
[Localization] YOLO: Real-Time Object Detection
Ref: https://pjreddie.com/darknet/yolo/

关注点在于,为何变得更快?
论文笔记:You Only Look Once: Unified, Real-Time Object Detection
Ref: https://zhuanlan.zhihu.com/p/24916786?refer=xiaoleimlnote
评论:
基于深度学习方法的一个特点就是实现端到端的检测。
相对于其它目标检测与识别方法(比如Fast R-CNN)将目标识别任务分类目标区域预测和类别预测等多个流程,
YOLO将目标区域预测和目标类别预测整合于单个神经网络模型中,实现在准确率较高的情况下快速目标检测与识别,更加适合现场应用环境。
后续研究,可以进一步优化YOLO网络结构,提高YOLO准确率。YOLO类型的端到端的实时目标检测方法是一个很好的研究方向。(预告:后续文章中,将对YOLO的tensorflow源码实现进行详解,敬请关注)
简介:
YOLO为一种新的目标检测方法,该方法的特点是实现快速检测的同时还达到较高的准确率。作者将目标检测任务看作目标区域预测和类别预测的回归问题。
该方法采用单个神经网络直接预测物品边界和类别概率,实现端到端的物品检测。同时,该方法检测速非常快,基础版可以达到45帧/s的实时检测;FastYOLO可以达到155帧/s。与当前最好系统相比,YOLO目标区域定位误差更大,但是背景预测的假阳性优于当前最好的方法。
1 前言
人类视觉系统快速且精准,只需瞄一眼(You Only Look Once,YOLO)即可识别图像中物品及其位置。
传统目标检测系统采用deformable parts models (DPM)方法,
- 通过滑动框方法提出目标区域,
- 然后采用分类器来实现识别。
近期的R-CNN类方法采用region proposal methods,
- 首先生成潜在的bounding boxes,
- 然后采用分类器识别这些bounding boxes区域。
- 最后通过post-processing来去除重复bounding boxes来进行优化。
这类方法流程复杂,存在速度慢和训练困难的问题。
本文中,我们将目标检测问题转换为直接从图像中提取bounding boxes和类别概率的单个回归问题,只需一眼(you only look once,YOLO)即可检测目标类别和位置。
YOLO采用单个卷积神经网络来预测多个bounding boxes和类别概率,如图1-1所示。本方法相对于传统方法有如下有优点:
一,非常快。YOLO预测流程简单,速度很快。我们的基础版在Titan X GPU上可以达到45帧/s; 快速版可以达到150帧/s。因此,YOLO可以实现实时检测。
二,YOLO采用全图信息来进行预测。与滑动窗口方法和region proposal-based方法不同,YOLO在训练和预测过程中可以利用全图信息。Fast R-CNN检测方法会错误的将背景中的斑块检测为目标,原因在于Fast R-CNN在检测中无法看到全局图像。相对于Fast R-CNN,YOLO背景预测错误率低一半。
三,YOLO可以学习到目标的概括信息(generalizable representation),具有一定普适性。我们采用自然图片训练YOLO,然后采用艺术图像来预测。YOLO比其它目标检测方法(DPM和R-CNN)准确率高很多。
YOLO的准确率没有最好的检测系统准确率高。YOLO可以快速识别图像中的目标,但是准确定位目标(特别是小目标)有点困难。

图1-1 YOLO目标检测系统
2 统一检测(Unified Detection)
作者将目标检测的流程统一为单个神经网络。该神经网络采用整个图像信息来预测目标的bounding boxes的同时识别目标的类别,实现端到端实时目标检测任务。
如图2-1所示,YOLO首先将图像分为S×S的格子(grid cell)。如果一个目标的中心落入格子,该格子就负责检测该目标。每一个格子(grid cell)预测bounding boxes(B)和该boxes的置信值(confidence score)。置信值代表box包含一个目标的置信度。然后,我们定义置信值为。如果没有目标,置信值为零。另外,我们希望预测的置信值和ground truth的intersection over union (IOU)相同。
每一个bounding box包含5个值:x,y,w,h和confidence。(x,y)代表与格子相关的box的中心。(w,h)为与全图信息相关的box的宽和高。confidence代表预测boxes的IOU和gound truth。
每个格子(grid cell)预测条件概率值C()。概率值C代表了格子包含一个目标的概率,每一格子只预测一类概率。在测试时,每个box通过类别概率和box置信度相乘来得到特定类别置信分数:
这个分数代表该类别出现在box中的概率和box和目标的合适度。在PASCAL VOC数据集上评价时,我们采用S=7,B=2,C=20(该数据集包含20个类别),最终预测结果为7×7×30的tensor。
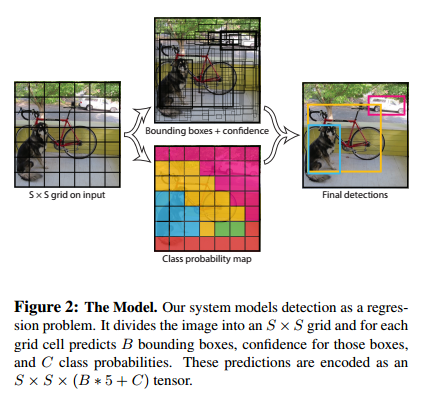
图2-1 模型
2.1 网络结构
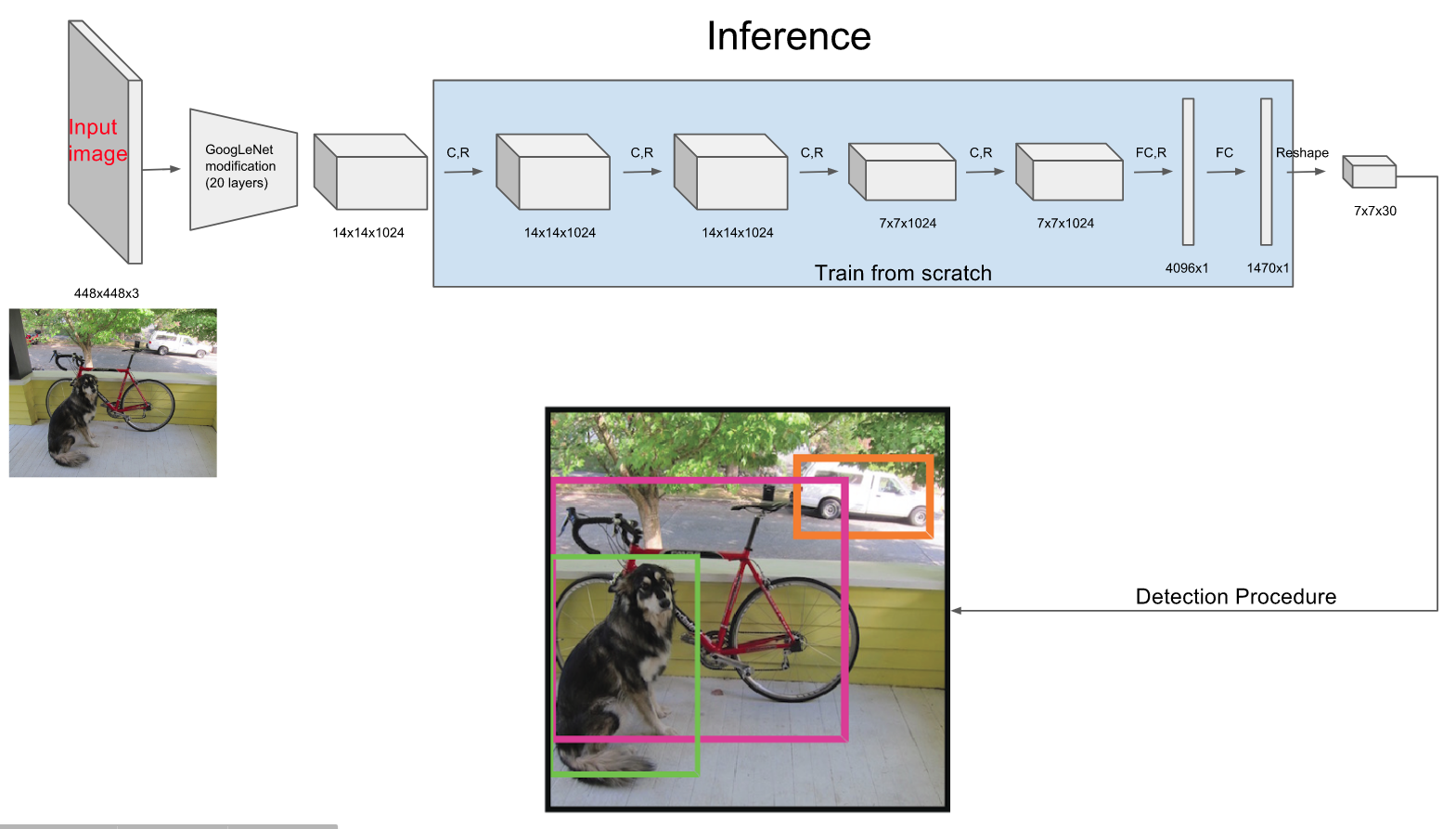
模型采用卷积神经网络结构。开始的卷积层提取图像特征,全连接层预测输出概率。模型结构类似于GoogleNet,如图3所示。作者还训练了YOLO的快速版本(fast YOLO)。Fast YOLO模型卷积层和filter更少。最终输出为7×7×30的tensor。

图2-2 网络结构
2.2 训练方法
作者采用ImageNet 1000-class 数据集来预训练卷积层。
预训练阶段,采用图2-2网络中的前20卷积层,外加average-pooling 层和全连接层。
模型训练了一周,获得了top-5 accuracy为0.88(ImageNet2012 validation set),与GoogleNet模型准确率相当。
然后,将模型转换为检测模型。作者向预训练模型中加入了4个卷积层和两层全连接层,提高了模型输入分辨率(224×224->448×448)。顶层预测类别概率和bounding box协调值。bounding box的宽和高通过输入图像宽和高归一化到0-1区间。顶层采用linear activation,其它层使用 leaky rectified linear。作者采用sum-squared error为目标函数来优化,增加bounding box loss权重,减少置信度权重,实验中,设定为。
训练阶段的总loss函数如下:
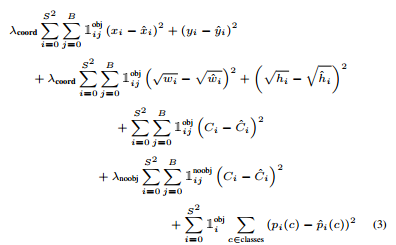
作者在PASCAL VOC2007和PASCAL VOC2012数据集上进行了训练和测试。
训练135轮,batch size为64,动量为0.9,学习速率延迟为0.0005. Learning schedule为:
第一轮,学习速率从0.001缓慢增加到0.01(因为如果初始为高学习速率,会导致模型发散);保持0.01速率到75轮;
然后在后30轮中,下降到0.001;
最后30轮,学习速率为0.0001.
作者还采用了dropout和 data augmentation来预防过拟合。dropout值为0.5;data augmentation包括:random scaling,translation,adjust exposure和saturation。
2.3 预测
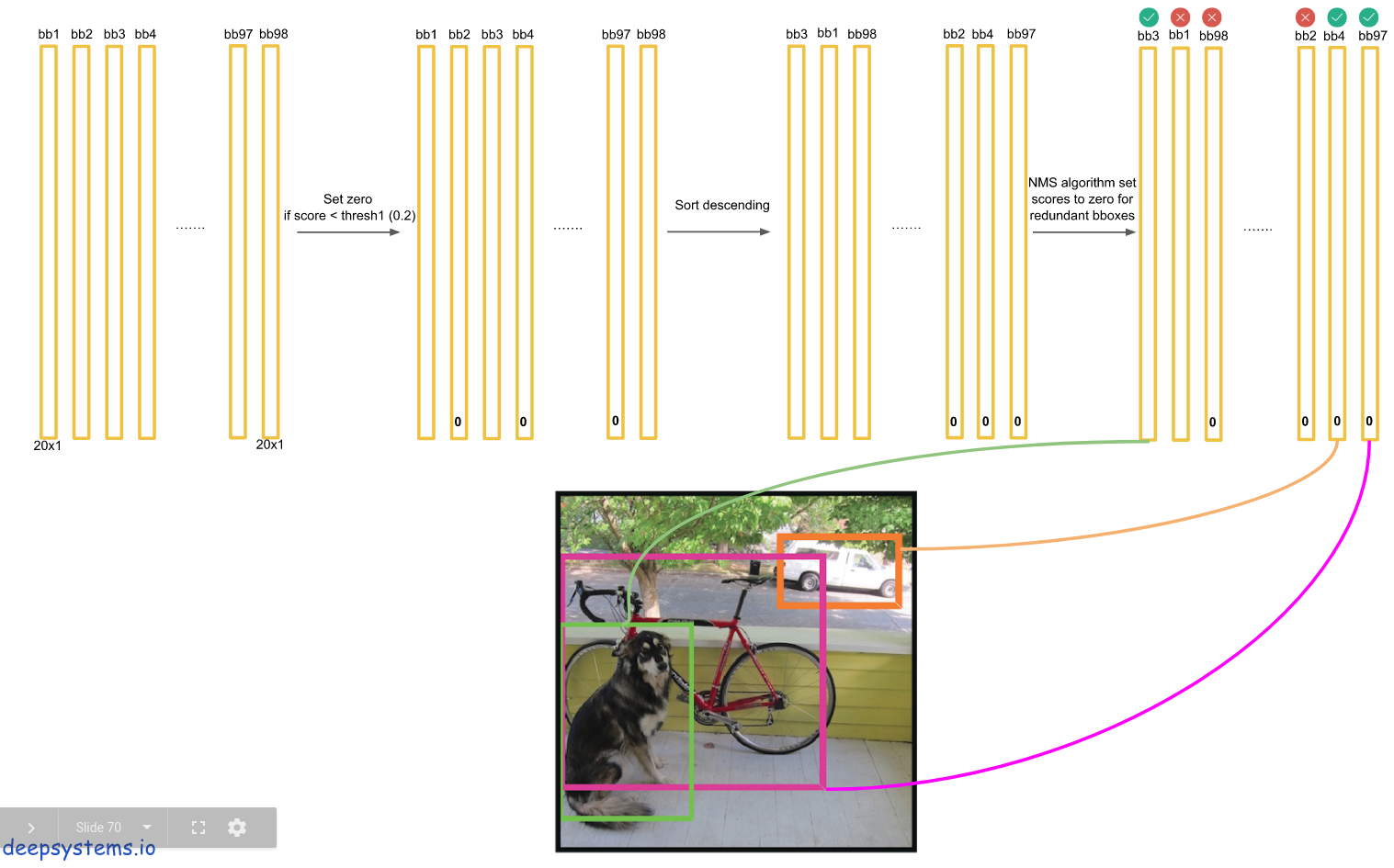
对于PASCAL VOC数据集,模型需要对每张图片预测98个bounding box和对应的类别。对于大部分目标只包含一个box;其它有些面积大的目标包含了多个boxes,采用了Non-maximal suppression(非最大值抑制)来提高准确率。
2.4 Limitations
一,YOLO的每一个网格只预测两个boxes,一种类别。这导致模型对相邻目标预测准确率下降。因此,YOLO对成队列的目标(如 一群鸟)识别准确率较低。
二,YOLO是从数据中学习预测bounding boxes,因此,对新的或者不常见角度的目标无法识别。
三,YOLO的loss函数对small bounding boxes和large bounding boxes的error平等对待,影响了模型识别准确率。因为对于小的bounding boxes,small error影响更大。
其他请见原文。
Ref: https://www.youtube.com/watch?v=L0tzmv--CGY

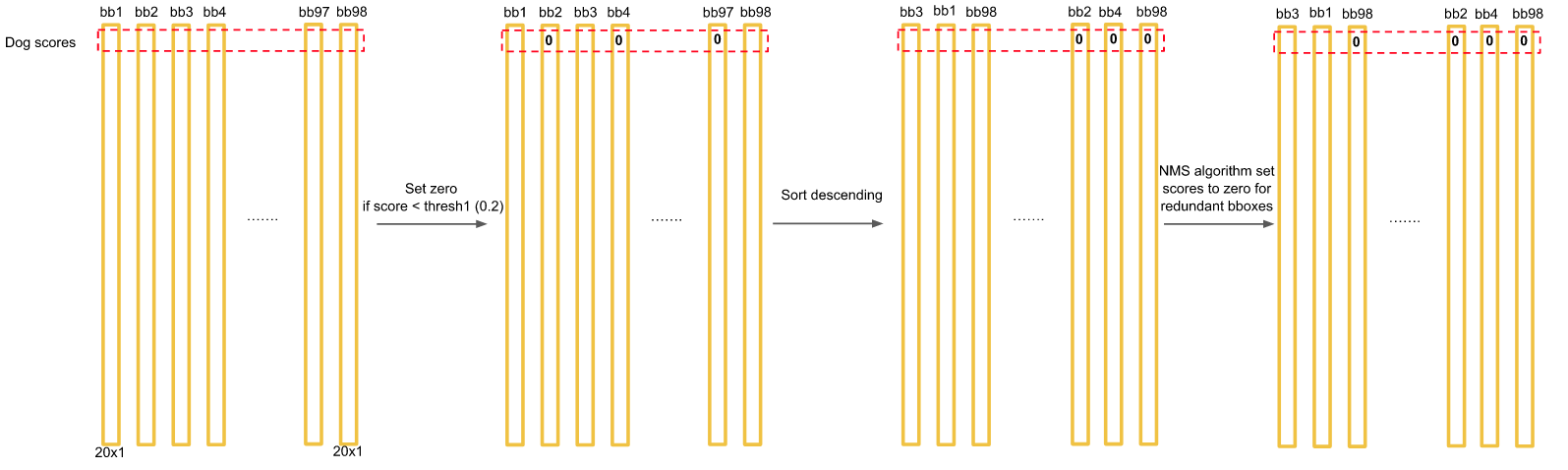
然后采用非极大值抑制算法,找出最可能的bounding box。排除在外的设置为0。
瓶颈,这里有提及:http://cs231n.stanford.edu/reports/2017/pdfs/135.pdf
We focused on reducing the apparent bottleneck in the last two layers of the tiny-yolo architecture, where the 3x3 filters with padding of 1 convolutions had 1024 filters, replacing those layers with fire modules.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号