
[Tensorflow] Cookbook - Retraining Existing CNNs models - Inception Model
From: https://github.com/jcjohnson/cnn-benchmarks#alexnet
先大概了解模型,再看如果加载pre-training weight。
关于retain这件事,插入231n的一页PPT。总之:数据多,筹码多,再大胆训练更多的weight;否则,别胡闹。
这里有lots of pretrained ConvNets:https://github.com/BVLC/caffe/wiki/Model-Zoo
CS231n Winter 2016: Lecture 5: Neural Networks Part 2

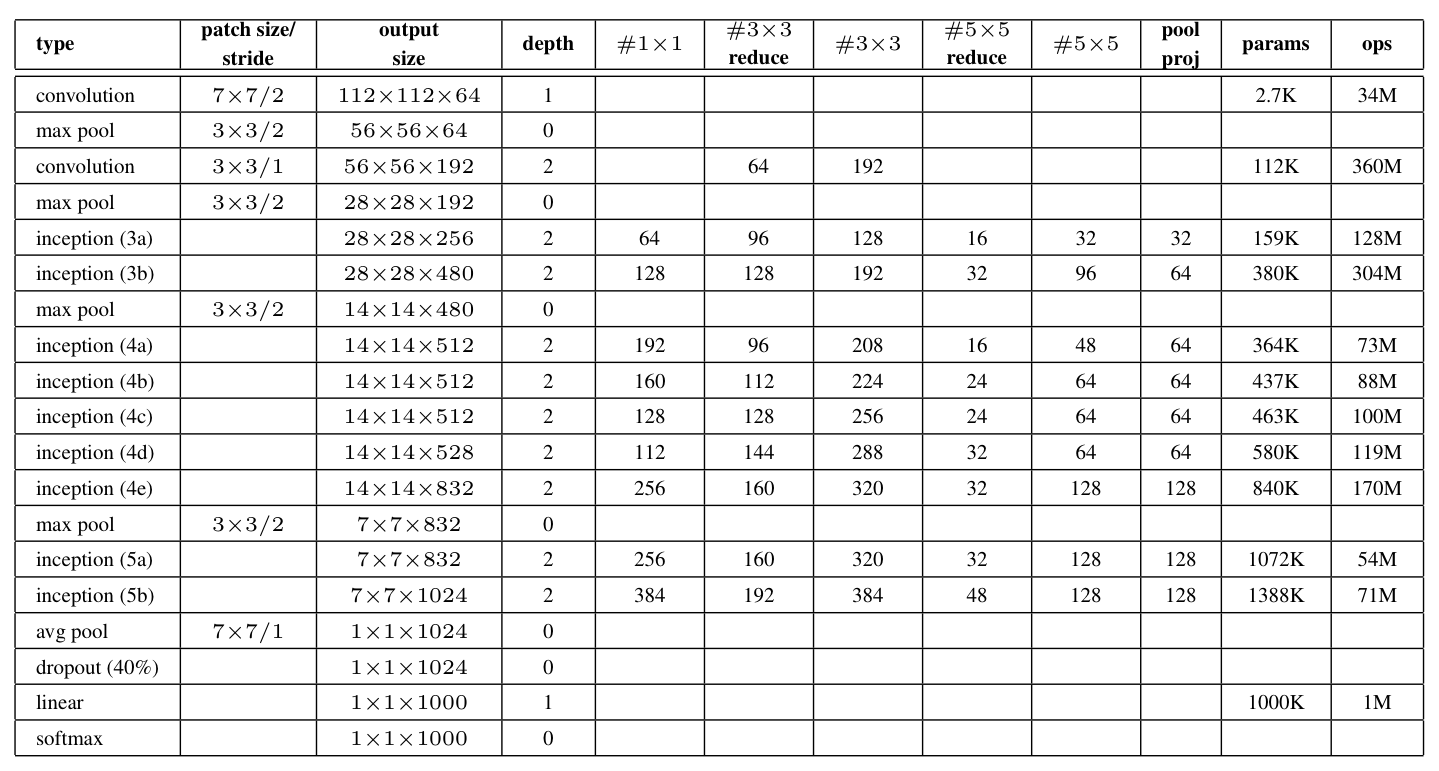
The following models are benchmarked:
| Network | Layers | Top-1 error | Top-5 error | Speed (ms) | Citation |
|---|---|---|---|---|---|
| AlexNet | 8 | 42.90 | 19.80 | 14.56 | [1] |
| Inception-V1 | 22 | - | 10.07 | 39.14 | [2] |
| VGG-16 | 16 | 27.00 | 8.80 | 128.62 | [3] |
| VGG-19 | 19 | 27.30 | 9.00 | 147.32 | [3] |
| ResNet-18 | 18 | 30.43 | 10.76 | 31.54 | [4] |
| ResNet-34 | 34 | 26.73 | 8.74 | 51.59 | [4] |
| ResNet-50 | 50 | 24.01 | 7.02 | 103.58 | [4] |
| ResNet-101 | 101 | 22.44 | 6.21 | 156.44 | [4] |
| ResNet-152 | 152 | 22.16 | 6.16 | 217.91 | [4] |
| ResNet-200 | 200 | 21.66 | 5.79 | 296.51 | [5] |
Top-1 and Top-5 error are single-crop error rates on the ILSVRC 2012 Validation set,
except for VGG-16 and VGG-19 which instead use dense prediction on a 256x256 image. This gives the VGG models a slight advantage, but I was unable to find single-crop error rates for these models.
All models perform better when using more than one crop at test-time.
Speed is the total time for a forward and backward pass on a Pascal Titan X with cuDNN 5.1.
You can download the model files used for benchmarking here (2.1 GB); these were converted from Caffe or Torch checkpoints using the convert_model.lua script.
We use the following GPUs for benchmarking:
| GPU | Memory | Architecture | CUDA Cores | FP32 TFLOPS | Release Date |
|---|---|---|---|---|---|
| Pascal Titan X | 12GB GDDRX5 | Pascal | 3584 | 10.16 | August 2016 |
| GTX 1080 | 8GB GDDRX5 | Pascal | 2560 | 8.87 | May 2016 |
| GTX 1080 Ti | 11GB GDDRX5 | Pascal | 3584 | 10.6 | March 2017 |
| Maxwell Titan X | 12GB GDDR5 | Maxwell | 3072 | 6.14 | March 2015 |
The CNN network we are going to employ uses a very popular architecture called Inception.
Ref: Inception in CNN
Network in Network
GoogLeNet提出之时,说到其实idea是来自NIN,NIN就是Network in Network了。
NIN有两个特性,是它对CNN的贡献:
- MLP(多层感知机)代替GLM(广义线性模型)
- Global Average Pooling
1.
这个idea的理论基础是多层感知机的抽象能力更强。假如我们把从图像中抽取出来的特征称作是这个图像的隐含概念,那么如果隐含概念是线性可分的,那么,GLM抽取出来的特征没有问题,抽象表达能力刚刚好。但是假如隐含概念并不是线性可分的,那么就悲剧了,在只使用GLM的情况下,不得不过度的使用filter来表现这个隐含概念的各个方面,然后在下一层卷积的时候重新将这些概念组合,形成更加抽象的概念。
所以,基于如上,可以认为,在抽特征的时候直接做了非线性变换,可以有效的对图像特征进行更好的抽象。
从而,Linear convolution layer就变成了Mlpconv layer。
值得一提的是,Mlpconv相当于:正常的卷积层后面,再添加一个1×1的卷积层。
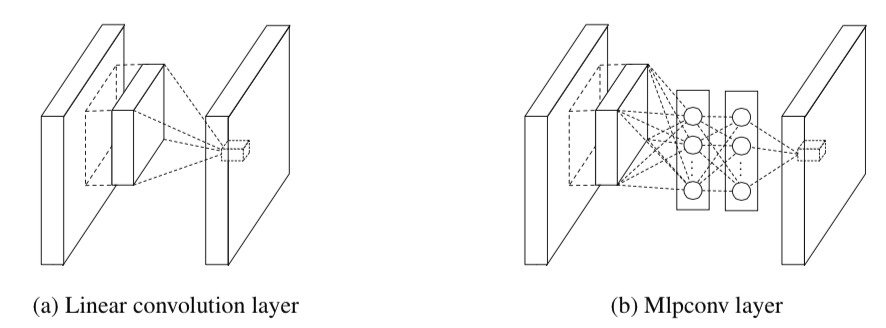
2.
Global Average Pooling的做法是将全连接层去掉。
全连接层的存在有两个缺点:
-
- 全连接层是传统的神经网络形式,使用了全连接层意味着卷积层只是作为特征提取器来提取图像的特征,而全连接层是不可解释的【我认为,全连接层代表特征的组合方式】,从而CNN也不可解释了
- 全连接层中的参数往往占据CNN整个网络参数的一大部分,从而使用全连接层容易导致过拟合。
而Global Average Pooling则是在最后一层,将卷积层设为与类别数目一致,然后全局pooling,从而输出类别个数相同的结果。
使用了 mlpconv 和 Global Average Pooling 之后,网络结构如下:

插曲: http://blog.csdn.net/losteng/article/details/51520555
主要是用来解决全连接的问题,其主要是是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量进行softmax中进行计算。
举个例子
假如,最后的一层的数据是10个6*6的特征图,global average pooling是将每一张特征图计算所有像素点的均值,输出一个数据值,
这样10 个特征图就会输出10个数据点,将这些数据点组成一个1*10的向量的话,就成为一个特征向量,就可以送入到softmax的分类中计算了
上图是从PPT中截取的对比全连接与全局均值池化的差异
原文中介绍这样做主要是进行全连接的替换,减少参数的数量,这样计算的话,global average pooling层是没有数据参数的。
这也与network in network 有关,其文章中提出了一种非线性的 类似卷积核的mlpconv的感知器的方法,计算图像的分块的值。
可以得到空间的效果,这样就取代了pooling的作用,但是会引入一些参数,但是为了平衡,作者提出了使用global average pooling。
Inception
读google的论文,你立马会感到一股工程的气息扑面而来。像此时的春风一样,凌厉中透着暖意。所谓凌厉,就是它能把一个idea给用到节省内存和计算量上来,太偏实现了,所谓暖意,就是真的灰常有效果。
自2012年AlexNet做出突破以来,直到GoogLeNet出来之前,大家的主流的效果突破大致是网络更深,网络更宽。但是纯粹的增大网络有两个缺点——过拟合和计算量的增加。
解决这两个问题的方法当然就是:增加网络深度和宽度的同时减少参数。
为了减少参数,那么自然全连接就需要变成稀疏连接,但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的减少,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是所耗的时间却是很难缺少。
所以需要一种方法,既能达到稀疏的减少参数的效果,又能利用硬件中密集矩阵优化的东风。Inception就是在这样的情况下应运而生。【原来如此,么么哒】
第一步,将卷积分块,所谓的分块其实就是将卷积核分组,既然是分组索性就让卷积和不一样吧,索性使用了1×1,3×3,5×5的卷积核,又因为pooling也是CNN成功的原因之一,所以把pooling也算到了里面,然后将结果再拼起来。这就是最naive版本的Inception。

对于这个Inception,有两点需要注意:
-
- 层级越高,所对应的原始图片的视野就越大,同样大小的卷积核就越难捕捉到特征,因而层级越高,卷积核的数目就应该增加。【越深的位置,视野越大,需更多的特征提取器】
- 1×1,3×3,5×5 只是随意想出来的,不是必须这样。
这个naive版的Inception,还有一个问题,因为所有的卷积核都在上一层的所有输出上来做,那5×5的卷积核所需的计算量就太大了。因而,可以采用NIN中的方法对上一层的输出进行Merge。这样就衍生出了真正可用的Inception。

NB:max-pooling之后的feature_map,若stride为1的时候,max_pooling的输出还可以是长宽不变。
这个结构利用了NIN结构中非线性变换的强大表达能力。
同时,正如上一篇博客决策森林和卷积神经网络二道归一中的隐式数据路由,计算量也大大减少,因为四个分支之间是不需要做计算的。
再同时,还具有不同的视野尺度,因为不同尺寸的卷积核和pooling是在一起使用的。
【决策森林和卷积神经网络二道归一,可以在sci-kit中的随机森林中探讨一下】
需要注意的是,为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
文章中说这两个辅助的分类器的loss应该加一个衰减系数,实际测试的时候,这两个额外的softmax会被去掉。
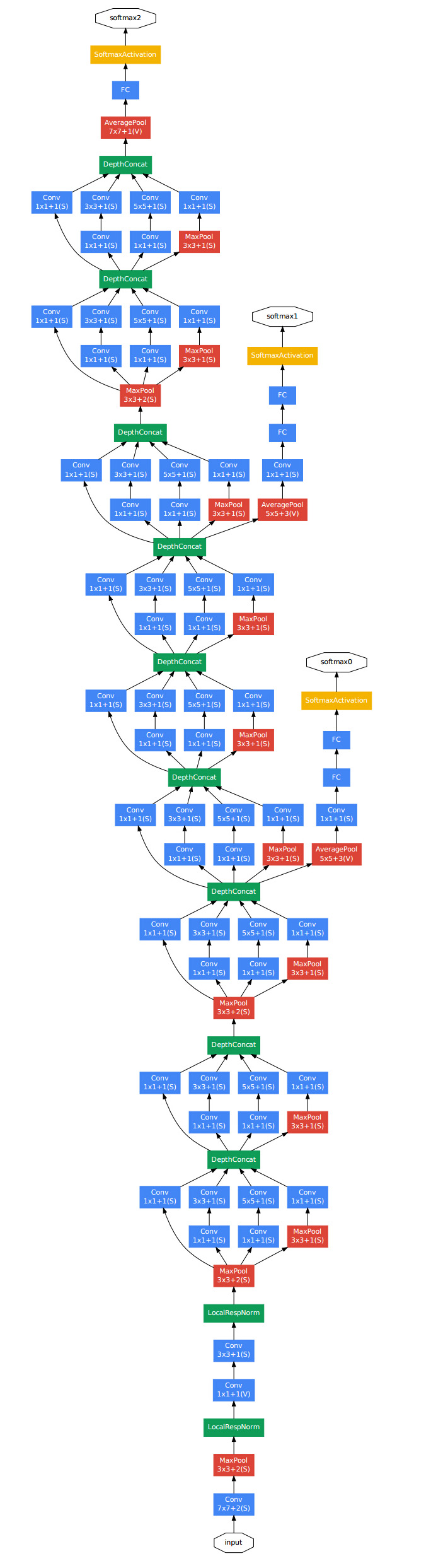
Inception-V2
Google的论文还有一个特点,那就是把一个idea发挥到极致,不挖干净绝不罢手。所以第二版的更接近实现的Inception又出现了。Inception-V2这就是文献[3]的主要内容。
Rethinking这篇论文中提出了一些CNN调参的经验型规则,暂列如下:
-
- 避免特征表征的瓶颈。特征表征就是指图像在CNN某层的激活值,特征表征的大小在CNN中应该是缓慢的减小的。
- 高维的特征更容易处理,在高维特征上训练更快,更容易收敛 【高维容易线性可分】
- 低维嵌入空间上进行空间汇聚,损失并不是很大。这个的解释是相邻的神经单元之间具有很强的相关性,信息具有冗余。
- 平衡的网络的深度和宽度。宽度和深度适宜的话可以让网络应用到分布式上时具有比较平衡的computational budget。
Smaller convolutions

简而言之,就是将尺寸比较大的卷积,变成一系列3×3的卷积的叠加,这样既具有相同的视野,还具有更少的参数。【逐步缩小的感觉】
这样可能会有两个问题,
- 会不会降低表达能力?
- 3×3的卷积做了之后还需要再加激活函数么?(使用ReLU总是比没有要好)
实验表明,这样做不会导致性能的损失。
个人觉得,用大视野一定会比小视野要好么? 叠加的小视野还具有NIN的效果。所以,平分秋色我觉得还不能说是因为某个原因。
于是Inception就可以进化了,变成了

Asymmetric Convoluitons
使用3×3的已经很小了,那么更小的2×2呢?2×2虽然能使得参数进一步降低,但是不如另一种方式更加有效,那就是Asymmetric方式,即使用1×3和3×1两种来代替3×3。如下图所示:

使用两个2×2的话能节省11%的计算量,而使用这种方式则可以节省33%。
于是,Inception再次进化。

注意:实践证明,这种模式的Inception在前几层使用并不会导致好的效果,在feature_map的大小比较中等的时候使用会比较好
Auxiliary Classifiers
在GoogLeNet中,使用了多余的在底层的分类器,直觉上可以认为这样做可以使底层能够在梯度下降中学的比较充分,但在实践中发现两条:
-
- 多余的分类器在训练开始的时候并不能起到作用,在训练快结束的时候,使用它可以有所提升
- 最底层的那个多余的分类器去掉以后也不会有损失。
- 以为多余的分类器起到的是梯度传播下去的重要作用,但通过实验认为实际上起到的是regularizer的作用,因为在多余的分类器前添加dropout或者batch normalization后效果更佳。
Grid Size Reduction
Grid就是图像在某一层的激活值,即feature_map,一般情况下,如果想让图像缩小,可以有如下两种方式:

右图是正常的缩小,但计算量很大。左图先pooling会导致特征表征遇到瓶颈,违反上面所说的第一个规则,为了同时达到不违反规则且降低计算量的作用,将网络改为下图:

使用两个并行化的模块可以降低计算量。
经过上述各种Inception的进化,从而得到改进版的GoogLeNet,如下:

Figure 4是指没有进化的Inception;
Figure 5是指smaller conv版的Inception;
Figure 6是指Asymmetric版的Inception。
Label Smoothing
除了上述的模型结构的改进以外,Rethinking那篇论文还改进了目标函数。
原来的目标函数,在单类情况下,如果某一类概率接近1,其他的概率接近0,那么会导致交叉熵取log后变得很大很大。从而导致两个问题:
-
- 过拟合
- 导致样本属于某个类别的概率非常的大,模型太过于自信自己的判断。
所以,使用了一种平滑方法,可以使得类别概率之间的差别没有那么大,

用一个均匀分布做平滑,从而导致目标函数变为:

该项改动可以提升0.2%。
Rethinking 那篇论文里还有关于低分辨率的输入的图像的处理,在此不赘述了。
参考文献
[1]. Lin M, Chen Q, Yan S. Network in network[J]. arXiv preprint arXiv:1312.4400, 2013.
[2]. Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 1-9.
[3]. Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the Inception Architecture for Computer Vision[J]. arXiv preprint arXiv:1512.00567, 2015.
Retraining Existing CNNs models
# Download/Saving CIFAR-10 images in Inception format
#---------------------------------------
#
# In this script, we download the CIFAR-10 images and
# transform/save them in the Inception Retrianing Format
#
# The end purpose of the files is for retrianing the
# Google Inception tensorflow model to work on the CIFAR-10.
import os
import tarfile
import _pickle as cPickle
import numpy as np
import urllib.request
import scipy.misc
cifar_link = 'https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz'
data_dir = 'temp'
if not os.path.isdir(data_dir):
os.makedirs(data_dir)
# Download tar file
target_file = os.path.join(data_dir, 'cifar-10-python.tar.gz')
if not os.path.isfile(target_file):
print('CIFAR-10 file not found. Downloading CIFAR data (Size = 163MB)')
print('This may take a few minutes, please wait.')
filename, headers = urllib.request.urlretrieve(cifar_link, target_file)
# Extract into memory
tar = tarfile.open(target_file)
tar.extractall(path=data_dir)
tar.close()
objects = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# Create train image folders
train_folder = 'train_dir'
if not os.path.isdir(os.path.join(data_dir, train_folder)):
for i in range(10):
folder = os.path.join(data_dir, train_folder, objects[i])
os.makedirs(folder)
# Create test image folders
test_folder = 'validation_dir'
if not os.path.isdir(os.path.join(data_dir, test_folder)):
for i in range(10):
folder = os.path.join(data_dir, test_folder, objects[i])
os.makedirs(folder)
# Extract images accordingly
data_location = os.path.join(data_dir, 'cifar-10-batches-py')
train_names = ['data_batch_' + str(x) for x in range(1,6)]
test_names = ['test_batch']
def load_batch_from_file(file):
file_conn = open(file, 'rb')
image_dictionary = cPickle.load(file_conn, encoding='latin1')
file_conn.close()
return(image_dictionary)
def save_images_from_dict(image_dict, folder='data_dir'):
# image_dict.keys() = 'labels', 'filenames', 'data', 'batch_label'
for ix, label in enumerate(image_dict['labels']):
folder_path = os.path.join(data_dir, folder, objects[label])
filename = image_dict['filenames'][ix]
#Transform image data
image_array = image_dict['data'][ix]
image_array.resize([3, 32, 32])
# Save image
output_location = os.path.join(folder_path, filename)
scipy.misc.imsave(output_location,image_array.transpose())
# Sort train images
for file in train_names:
print('Saving images from file: {}'.format(file))
file_location = os.path.join(data_dir, 'cifar-10-batches-py', file)
image_dict = load_batch_from_file(file_location)
save_images_from_dict(image_dict, folder=train_folder)
# Sort test images
for file in test_names:
print('Saving images from file: {}'.format(file))
file_location = os.path.join(data_dir, 'cifar-10-batches-py', file)
image_dict = load_batch_from_file(file_location)
save_images_from_dict(image_dict, folder=test_folder)
# Create labels file
cifar_labels_file = os.path.join(data_dir,'cifar10_labels.txt')
print('Writing labels file, {}'.format(cifar_labels_file))
with open(cifar_labels_file, 'w') as labels_file:
for item in objects:
labels_file.write("{}\n".format(item))
先加载graph,定义了all_saver,然后就可以all_saver.restore
import numpy as np
import tensorflow as tf
from random import randint
import datetime
import os
import time
import implementation as imp
batch_size = imp.batch_size
iterations = 30000
seq_length = 40 # Maximum length of sentence
checkpoints_dir = "./checkpoints"
def getTrainBatch():
labels = []
arr = np.zeros([batch_size, seq_length])
for i in range(batch_size):
if (i % 2 == 0):
num = randint(0, 12499)
labels.append([1, 0])
else:
num = randint(12500, 24999)
labels.append([0, 1])
arr[i] = training_data[num]
return arr, labels
def getTestBatch():
labels = []
arr = np.zeros([batch_size, seq_length])
for i in range(batch_size):
if (i % 2 == 0):
num = randint(0, 12499)
labels.append([1, 0])
else:
num = randint(12500, 24999)
labels.append([0, 1])
arr[i] = testing_data[num]
return arr, labels
###############################################################################
# Call implementation
glove_array, glove_dict = imp.load_glove_embeddings()
training_data, testing_data = imp.load_whole_data(glove_dict)
input_data, labels, optimizer, accuracy, loss, dropout_keep_prob \
= imp.define_graph(glove_array)
###############################################################################
# tensorboard
train_accuracy_op = tf.summary.scalar("training_accuracy", accuracy)
tf.summary.scalar("loss", loss)
summary_op = tf.summary.merge_all()
# saver
all_saver = tf.train.Saver()
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
logdir_train = "tensorboard/" + datetime.datetime.now().strftime(
"%Y%m%d-%H%M%S-train") + "/"
writer_train = tf.summary.FileWriter(logdir_train, sess.graph)
logdir_test = "tensorboard/" + datetime.datetime.now().strftime(
"%Y%m%d-%H%M%S-test") + "/"
writer_test = tf.summary.FileWriter(logdir_test, sess.graph)
###############################################################################
# Here, should load checkpoint!!!
###############################################################################
# Later, launch the model, use the saver to restore variables from disk, and
# do some work with the model.
all_saver.restore(sess, checkpoints_dir + "/trained_model.ckpt-20000")
print("Model restored.")
timePoint1 = time.time()
timePoint2 = time.time()
for i in range(iterations):
batch_data, batch_labels = getTrainBatch()
batch_data_test, batch_labels_test = getTestBatch()
# Set the dropout_keep_prob
# 1.0: dropout is invalid.
# 0.5: dropout is 0.5 as default.
sess.run(optimizer, {input_data: batch_data, labels: batch_labels, dropout_keep_prob:0.5})
if (i % 100 == 0):
print("--------------------------------------")
print("Iteration: ", i, round(i/iterations, 2))
print("--------------------------------------")
##############################################################
loss_value, accuracy_value, summary = sess.run(
[loss, accuracy, summary_op],
{input_data: batch_data,
labels: batch_labels,
dropout_keep_prob:1.0})
writer_train.add_summary(summary, i)
print("loss [train]", loss_value)
print("acc [train]", accuracy_value)
##############################################################
loss_value_test, accuracy_value_test, summary_test = sess.run(
[loss, accuracy, summary_op],
{input_data: batch_data_test,
labels: batch_labels_test,
dropout_keep_prob:1.0})
writer_test.add_summary(summary_test, i)
print("loss [test]", loss_value_test)
print("acc [test]", accuracy_value_test)
##############################################################
timePoint2 = time.time()
print("Time:", round(timePoint2-timePoint1, 2))
timePoint1 = timePoint2
if (i % 10000 == 0 and i != 0):
if not os.path.exists(checkpoints_dir):
os.makedirs(checkpoints_dir)
save_path = all_saver.save(sess, checkpoints_dir +
"/trained_model.ckpt",
global_step=i)
print("Saved model to %s" % save_path)
sess.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号