Winter 2016: Lecture 11: ConvNets in practice】Data Augmentation example from the Keras Blog.
During this phase, we started experimenting with tuning the neural network architecture. In particular, we started using Batch Normalization and trying different activation functions.
- Batch Normalization helps your network learn faster by “smoothing” the values at various stages in the stack. Exactly why this works is seemingly not well-understood yet, but it has the effect of helping your network converge much faster, meaning it achieves higher accuracy with less training, or higher accuracy after the same amount of training, often dramatically so.
- Activation functions are the internal mathematical functions determining whether your “neurons” activate or not. Many papers still use ReLU, the Rectified Linear Unit, but we had our best results using ELU instead.
After adding Batch Normalization and ELU to SqueezeNet, we were able to train neural network that achieve 90%+ accuracy when training from scratch, however, they were relatively brittle meaning the same network would overfit in some cases, or underfit in others when confronted to real-life testing. Even adding more examples to the dataset and playing with data augmentation failed to deliver a network that met expectations.
So while this phase was promising, and for the first time gave us a functioning app that could work entirely on an iPhone, in less than a second, we eventually moved to our 4th & final architecture.
【貌似overfit, underfit是个问题】
以上只是展示作者思维的过度内容,为下文做铺垫。
五、The DeepDog Architecture
-
Design
Our final architecture was spurred in large part by the publication on April 17 of Google’s MobileNets paper, promising a new neural architecture with Inception-like accuracy on simple problems like ours, with only 4M or so parameters.
This meant it sat in an interesting sweet spot between a SqueezeNet that had maybe been overly simplistic for our purposes, and the possibly overwrought elephant-trying-to-squeeze-in-a-tutu of using Inception or VGG on Mobile. The paper introduced some capacity to tune the size & complexity of network specifically to trade memory/CPU consumption against accuracy, which was very much top of mind for us at the time.
With less than a month to go before the app had to launch we endeavored to reproduce the paper’s results. This was entirely anticlimactic as within a day of the paper being published a Keras implementation was already offered publicly on GitHub by Refik Can Malli, a student at Istanbul Technical University, whose work we had already benefitted from when we took inspiration from his excellent Keras SqueezeNet implementation. The depth & openness of the deep learning community, and the presence of talented minds like R.C. is what makes deep learning viable for applications today — but they also make working in this field more thrilling than any tech trend we’ve been involved with.
Our final architecture ended up making significant departures from the MobileNets architecture or from convention, in particular:
-
-
- We do not use Batch Normalization & Activation between depthwise and pointwise convolutions, because the XCeption paper (which discussed depthwise convolutions in detail) seemed to indicate it would actually lead to less accuracy in architecture of this type (as helpfully pointed out by the author of the QuickNet paper on Reddit). This also has the benefit of reducing the network size. 【不再用Batch Normalization & Activation between depthwise and pointwise convolutions】
- We use ELU instead of ReLU. Just like with our SqueezeNet experiments, it provided superior convergence speed & final accuracy when compared to ReLU 【SqueezeNet上的ELU更有效比ReLU】
- We did not use PELU. While promising, this activation function seemed to fall into a binary state whenever we tried to use it. Instead of gradually improving, our network’s accuracy would alternate between ~0% and ~100% from one batch to the next. It’s unclear why this happened, and might just come down to an implementation error or user error. Fusing the width/height axes of our images had no effect. 【不用PELU】
- We did not use SELU. A short investigation between the iOS & Android release led to results very similar to PELU. It’s our suspicion that SELU should not be used in isolation as a sort of activation function silver bullet, but rather — as the paper’s title implies — as part of a narrowly-defined SNN architecture. 【不用SELU】
- We maintain the use of Batch Normalization with ELU. There are many indications that this should be unnecessary, however, every experiment we ran without Batch Normalization completely failed to converge. This could be due to the small size of our architecture. 【BN+ELU】
- We used Batch Normalization before the activation. While this is a subject of some debate these days, our experiments placing BN after activation on small networks failed to converge as well. 【BN --> activiation】
- To optimize the network we used Cyclical Learning Rates and (fellow student) Brad Kenstler’s excellent Keras implementation. CLRs take the guessing game out of finding the optimal learning rate for your training. Even more importantly by adjusting the learning rate both up & down throughout your training, they help achieve a final accuracy that’s in our experience better than a traditional optimizer. For both of these reasons, we can’t conceive using anything else than CLRs to train a neural network in the future. 【CLR 循环式学习率】
- For what it’s worth, we saw no need to adjust the α or ρ values from the MobileNets architecture. Our model was small enough for our purposes at α = 1, and computation was fast enough at ρ = 1, and we preferred to focus on achieving maximum accuracy. However, this could be helpful when attempting to run on older mobile devices, or embedded platforms. 【暂不必改变 α or ρ values】
-
So how does this stack work exactly? Deep Learning often gets a bad rap for being a “black box”, and while it’s true many components of it can be mysterious, the networks we use often leak information about how some of their magic work. We can look at the layers of this stack and how they activate on specific input images, giving us a sense of each layer’s ability to recognize sausage, buns, or other particularly salient hotdog features.
貌似是卷积可视化工具:https://github.com/keplr-io/quiver 【在卷积可视化专题中讲解】

-
Training
Data quality was of the utmost importance. A neural network can only be as good as the data that trained it, and improving training set quality was probably one of the top 3 things we spent time on during this project. The key things we did to improve this were:
-
- Sourcing more images, and more varied images (height/width, background, lighting conditions, cultural differences, perspective, composition, etc.) 【要多】
- Matching image types to expected production inputs. Our guess was people would mostly try to photograph actual hotdogs, other foods, or would sometimes try to trick the system with random objects, so our dataset reflected that. 【尽量找可能测试的图片】
- Give lots of examples of things that are similar that may trip your network. Some of the things that look most similar to hotdogs are other foods (such as hamburgers, sandwiches, or in the case of naked hotdogs, baby carrots or even cooked cherry tomatoes). Our dataset reflected that. 【相似的异类图片也要尽可能的多】
- Expect distortions: in mobile situations, most photos will be worse than the “average” picture taken with a DLSR or in perfect lighting conditions. Mobile photos are dim, noisy, taken at an angle. Aggressive data augmentation was key to counter this. 【手机照片质量不行,可增强下】
- Additionally we figured that users may lack access to real hotdogs, so may try photographing hotdogs from Google search results, which led to its own types of distortion (skewing if photo is taken at angle, flash reflection on the screen visible moiré effect caused by taking a picture of an LCD screen with a mobile camera). These specific distortion had an almost uncanny ability to trick our network, not unlike recently-published papers on Convolutional Network’s (lack of) resistance to noise. Using Keras’ channel shift feature resolved most of these issues.
-
- Some edge cases were hard to catch. In particular, images of hotdogs taken with a soft focus or with lots of bokeh in the background would sometimes trick our neural network. This was hard to defend against as a) there just aren’t that many photographs of hotdogs in soft focus (we get hungry just thinking about it) and b) it could be damaging to spend too much of our network’s capacity training for soft focus, when realistically most images taken with a mobile phone will not have that feature. We chose to leave this largely unaddressed as a result.
The final composition of our dataset was 150k images, of which only 3k were hotdogs:
there are only so many hotdogs you can look at, but there are many not hotdogs to look at. The 49:1 imbalance was dealt with by saying a Keras class weight of 49:1 in favor of hotdogs. Of the remaining 147k images, most were of food, with just 3k photos of non-food items, to help the network generalize a bit more and not get tricked into seeing a hotdog if presented with an image of a human in a red outfit.
- 照片增强法
Our data augmentation rules were as follows:
-
-
- We applied rotations within ±135 degrees — significantly more than average, because we coded the application to disregard phone orientation.
- Height and width shifts of 20%
- Shear range of 30%
- Zoom range of 10%
- Channel shifts of 20%
- Random horizontal flips to help the network generalize
-
These numbers were derived intuitively, based on experiments and our understanding of the real-life usage of our app, as opposed to careful experimentation.
The final key to our data pipeline was using Patrick Rodriguez’s multiprocess image data generator for Keras. While Keras does have a built-in multi-threaded and multiprocess implementation, we found Patrick’s library to be consistently faster in our experiments, for reasons we did not have time to investigate. This library cut our training time to a third of what it used to be. 【image augmentation】
The network was trained using a 2015 MacBook Pro and attached external GPU (eGPU), specifically an Nvidia GTX 980 Ti (we’d probably buy a 1080 Ti if we were starting today).
We were able to train the network on batches of 128 images at a time.
The network was trained for a total of 240 epochs, meaning we ran all 150k images through the network 240 times. This took about 80 hours.
We trained the network in 3 phases:
-
-
- Phase 1 ran for 112 epochs (7 full CLR cycles with a step size of 8 epochs), with a learning rate between 0.005 and 0.03, on a triangular 2 policy (meaning the max learning rate was halved every 16 epochs).
- Phase 2 ran for 64 more epochs (4 CLR cycles with a step size of 8 epochs), with a learning rate between 0.0004 and 0.0045, on a triangular 2 policy.
- Phase 3 ran for 64 more epochs (4 CLR cycles with a step size of 8 epochs), with a learning rate between 0.000015 and 0.0002, on a triangular 2 policy.
-
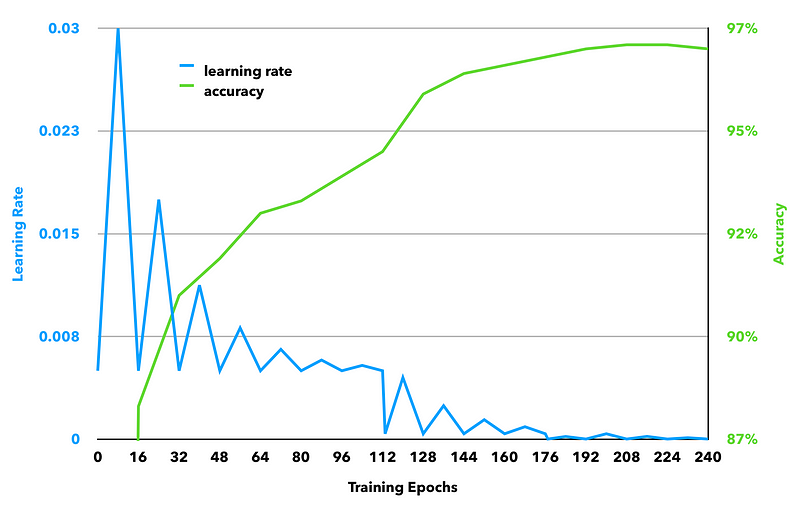
UPDATED: a previous version of this chart contained inaccurate learning rates.
While learning rates were identified by running the linear experiment recommended by the CLR paper, they seem to intuitively make sense, in that the max for each phase is within a factor of 2 of the previous minimum, which is aligned with the industry standard recommendation of halving your learning rate if your accuracy plateaus during training.
In the interest of time we performed some training runs on a Paperspace P5000 instance running Ubuntu. In those cases, we were able to double the batch size, and found that optimal learning rates for each phase were roughly double as well.
- 其他参考资料
Running Neural Networks on Mobile Phones
Even having designed a relatively compact neural architecture, and having trained it to handle situations it may find in a mobile context, we had a lot of work left to make it run properly. Trying to run a top-of-the-line neural net architecture out of the box can quickly burns hundreds megabytes of RAM, which few mobile devices can spare today. Beyond network optimizations, it turns out the way you handle images or even load TensorFlow itself can have a huge impact on how quickly your network runs, how little RAM it uses, and how crash-free the experience will be for your users.
This was maybe the most mysterious part of this project. Relatively little information can be found about it, possibly due to the dearth of production deep learning applications running on mobile devices as of today. However, we must commend the Tensorflow team, and particularly Pete Warden, Andrew Harp and Chad Whipkey for the existing documentation and their kindness in answering our inquiries.
-
- Rounding the weights of our network helped compressed the network to ~25% of its size. Essentially instead of using the arbitrary stock values derived from your training, this optimization picks the N most common values and sets all parameters in your network to these values, which drastically reduces the size of your network when zipped. This however has no impact on the uncompressed app size, or memory usage. We did not ship this improvement to production as the network was small enough for our purposes, and we did not have time to quantify how much of a hit the rounding would have on the accuracy of the app. 【网络已很小,没太大必要】
- Optimize the TensorFlow lib by compiling it for production with -Os 【编译自动优化】
- Removing unnecessary ops from the TensorFlow lib: TensorFlow is in some respect a virtual machine, able to interpret a number or arbitrary TensorFlow operations: addition, multiplications, concatenations, etc. You can get significant weight (and memory) savings by removing unnecessary ops from the TensorFlow library you compile for ios. 【精简tf本身】
- Other improvements might be possible. For example unrelated work by the author yielded 1MB improvement in Android binary size with a relatively simple trick, so there may be more areas of TensorFlow’s iOS code that can be optimized for your purposes.
Instead of using TensorFlow on iOS, we looked at using Apple’s built-in deep learning libraries instead (BNNS, MPSCNN and later on, CoreML). We would have designed the network in Keras, trained it with TensorFlow, exported all the weight values, re-implemented the network with BNNS or MPSCNN (or imported it via CoreML), and loaded the parameters into that new implementation. However, the biggest obstacle was that these new Apple libraries are only available on iOS 10+, and we wanted to support older versions of iOS. As iOS 10+ adoption and these frameworks continue to improve, there may not be a case for using TensorFlow on device in the near future.
Changing App Behavior by Injecting Neural Networks on The fly
(...)
What We Would Do Differently
There are a lot of things that didn’t work or we didn’t have time to do, and these are the ideas we’d investigate in the future:
-
- More carefully tune our data-augmentation parameters.
- Measure accuracy end-to-end, i.e. the final determination made by the app abstracting things like whether our app has 2 or many more categories, what the final threshold for hotdog recognition is (we ended up having the app say “hotdog” if recognition is above 0.90 as opposed to the default of 0.5), after weights are rounded, etc.
- Building a feedback mechanism into the app — to let users vent frustration if results are erroneous, or actively improve the neural network.
- Use a larger resolution for image recognition than 224 x 224 pixels — essentially using a MobileNets ρ value > 1.0

