
[Localization] MobileNet with SSD
先来一波各版本性能展览:
Pre-trained Models
Choose the right MobileNet model to fit your latency and size budget. The size of the network in memory and on disk is proportional to the number of parameters. The latency and power usage of the network scales with the number of Multiply-Accumulates (MACs) which measures the number of fused Multiplication and Addition operations. These MobileNet models have been trained on the ILSVRC-2012-CLS image classification dataset. Accuracies were computed by evaluating using a single image crop.
| Model Checkpoint | Million MACs | Million Parameters | Top-1 Accuracy | Top-5 Accuracy |
|---|---|---|---|---|
| MobileNet_v1_1.0_224 | 569 | 4.24 | 70.7 | 89.5 |
| MobileNet_v1_1.0_192 | 418 | 4.24 | 69.3 | 88.9 |
| MobileNet_v1_1.0_160 | 291 | 4.24 | 67.2 | 87.5 |
| MobileNet_v1_1.0_128 | 186 | 4.24 | 64.1 | 85.3 |
| MobileNet_v1_0.75_224 | 317 | 2.59 | 68.4 | 88.2 |
| MobileNet_v1_0.75_192 | 233 | 2.59 | 67.4 | 87.3 |
| MobileNet_v1_0.75_160 | 162 | 2.59 | 65.2 | 86.1 |
| MobileNet_v1_0.75_128 | 104 | 2.59 | 61.8 | 83.6 |
| MobileNet_v1_0.50_224 | 150 | 1.34 | 64.0 | 85.4 |
| MobileNet_v1_0.50_192 | 110 | 1.34 | 62.1 | 84.0 |
| MobileNet_v1_0.50_160 | 77 | 1.34 | 59.9 | 82.5 |
| MobileNet_v1_0.50_128 | 49 | 1.34 | 56.2 | 79.6 |
| MobileNet_v1_0.25_224 | 41 | 0.47 | 50.6 | 75.0 |
| MobileNet_v1_0.25_192 | 34 | 0.47 | 49.0 | 73.6 |
| MobileNet_v1_0.25_160 | 21 | 0.47 | 46.0 | 70.7 |
| MobileNet_v1_0.25_128 | 14 | 0.47 | 41.3 | 66.2 |

前两个大小还是可以接受的。
Here is an example of how to download the MobileNet_v1_1.0_224 checkpoint:
$ CHECKPOINT_DIR=/tmp/checkpoints
$ mkdir ${CHECKPOINT_DIR}
$ wget http://download.tensorflow.org/models/mobilenet_v1_1.0_224_2017_06_14.tar.gz
$ tar -xvf mobilenet_v1_1.0_224_2017_06_14.tar.gz
$ mv mobilenet_v1_1.0_224.ckpt.* ${CHECKPOINT_DIR}
$ rm mobilenet_v1_1.0_224_2017_06_14.tar.gz
代码于此,未来需研究一波。
models/research/slim/nets/mobilenet_v1.py
传统卷积-->分离成每个通道的单滤波器卷积 then 与每个pixel的1*1卷积做合并。可以提高至少十倍性能!
Ref: http://www.jianshu.com/p/072faad13145
Ref: http://blog.csdn.net/jesse_mx/article/details/70766871
摘要
- 使用深度可分解卷积(depthwise separable convolutions)来构建轻量级深度神经网络的精简结构(streamlined architecture,流线型结构 or 精简结构,倾向于后者)。
- 本文引入了两个 简单的全局超参来有效权衡延迟(latency)和准确度(accuracy)。这些超参允许模型构建者根据具体问题的限制为他们的应用选择规模合适的模型。
1.引言
2.背景介绍
记录:需要注意的是目前在应用于移动和嵌入式设备的深度学习 网络研究主要有两个方向:
1)直接设计较小且高效的网络,并训练。
-
- Inception思想,采用小卷积。
- Network in Network 改进传统CNN,使用1x1卷积,提出MLP CONV层Deep Fried Convents采用Adaptive Fast-food transform重新 参数化全连接层的向量矩阵。
- SqueezeNet设计目标主要是为了简化CNN的模型参数数量,主要采用了替换卷积核3x3为1x1,使用了deep compression技术对网络进行了压缩 。
- Flattened networks针对快速前馈执行设计的扁平神经网络。
-
- 采用hashing trick进行压缩;采用huffman编码;
- 用大网络来教小网络;
- 训练低精度乘法器;
- 采用二进制输入二进制权值等等。
3.MobileNet 架构
- 深度可分解滤波(depth wise separable filters)建立的MobileNets核心层;
- 两个模型收缩超参:宽度乘法器和分辨率乘法器(width multiplier和resolution multiplier)。
3.1.深度可分解卷积(Depthwise Separable Convolution)
MobileNet模型机遇深度可分解卷积,其可以将标准卷积分解成 一个深度卷积和一个1x1的点卷积。

3.2. 网络结构和训练

对应的api:https://www.tensorflow.org/versions/r0.12/api_docs/python/nn/convolution
tf.nn.depthwise_conv2d(input, filter, strides, padding, name=None)

3.3.宽度乘法器(Width Multiplier)
第一个超参数,即宽度乘数 α 。
为了构建更小和更少计算量的网络,引入了宽度乘数 α ,改变输入输出通道数,减少特征图数量,让网络变瘦。
在 α 参数作用下,MobileNets某一层的计算量为:
其中, α 取值是0~1,应用宽度乘数可以进一步减少计算量,大约有 α2 的优化空间。
3.4. 分辨率乘法器(Resolution Multiplier)
第二个超参数是分辨率乘数 ρ
用来改变输入数据层的分辨率,同样也能减少参数。
在 α 和 ρ 共同作用下,MobileNets某一层的计算量为:
DK×DK×αM×ρDF×ρDF + αM×αN×ρDF×ρDF
其中,ρ 是隐式参数,ρ 如果为{1,6/7,5/7,4/7},则对应输入分辨率为{224,192,160,128},ρ 参数的优化空间同样是 ρ2 左右。

以上就是重点。
Final Report: Towards Real-time Detection and Camera Triggering
在草莓pi上各个轻网络的的实验效果,其中有介绍剪裁网络的思路,提供了很多线索,挺好。
以及对mobileNet结构的微调方法。
The main thing that makes MobileNets stand out is its use of depthwise separable convolution (DSC) layer.
The Intuition behind DSC: studies [2] have showed that DSC can be treated as an extreme case of inception module.
The structure of Mobile-Det is similar to ssd-vgg-300: [Localization] SSD - Single Shot MultiBoxDetector the original SSD framework.
- The difference is that rather than using VGG, now the backbone is MobileNets,
- and also all the following added convolution is replaced with depthwise separable convolution.
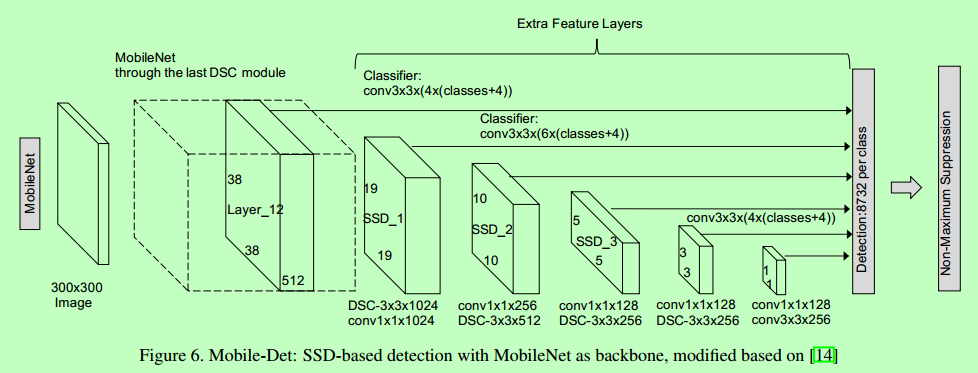
The benefit of using SSD framework is evident:
now we have a unified model and is able to train end-to-end;
we do not rely on the reference frame and hence the temporal information, expanding our application scenarios;
it is also more accurate in theory.
However, the main issue is that, the model becomes very slow, as a large amount of convolution operations are added.
In this project, we tested a variety of detection models, including the state-of-art YOLO2, and two our newly proposed models: Temporal Detection and Mobile-Det.
We conclude that the current object detection methods, although accurate, is far from being able to be deployed in real-world applications due to large model size and slow speed.
Our work of Mobile-Det shows that the combination of SSD and MobileNet provides a new feasible and promising insight on seeking a faster detection framework.
Finally, we present the power of temporal information and shows differential based region proposal can drastically increase the detection speed.
7. Future work
There are a few aspects that could potentially improve the performance but remains to be implemented due to limited time, including:
• Implement an efficient inference module of 8bit float in C++ to better take advantage of the speed up of quantization to inference step on small device.
• Try to combine designed CNN modules like MobileNet module and fire module with other real-time standard detection frameworks.
【fire layer貌似不好使,有实验已测试】
今后课题:
- 如何训练识别两个以上的物体。
- 使用传统算子生成训练集。

