
[Hinton] Neural Networks for Machine Learning - Basic
Link: Neural Networks for Machine Learning - 多伦多大学
Link: Hinton的CSC321课程笔记1
Link: Hinton的CSC321课程笔记2
一年后再看课程,亦有收获,虽然看似明白,但细细推敲其实能挖掘出很多深刻的内容;以下为在线课程以及该笔记的课程重难点总结。
Lecture 01
增强学习:
(这是ng的拿手好戏,他做无人直升机可是做了好久)增强学习的输出是一个动作或者一系列的动作,通过与实际的场合下的环境互动来决定动作,增强学习的目标就是使得选择的每个动作都能够最大化对未来的期望,而且使用一个折扣因子来计算未来的期望,所以可以不用看的太远,而且增强学习很难,因为
- 未来的期望是很难去知道是对还是错的,而且
- 一个标量的期望也给不了太多有用的信息。
所以没法使用百万级别的参数去学习增强学习,其他两个可以,而且增强学习的参数一般也就是100或者1k的级别。
(是不是可以利用贝叶斯学习?)
无监督学习:
在接近40多年中,无监督学习一直被ML社区的人所忽略,大家一直以为无监督学习就是聚类。一个重要的原因是因为大家不知道无监督学习的目标是什么。
一个主要的目标其实是 (参考GMM的G的数量的确定的问题,可以使用dirichlet processing的方法确定其个数)
- 产生输入的内部表征,
- 然后将它用在后续的有监督或者增强学习上;
(后一个例子 不知道怎么理解,理解不了Hinton说的是什么)你能够用双眼去观察物体表面的距离,而不需要脚踩的一步一步的去量。
其他无监督学习的目标就是:
- 他能提供关于输入数据的一个紧凑的,低纬度的表征:高维度输入通常都可以基于一个(或几个)低维度输入(参考线性代数中的基向量表示法),PCA就是广泛的用来查找一个低纬度表征的线性方法;
- 能够提供关于输入数据的具有经济性的高维度表征,例如特征提取:二值特征通常来说是很经济的,因为只需要一位就能表达,而且对于高维的来说,因为是实值特征,所以很多值是接近于0(稀疏的原理);
- 第三个目标就是找到输入的一个合理的聚类,聚类可以被视为一个非常典型的稀疏编码,因为差不多所有的特征中只有一个是非0的(这里暂时理解无能,估计看了后面的,回头看就好多了)。
Lecture 02
前向NN
最底层就是输入层,中间层就是隐藏层,最顶层就是输出层,其中隐藏层如果多于一层,那么就可以称之为"DNN“深层神经网络。
这种网络就是通过从输入到输出之间做一系列的变换,所以在每一层,都可以得到关于输入的一个新的表征,所以本来在之前层相似的表征有可能变得不相似,而在之前层上本来不相似的在这一层却有可能相似。
所以在语音识别中,我们希望随着网络的由底向上,
- 由不同说话人说的相同的事情变得更加的相似,
- 由相同的说话人说的不同的事情变得更不相似。
为了达到这样的目的,就需要每一层的神经元的激活函数是非线性的。
递归神经网络RNN
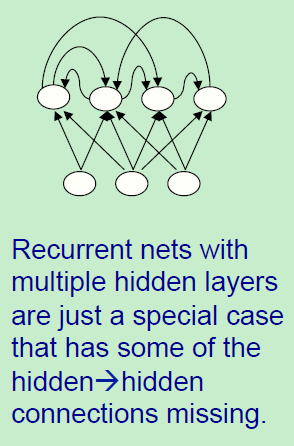
是比前馈神经网络更强大的,如图,它们内部有一些有向环,在他们的连接图中,如上图所示,当从一个节点作为起点,通过图中的路径传播,最后可以回到起始点。
因为它们有着非常复杂的动态,所以这会造成他们很难训练。所以当找到高效的方法去训练RNN的时候,他会带来很好的兴趣结果,因为他很强大。
相比较之下,RNN具有更好的生物真实性。
有着多层隐藏层的RNN是一般递归神经网络的特例情况,这种特性表现出来的就是隐藏层到隐藏层之间的部分链接的消失。(为什么呢?)
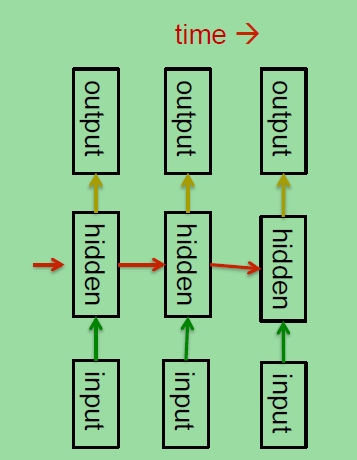
递归网络也是一种很自然的方法去对序列数据进行建模。所以我们所要做的就是将隐藏单元之间建立连接。
如右图,这种网络的隐藏层的节点的连接可以在时间上表现的很深,所以在每个时刻,隐藏单元的状态可以决定下一个时刻的隐藏单元的状态,他们不同于前馈网络的一个地方是他们在每个时刻使用相同的权重,
所以如图中的红色箭头,每个红色箭头所表示的权重矩阵在每个时刻都是相同的。
在每个时刻的时候他们接受输入,同时输出,这里也是使用的相同的权值矩阵。
RNN可以在隐藏层将信息保存很久。但是不幸的是,RNN很难去训练使得他有这种能力。
然而,最近(2012年)的算法却可以有能力这么做。这里介绍由Ilya Sutskever设计的RNN,它是一种特殊的RNN,只是有些轻微的与上图中的RNN不同,他设计的RNN可以预测序列中的下一个字母。Ilya从英文版的维基上通过训练了差不多有5亿个字符串,并成功的预测新的文本。他使用了86个不同的字母,其中有符号,数字,大写字母等等。
在训练之后,一个观察它是否训练好的方法是:
- 它是否能以很高的概率去得到下一个真实发生的字母;
- 另一个方法是看它生成文本内容是什么。
所以最后你需要做的就是给他一串字符串,然后让他预测下个真实字符出现的概率。
对于这个网络来说,提取最有可能出现的字符是没用的,因为这会导致一个现象:比如abcdabcd,在某些类似回文串或者其他情况下会一直循环下去。但是如果在100次中z只出现一次,那么就会发现很多他所学到的信息。
维基百科:
递归神经网络(RNN)是两种人工神经网络的总称。
- 一种是时间递归神经网络(recurrent neural network),
- 另一种是结构递归神经网络(recursive neural network)。
时间递归神经网络的神经元间连接构成有向图,而结构递归神经网络利用相似的神经网络结构递归构造更为复杂的深度网络。RNN一般指代时间递归神经网络。单纯递归神经网络因为无法处理随着递归,权重指数级爆炸或消失的问题(Vanishing gradient problem),难以捕捉长期时间关联;而结合不同的LSTM可以很好解决这个问题。[1][2]
时间递归神经网络可以描述动态时间行为,因为和前馈神经网络(feedforward neural network)接受较特定结构的输入不同,RNN将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。手写识别是最早成功利用RNN的研究结果。[3]
对称连接网络:
他们像RNN但是单元之间的连接是对称的,在两个方向上权重是一样的。John Hopfield和其他人发现这个对称网络比RNN更容易分析,这是因为这个网络中有更多的限制,而且这个网络遵守能量函数定律。
比如不能像RNN一样经过一段路径后又回到起始点。
- 没有隐藏单元的对称连接网络叫做“Hopfield网络”。
- 有隐藏单元的对称连接网络叫做“Boltzmann Machines”。
几何观点看待感知机
(还是通过纯数学梯度下降的表达好理解)
什么是感知机不能做的
但是一旦人为的动手去设计特征,那么就相当与在给感知机进行限定了。
对于感知机来说有更多灾难性的例子,当我们试图使用简单的模式去决定的时候,而且通过循环(下图中的意思)的方法对它们进行平移的时候还要求保留原有的特性。但是现在的想法是即使被平移了,也要去正确的识别它。
假设将像素作为特征,问题就是是否能找到一个二值阈值单元去区分有着相同像素值的两个不同的模式。假设一个是正类,一个是负类。答案是不行。
如上图所示,都是一维向量,对于模式a来说,有四个黑色像素,他们之间的相对位置固定,只是在往右移动,模式B也是相对位置不变,一直右移,只是循环的。
这就是证明一个二值神经元无法决策在具有相同数量像素的情况下的模式:
- 对于模式A来说,有四个像素的位置被激活。所以每个像素会有模式a的四种不同的平移情况。这也意味着这个决定单元(最顶层的)的结果是4*sum(所有的权重)就是排列组合。
- 对于模式B来说,也是同样的4*sum(所有的权重)。
但是对于感知机来说,为了正确的决策,模式a的每个情况都需要提供比模式b的每个单独的情况更多的输入。
但是当你将模式a的所有情况相加和模式b的所有情况相加之后发现,这是不可能的,因为他们提供同样的输入个数。
所以这就证明了在允许循环平移的情况下一个二值单元无法区分不同的模式。这就是Minsky和Papert团队的不变原理的一个特例情况。
为什么这样的结果对于感知机来说是灾难性的:因为模式识别去识别模式需要经受的住在变换的情况下还需要正确的去识别。Minsky and Papert’的“组不变性定理”认为感知机的学习部分无法去学习当转换来自于一个组的情况。这就是当时说的,感知机的学习部分被夸大了。
感知机其实还是能识别的,但是不得不自行组织特征,这也就是感知机难的地方。为了识别上述那种平移的情况,需要更多的特征单元去识别那些包含的子信息。所以模式识别的技巧部分必须通过手动编码的特征检测器,而不是学习过程。
这种暂时的结论导致了感知机其实不好,所以NN也不好的言论。
好一点的结论是NN只有在如果我们学习特征检测器的时候他才是强大的。这对于只是学习权重特征检测器还是不够的,我们需要他们能够自主学习特征检测器。
第二代的NN就是下个课要说的如何学习特征检测器,但是这也花费了人们20多年的时间的探索。所以,没有隐藏单元的网络是非常受限的。
如果我们只是简单的增加一些线性单元是无济于事的,因为结果还是线性的。我们能使得他更加强大,通过将一些手动编码隐藏单元放入其中,但是他们却不是真正的隐藏单元,因为这还是人为的。
仅仅将输出弄成非线性的还是不够的,我们需要的是多层自适应非线性隐藏单元,问题就是我们如何去对这个网络进行训练,我们不仅仅需要对最后一层像感知机一样适应所有的权值,所以这很难。
具体的,学习隐藏层的权值也等于学习特征,这很难是因为没人直接告诉我们,当激活或者未激活的时候隐藏层应该怎么做,真正的问题也就是我们如何解决如何隐藏层的权值使得他能够转变成解决具体问的特征。
Lecture 03
对于多层NN来说,通常不会使用感知机的训练方法,所以也就 没有多层感知机的说法。
维基百科:
A multilayer perceptron (MLP) is a class of feedforward artificial neural network. An MLP consists of at least three layers of nodes. Except for the input nodes, each node is a neuron that uses a nonlinear activation function. MLP utilizes a supervised learning technique called backpropagation for training. Its multiple layers and non-linear activation distinguish MLP from a linear perceptron. It can distinguish data that is not linearly separable.
Multilayer perceptrons are sometimes colloquially referred to as "vanilla" neural networks, especially when they have a single hidden layer.
可见,老爷子不太喜欢MLP这个叫法。
在训练结束后,也许不能得到完美的结果但是仍然能够得到对完美的权值的逼近权值集合,在学习率足够小的情况下,并且训练的时间足够长,得到的结果就越能靠近完美值;
并且在当其中的样本的任意两个特征高度相关的时候,训练就会变得很慢,而且当这里例子中的鱼和chips吃的一样多的时候,那么就没法决定这个价格是因为鱼而定的,通常会学习到一样的结果。

扰乱学习 (Learning by using perturbations)
- 就是首先先随机初始化权重,然后针对某一个具体的权重上的权值,通过随机扰动,如果这次的改变的确提升了最后的效果,那么就保留这次的改变,这就像是一种增强学习一样。但是这种做法非常的低效,因为不但需要计算多层的前馈,而且还要反复的试验就为了一个权重(而且还不是在一个样本上测试),那么当权重的数量多起来后,那么时间复杂度完全不可想象;
- 另一个随机扰动权重的学习方法的问题是在学习的最后,任何的较大的扰动都会使得结果变坏,那么可想而知这个网络会变得很动荡。 这时候为了计算时间的减少,肯定提出了并行的想法,就是先对所有的权重进行扰动,然后在看由权重改变所带来的结果的改变(可想而知这完全没用,这和每次随机初始化没什么差别,而且比单个扰动还不靠谱);
- 一个较好的想法是随机扰动隐藏单元的激活值,如图中红点和绿点。但是如果知道了在一个样本上如何扰动隐藏单元的激活值并使得模型效果更好,那么计算这几个隐藏单元所涉及的权重也是很简单的,这当神经元的数量远远少于权重的数量的时候是好的方法,但是这些缺陷,都不如这个BP。
BP的想法
就是不知道隐藏单元应该怎么做,但是能够计算这个误差的改变是如何随着一个隐藏单元的激活值改变而改变的。
所以从反方向考虑,不去寻找合适的激活值去训练隐藏单元,而是使用误差导数去分配给每个隐藏单元激活值,告诉他们怎么逼近。而且因为一个隐藏单元的改变会改变之后所有单元的激活值,所以在误差导数回传的时候就需要综合考虑 了,就是要对所有的隐藏单元都要同时考虑。
将所有输出层的误差导数传递到下一层的和他有链接关系的神经元上,这就是BP的由来。
怎么使用由Bp计算的导数
指出如何在一个多层网络中获得所有权重的误差导数是学习整个网络的关键。但是在全部明白各异学习过程之前还是有很多的问题需要去处理。例如,需要决定更新权重的频率,还有在使用大网络的情况下如何阻止网络过拟合。
Bp是一个高效计算对于单个训练样本的情况下误差关于每个权重的求偏导的方法,但是这不是一个学习算法,所以需要指定其他的东西去得到一个合适的学习方法。(是方法,但不是学习算法)
为了得到一个完整的具体的学习过程,需要知道如何运用这些误差导数:
- 优化问题,如何在每个独立的样本上使用误差导数去查找一个好的权重集合(在lecture6中具体介绍);
- 泛化问题,如何确保学到的权重对于非训练集的样本一样适用(就是可以用来做预测,在lecture7中具体介绍)。
对于使用权重导数上的优化问题:
1、更新权值的频率:
- Online训练一个样本就进行更新,因为是采用的在线更新的形式,所以在权重空间上它的走向就是之字形的;
- Full batch:在扫完所有的训练数据后进行一次权值更新,这个方法的缺点就是有可能会初始化不好,而且如果遇到一个超大的训练集合,我们不希望扫描所有的训练样本就为了更新某些权值,而且这些权值还是不好的。
- 实际上,不需要这么干,可以把上述的优点结合起来,就是第三个方法Mini-batch:随机的将样本分成几个mini-batch,然后训练一个mini-batch就更新一次权值,他不会像在线学习一样那么左右动荡,而且也不会因为训练样本太大而权重更新太慢,或者训练困难;
2、每次更新权重的步长多大(lecture6中具体说明):
- a、是使用一个固定的学习率?每次的下降步长固定的;
- b、还是使用一个自适应全局学习率?让机器决定,如果是稳步向前的那么就加大这个学习率;
- c、还是对每个分开的连接都使用一个自适应的学习率?这样就使得有些权重更新的快,有些权重更新的慢;
- d、不要使用梯度方向的下降?如上面说道的一个狭长的椭圆,那个情况的梯度的方向反而不是我们希望的方向,我们希望的是直指中心的方向。
如何防止模型的过拟合:训练的数据包含的从输入映射到输出的规律信息,但是它通常有两种噪音在里面:
- 目标值有时候不可信(通常是一些小的错误);
- 采样错误,比如一些特别的样本被我们选择了,而这些样本却是类似异常点的存在,会让网络偏离好的方向。当我们拟合模型的时候,无法知道这个规律是真的,还是来自于采样错误带的,而模型要做的就是同时拟合不同的规律,如果模型很有可调控性,那么他就可以很好的拟合采样错误,这其实是个灾难。
避免拟合
对于NN来说,一般是过拟合的情况大于欠拟合的情况,而对应过拟合的情况一般有下面几种方法:
- Weight-decay:就是在目标函数上加上所有权重的平方和
- Weight-sharing:参考CNN,他的一个特点就是权重共享
- Early stopping:通过使用learing curve(之前的博文中有的),当发现模型训练开始下降的时候停止训练
- Model averaging:对于差不多的训练模型来说,在期望的部分将这几个模型进行一起求平均,这可以减少错误(such as 随机森林)
- Bayesian fitting of neural nets:这是一个模型平均的理想模型
- Dropout:在训练的时候随机让某些隐藏单元失效
- Generative pre-training:更加的复杂,而且超出了本课的要求,会在后面的课中讲解。
Lecture 04
误差平方和不好!
到目前为止对于训练一个NN采用的都是误差平方和的方法,对于线性神经元来说,这是很适合的。但是误差平方和的方法有很多缺点:
如果一个合理的输出是1,但是实际上最后的逻辑神经元输出的却是0.0000000001,这对于逻辑单元来说几乎没法做误差梯度,因为这差不多在一个高原上 而下降的范围却总是在水平面上,而且即使最后犯的错误很明显的情况下,还是会导致需要花很长很长的时间去改变一点点的权值,而且如果试图去指派不同的概率来表现互斥的类别标签,虽然输出的最后是1(所有概率的和一定是1),但是得到的A的概率却有可能和B的概率一样大(就是在输出层采用了多个逻辑单元来表示多类,但是却有可能得到两个类别一样的概率的情况)。
这时候就会想,是不是cost函数可以换个更好的?既能表达互斥的结果,还能是一个合适的概率型的cost函数。有啊!
那换成哪一个好?
如果我们使用了softmax作为输出层,那么什么cost函数才适合呢?
答案就是关于正确结果的错误log概率,这就是我们想要最大化这个log概率来得到正确的结果。所以上图右上角的式子,是通过将真实目标值和softmax预测的输出log值相乘,这个被称之为交叉熵损失函数(图中是单样本情况,而且这里的Zi 其实等于Wi * xi ,只是这里没写出来,所以在真实计算的时候要注意这点)。
它有着很好的特性,因为假设一个神经元的输出是很接近0 的时候而他的真实值却是很接近1 那么,交叉熵损失函数就会很大,而且上图中的0.000001比0.0000000001好的原因是后者得到的惩罚更重,说明他分类比前者的还不靠谱。
而且这个交叉熵损失函数的偏导可以很好的解决之前的损失平方函数的导数的问题,
所以上图求导结果,也就是权值的改变梯度 yi-ti,可以从-1到+1,但是当两者相差差不多的时候这个值就会接近于0,也就是 这个输出值是接近真实目标值的,
- 那么这个神经元所对应的权值就不会怎么变,
- 其他错误的神经元对应的权值就会不断的改变直到最后收敛。
(这里还可以看Ng 的UFLDL 里面有更详细的说明)
【Neuro-probabilistic language models可以放入“IR类别”单独讲解,单词聚类的一种新思路】

Lecture 05
机器不同于人类,所以没法轻松的让机器进行感知,而且在工程学上还是在心理学上都没有普遍接受的解决方案。
- 第一个方法是使用足够多的不变性特征;
- 第二个方法是在对象上用个框框起来这样就能对这些像素进行归一化;【便于统计?】
- 第三个方法是使用特征复制,然后池化他们,这种方法被称之为“CNN”。【略,没必要说】
第一个方法(将会在随后介绍)是通过使用具有相对于摄像机和视网膜中明确的位置部件功能的层次结构。
在拥有足够的不变性特征的情况下,就需要将它们都聚集到一个对象或者一副图上。不需要直接的去表达特征之间的关系,因为这些关系是基于其他特征的基础上获得的。
大量的观点表明我们所需要的就是一个大的特征袋(bag of features),因为在拥有重叠和冗余的特征的情况下,一个特征可以告诉你其余的两个特征是怎么关联的。
不幸的是,如果你做识别任务的话,你得到一群由不同的对象的部分组成的特征集合。而这就是在识别的道路上误入歧途了。所以需要避免由不同对象部分上得到的信息而形成的特征。 【判定特征是否属于同一个目标,难】
第二个方法叫judicious normalization(这个暂时不知道怎么翻译够习惯)

心理学家认为用心理旋转来处理这个形状的方法不是正确的方向定向。Hinton认为这完全是胡说:这个大写字母R在做心里旋转之前就可以很完美的被人类识别。不过的确在识别的时候会知道这是上下颠倒的,但是这也是为了知道如何进行旋转(人类是将旋转发生在识别之前)。但是在正确识别这个是一个正常的R还是一个镜像R(左右相反),还是需要心理旋转的,但是识别完全不需要。【通过笔画的顺序性就可以识别,比如在某人背部写字,她能识别出来写得是什么】
一个强力的归一化方法是:当训练识别器的时候,需要很好的分割并且用正立的(非颠倒)图像去拟合这个正确的盒子。在测试一些杂乱的图像的时候,可以在不同的位置和尺度上使用任何可能的盒子。这个方法被广泛的应用到检测正立的事物任务上,例如识别在未分割过的图像中的人脸和门牌号,当识别器能够处理位置和尺度不变性的时候将会更加的高效,所以我们才需要在测试各种可能的盒子的时候采用粗糙的网格。
【识别整体轮廓等高层语义信息其实不需要太清晰的图像……呀!神经网路是高层语义在上,细节在下;这是不是跟人的识别顺序正好相反!有问题?可以刨坑的伟大idea】
第三个方法是CNN,such as 为手写数字识别设计的卷积神经网络
CNN是基于复制特征的想法上建立的。
因为对象可以移动和在不同的像素上显示,如果有个特征检测器在图像的一个地方很有用,那么也可以在图像的其他地方一样有用,
(UFLDL中卷积章节的图像的“自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征”)
所以可以用这个思路在图像的不同位置上建立相同的特征检测器。
在位置上交叉复制可以大大的减少自由参数的数量,所以图中一共27个像素其实只有9个不同的权重而已,并且我们不满足一个特征提取器,
所以可以有多个特征图,每个图内部的特征提取器是一样的,不同图上不同,所以不同的特征图就学到了不同的特征,这可以使的图中的每个块可以用许多不同风格的特征来表示。
【卷积可以提取基本的图像特征,我以为这么好理解一些】
通常在文献中有很多的问题比如重复的特征检测器到底获得了什么,许多人说获得了平移不变性,Hinton认为这不是真的,至少在神经元的激活上不是真的,所以如果观察这个激活部分,重复特征得到的是同变性,而不是不变性。
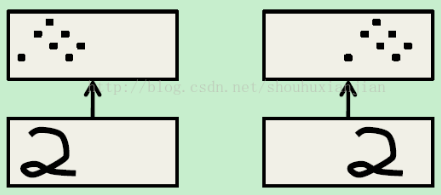
上图中的一个图(数字2),和上面的黑点表示激活的神经元,
第二个是一个平移后的图,注意到黑点(激活的神经元)同样平移了,所以图像变了,而表征也随着图像改变而改变,这是同变性,而不是不变性。是有不变性存在,但是那是知识(比如识别这个就是2),所以如果学习重复特征检测器,如果知道如何在一个区域中检测一个特征,那么就知道如何在其他区域检测同样的特征,并且主遇到在激活上获得了同变性,在权重中获得了不变性。
如果想要在激活中获得不变性,那么就需要对重复特征检测器进行池化操作,所以就能在一个DNN的每一层得到一个小数量的平移不变性。
这里的一个优势就是减少了输入到下一层的数量,所以我们能够拥有更多不同的特征图,允许我们在下一层中学习更多不同的特征,事实上采用四个邻居特征检测器的最大值比均值效果要好(应该是说max-pool比average-pool要好)。
这里有个问题就是在经过了几次池化后,我们损失了特征的精确位置信息,如果我们想识别人脸,这个完全不用担心,因为我们已经得到了一些眼睛,鼻子,嘴巴等相对的位置信息,这些已经足够说明这是个人脸了,
但是如果想精确得到这个人脸属于谁的,就需要使用眼睛之间的,鼻子和嘴巴之间精确的空间关系,而这些信息在CNN中已经被丢弃了。
第一个让人印象深刻的CNN模型就是Yann LeCun的Le Net模型:
1、有着许多的隐藏层;
2、每层都有许多的重复单元图;
3、在层之间有池化操作(将附近的重复单元的输出进行池化),先对毗邻的单元进行池化,然后在送到下一层;
4、也是一个广泛的网络能够及时字符都是重叠的也能马上适应,所以不需要做独立字符分割的预操作;
5、采用了更智能的方法去训练整个系统,而不是一个识别器,所容易可以在一端输入像素,在另一端得到整个zip编码,在训练系统的过程中采用了一种被称为最大边缘(maximum margin)的方法,但是在这个网络出来的时候这个最大边缘的方法还没有被发明。
现在这个网络在北美已经使用并且处理了近乎10%的支票识别,所以这是有很大的实际价值,在Yann的主页上有很多的demo,Hinton说应该都去看看,因为它们展示了如何很好的适应在尺寸、方向、位置、数字的重叠上的不变性,而且这些使用的各种背景噪音足以让大部分方法望尘莫及。
LeNet-5的结构如上图所示,在输入部分就是像素,然后是一系列的特征图并跟随着子采样,所以在C1特征图中,有6个不同的图,每个都是28×28,每个局部感受野差不多是3×3的(这里Hinton应该错了 ,应该是5×5的才对),而且他们的权重都是一起被约束的,所以每个图只有9个参数(应该是25个),这样可以使得学习更加的高效,也意味着只需要更少的数据,在这个特征图之后,就是被称为子采样,现在称为池化。所以通过对C1中的一群邻居重复特征的输出进行池化,可以得到一个更小的图,并将给下一层提供输入,而下一层就是发掘更复杂特征的一层(这也是DL的思想),随着网络的前进,得到的特征更加的复杂,但是也有更多的位置不变性。
【进一步地,模拟产生数据】
这个工作的第一个例子就是由Hofmann和Tresp做的,他们试图对一个钢厂所发生的事情进行建模,他们想知道各种输入变量与钢厂出来的东西之间的关系,实际上他们使用一个旧的Fortran模拟器来模拟钢厂。当然这个模拟器不够真实,只能提供近似值。所以他们有着真实数据和一个模拟器,他们所能做的就是运用这个模拟器去生成许多综合数据,然后将生成的数据加入到实际数据中,并且认为这样得到的效果比只使用真实数据要好。如果Hinton没记错,这个大Fortran模拟器产生的数据只值几十个额外的真实样本,但是他们的想法还是很不错的。当然如果你生成了许多综合数据,这可以让学习学的更久,所以在学习的速度上,更高效的方法是将知识通过类似连接或者权重约束的方法和Net-5中一样来处理。
【引入投票机制】
他们在这个数据集上获得了35个错误,上图中每个错误的上方是正确的答案,下面的两个数字是模型得到的前两个最接近的答案,通过观察发现错误的结果总在正确的结果附近(只有5个样本不是,就是红框部分),
通过更多的工作例如建立不同的模型然后使用一个共识(投票系统)可以将结果降低到只有25个错误,而这已经接近人类完美水准了。
在真实彩色图像中,我们可能需要注入一些先验知识,因为假设我们不将先验知识注入到网络中,而是通过所有的知识像上述一样去生成额外的训练样本,那么对于当前的网络来说这个计算量就太大了。
ImageNet实际上是说的机器图像(就是我们电脑上的图像),只是他暂时只收录了1.2百万张而已,而所谓的分类任务就是将他们很好的进行了标记。
现在这些图像已经手动标记了差不多1000类,但是这不是完全可靠的(因为有时候会标记错误),因为一张图像中有可能有2个类别,而只标记了一个,所以为了使得任务更加的合理,计算机视觉系统可以允许有5个赌注(估计就是可以保留模型预测的前5个不同的结果吧),而且当5个赌注中的一个是等于人类给定这个图像的标签的,那么就算正确。
这仍然是个局部化的任务,因为许多的计算机视觉系统会采用BOF 特征袋的方法,对于整幅图或者图像的一个象限来说,他们知道特征是什么,但是不知道在哪,这可以让他们进行对象识别,但是却不知道准确的位置信息。
这可不像人类的行为,除了人类大脑受伤得了平衡综合症,那么他们只知道识别对象,但是却不知道在哪,
所以对于局部化任务来说,就需要在对象上设置一个盒子,一旦识别到了对象,那么至少得要有50%的部分是正确框起来的。【仅仅是框起来,但边缘的位置其实还是很重要的】
在这个任务上,人们试了许多当前现有的最好的计算机视觉方法,有来自 Oxford 和 the French National Research Labs Inria和Xerox's European Research Center和其他大学的团队都在研究这个任务,然后发现的确很难。这些计算机视觉系统通常都使用复杂的多阶段系统。这些系统的早期阶段是通过手调来优化数据的参数的,然后在系统的顶层阶段通常都是一个学习算法,但是也没法学到所有的方法。
有例如DNN所执行的方法中,当通过BP进行训练,这个网络不需要end-to-end学习,因为在前面的特征提取器中的参数会被BP告知如何调整才能接近最后的类别决策部分。
【卷积核的参数是在训练中不断变化的,是自动收敛过程中最终获得的】
- 上图是这个数据集中的测试集上的一些例子(在第一课中已经观察了一些),看第一个猎豹的图,虽然图中有一个对象,但是却并不完整。有Alex Krizhevsky的DNN给出的未归一化的概率作为结果预测值,可以看到结果还是挺可信的,如果结果不是猎豹,那么第二个选项就是豹,还有例如第三个答案,雪豹等等;
- 第二个图中有着许多的对象而我们感兴趣的对象只占了一小块的区域,但是这个网络能够正确的预测这是子弹列车,但是也有着其他的赌注,例如高速列车和 电力机车等。【如果观察这幅图,可以看到还有许多其他的东西可以被标记,例如占图像区域比列车比重还大的屋顶,在这类图像中,就需要能够适应很多可选择的目标的情况】
- 最后一张图没有复杂的背景,这个对象很好的被独立出来,但是这个网络没有第一次就猜中这个,但是在前五个赌注中倒是有了,但是这也说明这个网络没法对所有的东西都能够很好的识别,看着下面这几个判断,他们到都是合情合理的标签,如果眯起眼睛看,在不能很好的观察这个图像的时候,你会发现,其他的几个标签是多么的自然,这也说明这个网络犯错还算合情合理。
【DCNN】 # 不知道说这个是有什么具体的价值
Alex Krizhevsky的网络如上图所示,他是神经网络的先驱Yann LeCun的网络(早期用来做数字识别,后期用来做真实对象识别)的更深的版本,DCNN,然后通过从Yann团队,begino团队和其他团队那里学到的知识,并提出了这个DNN用来做真实视觉。
它有7层隐藏层,比通常的更深而且不算上最大池化层这一层(即有7层卷积层)。前面的层是卷积的,如果我们有更大的计算机,那么就可以只用局部感受野,而且不需要绑定任何权重(就是不权重共享),但是在对他们做卷积的时候,必须剔除一些参数,所以需要在考虑计算机计算时间的情况下减少训练数据;最后两层都是全局连接的,而且整个模型的大部分参数都在这里,差不多在这部分中两层之间有16百万的参数存在,最后两层所干的的事情就是将从前面提取的局部特征进行很好的组合,很显然因为有很多的组合存在,所以这里才需要这么多的参数;而且在每个隐藏层中的激活函数还是ReLu,因为这种激活函数的学习速度比逻辑单元学的更快,但是他们的代价也大;Hinton同样也会使用归一化,当其他单元有更强的激活值的时候,就使用一层去压缩单元的激活值,所以会有一个边界检测器,在相当弱的边界下也能获得激活。而且在周围如果有更多强烈的单元,那些都是不相关的。
上图是Hinton等人的一些小技巧,用来明显的改善这个网络的生成能力。
首先,通过使用转换的形式增强这些数据:上图中的是一个对256×256的图进行下采样的技巧,但是不直接使用原图,Alex Krizhevsky通过在这些图中随机提取224×224的块,这使他有了更多的图像去训练,并且有助于转换和不变性,即使是对于CNN来说,这也仍然是有用的。
他还使用了图像的左右翻转,这使得数据量一下子成了两倍,他没有用上下翻转,因为他认为重力(垂直方向)是很重要的,而左右翻转不会改变些什么,除非都是些文字才会有差异,对于自然图像来说,无所谓。
在测试的时候,他不止使用一个块,他使用不同的块,四个角,中间,这样加起来就5个块了,然后接着用左右翻转,测试数据一共就有10倍了,他通过将这些所有的测试数据输送到网络,然后对最后的结果进行综合,在顶层中,也是大部分参数的所在的地方,他使用一个新的正则化技术,Dropout,这非常的有效,并且可以防止网络过拟合,这个技术在最后的结果中占了不少的比重。
Hinton会在随后的课程中讲解这个,但是对于现在粗略的说就是:每次你表现一个训练样本,都将一层中近乎一半的隐藏节点忽略掉,也就是说这层中的其他隐藏单元不能相互牵制了,不能通过修正错误(例如BP)来影响这层中的其他单元(因为都默认忽略了),这就使得每个神经元看上去更加的独立了(关于Dropout的请看具体的论文),这也就是说每个神经元可以在做有意义的事情的基础上更加的独立,并且不同于这层中的其他神经元,所以Drouput阻止了层间单元过多的合作,许多的合作是有益于你和训练数据的,但是如果这个测试分布明显不同,那么所有的合作都会导致过拟合。
Alex的这个网络需要较高的硬件要求,但是现在这些配置也就几千美元(额,,,好贵)。Alex也是个很好的程序员,他在两块Nvidia GTX 580GPU上部署了CNN,每个GPU上都有超过500个流处理器,因为显卡这种擅长算术,但却不擅长其他的事情(就是喜欢矩阵计算,打个比方,GPU只能单纯的干一件事情,而CPU是全能),因为GPU擅长矩阵乘法等,所以如果你将隐藏层的激活向量基于样本数量上堆叠在一起,那么就是个矩阵了,然后就可以通过下一层的权重乘以这个矩阵来最后进行作为下一层的输入,如果矩阵很大,那么GPU刚好发挥优势,差不多可以将速度提升30x,而且他还有很宽的内存,这些都是nn所需要的,因为在NN中需要等待另一个权重然后才能相乘来进行激活,所以在面对百万级别的权重的时候,不能将它们都放入cache中。通过使用这些,他能在一个礼拜以内训练好这个网络,而且这也让他能在测试的时候快速的将从10个块中的结果进行组合,所以能够以帧的速率进行计算。在将来,希望能够将这个网络分布式的在一个大数量核心上,随着核心的日益便宜,很多在Google人们已经能够这样实验了,而且在不同的机器上的传输更快的话,那么就能够在更大的网络上进行分布了,Google已经有了这样的模拟网络了,这个网络有着1.7十亿个链接,随着发展,这个DNN肯定会比老式的计算机视觉系统更快,因为它几乎不需要手动设计,而且可以在巨大数据集上进行计算和提取信息。Hinton认为在所有的最好的对象识别系统上,至少在静态图像上,可以使用DNN了。

