
[Tensorflow] Practice - The Tensorflow Way
该系列主要是《Tensorflow 实战Google深度学习框架 》阅读笔记;有了Cookbook的热身后,以这本书作为基础形成个人知识体系。

Ref: [Tensorflow] Cookbook - The Tensorflow Way
第一章,简介(略)
第二章,安装(仅记录个别要点)
Protocol buffer
Bazel, similar with Makefile for complile.
Install steps:
(1) Docker
(2) Tensorflow
Source code --> pip install package --> pip install.
第三章,入门

计算图

1. 定义计算
2. 执行计算
In [1]: import tensorflow as tf In [2]: a = tf.constant([1.0, 2.0], name = "a") In [3]: b = tf.constant([2.0, 3.0], name = "b") In [4]: result = a+b
# 必须sess才能执行,这里只是定义 In [5]: result Out[5]: <tf.Tensor 'add:0' shape=(2,) dtype=float32>
系统默认了一个计算图:
In [6]: print(a.graph is tf.get_default_graph()) True In [7]: print(b.graph is tf.get_default_graph()) True
两个图,两个name = 'v'的variable;但这里不冲突。
import tensorflow as tf
g1 = tf.Graph() #自定了一个图
with g1.as_default(): #设置为当前要操作的
v = tf.get_variable("v", [1])
g2 = tf.Graph()
with g2.as_default():
v = tf.get_variable("v", [1])
# 定义结构图
# 执行结构图
with tf.Session(graph = g1) as sess: # 执行图g1
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
with tf.Session(graph = g2) as sess: # 执行图g2
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
通过图,指定运行图的设备
g = tf.Graph()
with g.device('/gpu:0'):
result = a + b
集合
-- 将资源加入集合

张量
-- 仅保存了如何得到这些数字的计算过程
import tensorflow as tf
a = tf.constant([1.0, 2.0], name="a")
b = tf.constant([2.0, 3.0], name="b")
result = a + b
print(result)
sess = tf.InteractiveSession()
print(result.eval())
sess.close()
得到的是:对结果的一个引用。【一个张量的结构】
【add:0 表示result这个张量是计算节点“add"输出的第一个结果】
【2, 表示是一维数组,长度为2】
Tensor("add:0", shape=(2,), dtype=float32)
[ 3. 5.]
基本概念:
零阶张量:scalar
一阶张量:vector
二阶张量:matrix
三阶张量:super matrix :-p
会话
将所有计算放在“with"的内部:
with tf.Session() as sess:
print(sess.run(result))
NB: Graph有默认的,自动生成;但session没有!The sess you create will be added autometically into this default Graph.
设置默认会话:【sess过程中有一次with就可以了】
sess = tf.Session()
with sess.as_default():
print(result.eval())
Output:
[ 3. 7.]
指定为默认会话的意义是什么?获取张量的取值更加方便。
sess = tf.Session()
with sess.as_default(): # 注册的过程
print(result.eval())
通过InteractiveSession自动将会话注册为默认会话。
sess = tf.InteractiveSession () # create session即同时注册
print(result.eval())
sess.close() # 但岂不是多了一行代码?方便在了哪里,不解
会话配置的修改
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
sess1 = tf.InteractiveSession(config=config)
sess2 = tf.Session(config=config)

矩阵计算
a = tf.matmul(x, w1) # 已经默认考虑了转置问题,故比较方便
变量
【cookbook有详细实例】
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
NB:seed的意义在于:保证每次运行得到的结果是一样的。
获得shape:
w1.get_shape() Out[51]: TensorShape([Dimension(2), Dimension(3)]) w1.get_shape()[0] Out[52]: Dimension(2) w1.get_shape()[1] Out[53]: Dimension(3)
- 通过“拷贝”初始化
w2 = tf.Variable(w1.initialized_value()) # 直接拷贝别人家的初始值
w3 = tf.Variable(w1.initialized_value() * 2.0)
- 通过"随机数"初始化

- 通过"常数"初始化

变量初始化的执行
通过 tf.global_variables_initializer() 真正执行对变量初始化的设定。
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
x = tf.placeholder(tf.float32, shape=(1, 2), name="input") // 没有初始值,但最好给出自身“容器”的大小,将来给feed瞧
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
init_op = tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y, feed_dict={x: [[0.7,0.9]]}))
例如:w1在Graph中的解析

Assign
变量维度的改变,但基本不用,也不会给自己找麻烦。
tf.assign( w1, w2, validate_shape=False )
第四章,深层神经网络
激活函数让神经网络不再线性化。

实现代码,可见极其简洁:
a = tf.nn.relu(tf.matmul(x, w1) + biases1)
y = tf.nn.relu(tf.matmul(a, w2) + biases2)
-
Cross-entropy

避免log值过小的方式:clip_by_value
cross_entropy = -tf.reduce_mean(t * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
Before cross-entropy, we always use softmax: X * W --> softmax --> cross-entropy
softmax_cross_entropy_with_logits(
_sentinel=None,
labels =None,
logits =None,
dim =-1,
name =None
)
sparse_softmax_cross_entropy_with_logits(
_sentinel=None,
labels =None,
logits =None,
name =None
)
如果只是关心前向传播的预测值,那么其实只关心logits部分,然后需要取出最大概率的那个label。
-
MSE - L2 loss
NB: Classification by xentropy; For regression, we use MSE as following:
mse = tf.reduce_mean(tf.square(y_ - y))
Loss最终的归宿:
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
tensorflow api for LOSS:
absolute_difference(...): Adds an Absolute Difference loss to the training procedure.
add_loss(...): Adds a externally defined loss to the collection of losses.
compute_weighted_loss(...): Computes the weighted loss.
cosine_distance(...): Adds a cosine-distance loss to the training procedure.
get_losses(...): Gets the list of losses from the loss_collection.
get_regularization_loss(...): Gets the total regularization loss.
get_regularization_losses(...): Gets the list of regularization losses.
get_total_loss(...): Returns a tensor whose value represents the total loss.
hinge_loss(...): Adds a hinge loss to the training procedure.
huber_loss(...): Adds a Huber Loss term to the training procedure.
log_loss(...): Adds a Log Loss term to the training procedure.
mean_pairwise_squared_error(...): Adds a pairwise-errors-squared loss to the training procedure.
mean_squared_error(...): Adds a Sum-of-Squares loss to the training procedure.
sigmoid_cross_entropy(...): Creates a cross-entropy loss using tf.nn.sigmoid_cross_entropy_with_logits.
softmax_cross_entropy(...): Creates a cross-entropy loss using tf.nn.softmax_cross_entropy_with_logits.
sparse_softmax_cross_entropy(...): Cross-entropy loss usingtf.nn.sparse_softmax_cross_entropy_with_logits.
-
高级点的问题
CNN--两个Loss层计算的数值问题 (overflow...)
From: https://zhuanlan.zhihu.com/p/22260935
在计算Loss部分是可能出现的一些小问题以及现在的解决方法。
其实也是仔细阅读下Caffe代码中有关Softmax loss和sigmoid cross entropy loss两个部分的真实计算方法。
- exp这个函数实在是有毒
指数函数是一个很容易让数值爆炸的函数,那么输入大概到多少会溢出呢?蛋疼的我还是做了一个实验:
np.exp(709)
8.2184074615549724e+307
出现如下问题:
def naive_softmax(x):
y = np.exp(x)
return y / np.sum(y)
#b取值很大,部分值大于了709
b = np.random.rand(10) * 1000
print b
print naive_softmax(b)
[ 497.46732916 227.75385779 537.82669096 787.54950048 663.13861524
224.69389572 958.39441314 139.09633232 381.35034548 604.08586655]
[ 0. 0. 0. nan 0. 0. nan 0. 0. 0.]
那么如何解决呢?我们只要给每个数字除以一个大数,保证它不溢出,问题不就解决了?
老司机给出的方案是找出输入数据中最大的数,然后除以e的最大数次幂,相当于下面的代码:
def high_level_softmax(x):
max_val = np.max(x)
x -= max_val
return naive_softmax(x)
However,scale太大,个别值太小了!
b = np.random.rand(10) * 1000
print b
print high_level_softmax(b)
[ 903.27437996 260.68316085 22.31677464 544.80611744 506.26848644
698.38019158 833.72024087 200.55675076 924.07740602 909.39841128]
[ 9.23337324e-010 7.79004225e-289 0.00000000e+000
1.92562645e-165 3.53094986e-182 9.57072864e-099
5.73299537e-040 6.01134555e-315 9.99999577e-001
4.21690097e-007]
使用一点平滑的小技巧还是很有必要的,于是代码又变成:
def practical_softmax(x):
max_val = np.max(x)
x -= max_val
y = np.exp(x)
y[y < 1e-20] = 1e-20
return y / np.sum(y)
Result: 相当于加了个下限
[ 9.23337325e-10 9.99999577e-21 9.99999577e-21 9.99999577e-21
9.99999577e-21 9.99999577e-21 9.99999577e-21 9.99999577e-21
9.99999577e-01 4.21690096e-07]
【但,貌似一个简单的封装好的 preds = tf.nn.softmax(z),即可解决这个问题】
- sigmoid也是中毒专业户
因为其中包含了exp,*_*b
def naive_sigmoid_loss(x, t):
y = 1 / (1 + np.exp(-x))
return -np.sum(t * np.log(y) + (1 - t) * np.log(1 - y)) / y.shape[0]
a = np.random.rand(10)* 1000
b = a > 500
print a
print b
print naive_sigmoid_loss(a,b)
[ 63.20798359 958.94378279 250.75385942 895.49371345 965.62635077
81.1217712 423.36466749 532.20604694 333.45425951 185.72621262]
[False True False True True False False True False False]
nan
改进方法:

对应代码:
def high_level_sigmoid_loss(x, t):
first = (t - (x > 0)) * x
second = np.log(1 + np.exp(x - 2 * x * (x > 0)))
return -np.sum(first - second) / x.shape[0]
a = np.random.rand(10)* 1000 - 500
b = a > 0
print a
print b
print high_level_sigmoid_loss(a,b)
[-173.48716596 462.06216262 -417.78666769 6.10480948 340.13986055
23.64615392 256.33358957 -332.46689674 416.88593348 -246.51402684]
[False True False True True True True False True False]
0.000222961919658
NN的进一步优化问题
-
学习率的设置
没有label,求得的值 y = x2 就直接是lost function。
对于learning_rate = 1的理解:
导数是2x,故w变化是10,这就是震荡的原因。
import tensorflow as tf
TRAINING_STEPS = 10
LEARNING_RATE = 1 #尝试改变学习率,查看收敛效果
# x here denotes w
x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x")
y = tf.square(x) # y = x2
train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
sess.run(train_op)
x_value = sess.run(x)
print "After %s iteration(s): x%s is %f."% (i+1, i+1, x_value)
指数递减学习率
TRAINING_STEPS = 100 global_step = tf.Variable(0) LEARNING_RATE = tf.train.exponential_decay(0.1, global_step, 1, 0.96, staircase=True) # 初始学习率
# 没1次训练学习率衰减为原来的0.96
x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x") y = tf.square(x) train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y, global_step=global_step) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(TRAINING_STEPS): sess.run(train_op) if i % 10 == 0: LEARNING_RATE_value = sess.run(LEARNING_RATE) x_value = sess.run(x) print("After %s iteration(s): x%s is %f, learning rate is %f."% (i+1, i+1, x_value, LEARNING_RATE_value))

-
过拟合问题
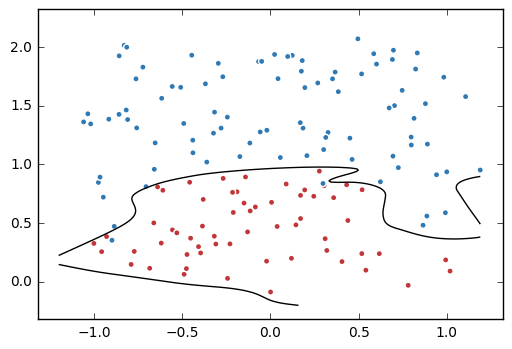
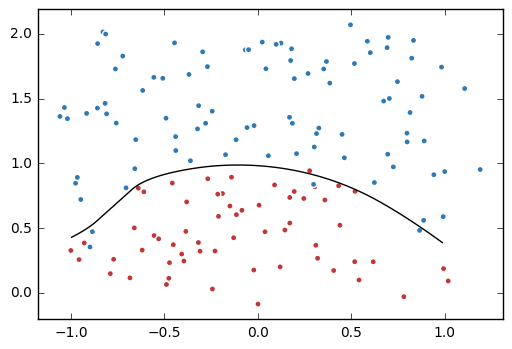
画出这两个图,感觉很好玩的样子,怎么画呢?
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
data = []
label = []
np.random.seed(0)
# 以原点为圆心,半径为1的圆把散点划分成红蓝两部分,并加入随机噪音。
剩下就是给data, label对儿不断添加一对对儿数据的过程。
for i in range(150):
x1 = np.random.uniform(-1,1)
x2 = np.random.uniform(0,2)
if x1**2 + x2**2 <= 1:
data.append([np.random.normal(x1, 0.1),np.random.normal(x2,0.1)])
label.append(0)
else:
data.append([np.random.normal(x1, 0.1), np.random.normal(x2, 0.1)])
label.append(1)
data = np.hstack(data ).reshape(-1,2) # 这里的2对应了二维空间的x,y两个坐标值
label = np.hstack(label).reshape(-1,1)
plt.scatter(data[:,0], data[:,1], c=label,
cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.show()
np.hstack 用法
>>> a = np.array((1,2,3))
>>> b = np.array((2,3,4))
>>> np.hstack((a,b))
array([1, 2, 3, 2, 3, 4])
>>> a = np.array([[1],[2],[3]])
>>> b = np.array([[2],[3],[4]])
>>> np.hstack((a,b))
array([[1, 2],
[2, 3],
[3, 4]])
np.reshape 用法
a=array([[1,2,3],[4,5,6]]) reshape(a, 6)
Out[202]:
array([1, 2, 3, 4, 5, 6])
NB:这里的 ‘-1’
reshape(a, (3, -1)) #为指定的值将被推断出为2
Out[204]:
array([[1, 2],
[3, 4],
[5, 6]])
循环生成网络结构,好巧妙的技巧!
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
sample_size = len(data)
# 每层节点的个数:比较有意思的构建网络方法
layer_dimension = [2,10,5,3,1]
n_layers = len(layer_dimension)
cur_layer = x
# 循环生成网络结构
for i in range(1, n_layers): # NB:这是是从2nd layer开始,也就是第一个out_layer
in_dimension = layer_dimension[i-1]
out_dimension = layer_dimension[i]
weight = get_weight([in_dimension, out_dimension], 0.003) # 正则参数 ---->
bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))
cur_layer = tf.nn.elu(tf.matmul(cur_layer, weight) + bias)
y= cur_layer
# 损失函数的定义。
# 这里只需要计算"刻画模型在训练数据集上的表现"的损失函数
mse_loss = tf.reduce_sum(tf.pow(y_ - y, 2)) / sample_size
tf.add_to_collection('losses', mse_loss) # 还没有正则的loss
# 得到了最终的损失函数 - 同时也结合了get_weight中的add_to_collection
loss = tf.add_n(tf.get_collection('losses'))
tf.get_collection('losses') 的内容如下:
[<tf.Tensor 'l2_regularizer:0' shape=() dtype=float32>, <tf.Tensor 'l2_regularizer_1:0' shape=() dtype=float32>, <tf.Tensor 'l2_regularizer_2:0' shape=() dtype=float32>, <tf.Tensor 'l2_regularizer_3:0' shape=() dtype=float32>, <tf.Tensor 'truediv:0' shape=() dtype=float32>, <tf.Tensor 'l2_regularizer_4:0' shape=() dtype=float32>, <tf.Tensor 'l2_regularizer_5:0' shape=() dtype=float32>, <tf.Tensor 'l2_regularizer_6:0' shape=() dtype=float32>, <tf.Tensor 'l2_regularizer_7:0' shape=() dtype=float32>, <tf.Tensor 'truediv_1:0' shape=() dtype=float32>]
将“L2正则后的权重变量var”加入到集合中:tf.add_to_collecdtion。
def get_weight(shape, lambda1):
var = tf.Variable(tf.random_normal(shape), dtype=tf.float32)
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lambda1)(var))
return var
训练不带正则项的损失函数mse_loss
# 定义训练的目标函数mse_loss,训练次数及训练模型
train_op = tf.train.AdamOptimizer(0.001).minimize(mse_loss)
TRAINING_STEPS = 40000
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
sess.run(train_op, feed_dict={x: data, y_: label})
if i % 2000 == 0:
print("After %d steps, mse_loss: %f" % (i,sess.run(mse_loss, feed_dict={x: data, y_: label})))
# 画出训练后的分割曲线 - 很有意思!
# 1. 画网格
xx, yy = np.mgrid[-1.2:1.2:.01, -0.2:2.2:.01]
grid = np.c_[xx.ravel(), yy.ravel()]
# 2.
probs = sess.run(y, feed_dict={x:grid}) # y在这里代表了最后一层
probs = probs.reshape(xx.shape)
plt.scatter(data[:,0], data[:,1], c=label, cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.contour(xx, yy, probs, levels=[.5], cmap="Greys", vmin=0, vmax=.1)
plt.show()
Ref: http://blog.csdn.net/u013534498/article/details/51399035
这篇博文我喜欢,数据表现也需要开专题学习。
np.mgrid用法
np.mgrid[-1.2:1.2:.01, -0.2:2.2:.01]
参数格式:行,列,间隙
Out[217]: array([[[-1.2 , -1.2 , -1.2 , ..., -1.2 , -1.2 , -1.2 ], [-1.19, -1.19, -1.19, ..., -1.19, -1.19, -1.19], [-1.18, -1.18, -1.18, ..., -1.18, -1.18, -1.18], ..., [ 1.17, 1.17, 1.17, ..., 1.17, 1.17, 1.17], [ 1.18, 1.18, 1.18, ..., 1.18, 1.18, 1.18], [ 1.19, 1.19, 1.19, ..., 1.19, 1.19, 1.19]], [[-0.2 , -0.19, -0.18, ..., 2.18, 2.19, 2.2 ], [-0.2 , -0.19, -0.18, ..., 2.18, 2.19, 2.2 ], [-0.2 , -0.19, -0.18, ..., 2.18, 2.19, 2.2 ], ..., [-0.2 , -0.19, -0.18, ..., 2.18, 2.19, 2.2 ], [-0.2 , -0.19, -0.18, ..., 2.18, 2.19, 2.2 ], [-0.2 , -0.19, -0.18, ..., 2.18, 2.19, 2.2 ]]])
-
滑动平均模型
衰减率:模型更新的速度
变量 --> 影子变量 (share init)
影子变量 = 衰减率*影子变量+(1-衰减率)*变量
衰减率越大,变量更新越快!
decay总体上不希望更新太快,但前期希望更新快些的衰减率设置办法:

查看不同迭代中变量取值的变化
import tensorflow as tf
v1 = tf.Variable(0, dtype=tf.float32)
step = tf.Variable(0, trainable=False)
ema = tf.train.ExponentialMovingAverage(0.99, step) # step:控制衰减率的变量
maintain_averages_op = ema.apply([v1]) # 更新列表中的变量
with tf.Session() as sess:
# 初始化
init_op = tf.global_variables_initializer()
sess.run(init_op)
print(sess.run([v1, ema.average(v1)]))
[0.0, 0.0]
# 更新变量v1的取值
sess.run(tf.assign(v1, 5))
sess.run(maintain_averages_op)
print(sess.run([v1, ema.average(v1)]))
[5.0, 4.5]
# 更新step和v1的取值
sess.run(tf.assign(step, 10000))
sess.run(tf.assign(v1, 10))
sess.run(maintain_averages_op)
print(sess.run([v1, ema.average(v1)]))
[10.0, 4.5549998]
# 更新一次v1的滑动平均值
sess.run(maintain_averages_op)
print(sess.run([v1, ema.average(v1)]))
[10.0, 4.6094499]
还是不太了解其目的:难道就是为了ema.average(v1) 这个返回结果?
疑难杂症
版本查看:
python -c 'import tensorflow as tf; print(tf.__version__)' # for Python 2
python3 -c 'import tensorflow as tf; print(tf.__version__)' # for Python 3
安装升级:
unsw@unsw-UX303UB$ pip3 install --upgrade tensorflow
Requirement already up-to-date: tensorflow in /usr/local/anaconda3/lib/python3.5/site-packages
Requirement already up-to-date: six>=1.10.0 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow)
Requirement already up-to-date: tensorflow-tensorboard<0.2.0,>=0.1.0 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow)
Requirement already up-to-date: wheel>=0.26 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow)
Requirement already up-to-date: protobuf>=3.3.0 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow)
Requirement already up-to-date: numpy>=1.11.0 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow)
Requirement already up-to-date: werkzeug>=0.11.10 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow-tensorboard<0.2.0,>=0.1.0->tensorflow)
Requirement already up-to-date: markdown>=2.6.8 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow-tensorboard<0.2.0,>=0.1.0->tensorflow)
Requirement already up-to-date: bleach==1.5.0 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow-tensorboard<0.2.0,>=0.1.0->tensorflow)
Requirement already up-to-date: html5lib==0.9999999 in /usr/local/anaconda3/lib/python3.5/site-packages (from tensorflow-tensorboard<0.2.0,>=0.1.0->tensorflow)
Requirement already up-to-date: setuptools in /usr/local/anaconda3/lib/python3.5/site-packages (from protobuf>=3.3.0->tensorflow)
unsw@unsw-UX303UB$ python3 -c 'import tensorflow as tf; print(tf.__version__)'
1.3.0
忽略警告:https://github.com/tensorflow/tensorflow/issues/7778
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2'

