

[IR] Index Construction
抛出问题
倒排索引的构建
Three steps to construct Inverted Index as following:

海量term排序
最难的step中:
- Token sequence.
- Sort by term.
- Dictionary & Postings
第2步中的最现实的问题是:假如100G的terms如何排序?
参考文档:http://home.ustc.edu.cn/~zhufengx/ir/pdf/solution.pdf【不错的课件内容】
External Sorting Algorithm (外排)
基于块的排序索引方法 BSBI(blocked sort-based indexing algorithm)

注释:
4. 文档集读取
5. 排序
6. 排序结果fi 存放到disk
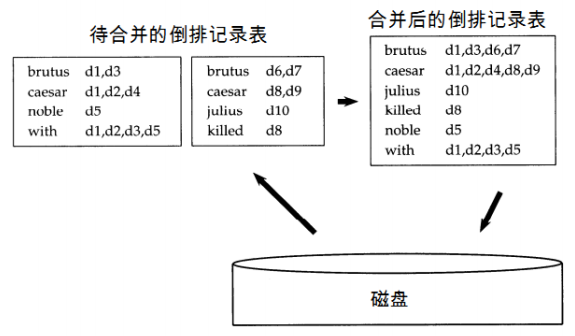
7. Merge 这些排序结果为一个整体的Inverted Index list. 使用小窗口一点点地放入min-heap,
堆顶端输出的是Inverted Index list的 dictionary部分,由小变大的顺序(因为fi 已排序)
注解:说白了就是“两个有序链表的合并”。
-
- 需要将词项映射成词项ID,必须事先知道词项的排序(知道整个词 典)。
- 所有的块共享一个全局的大词典。
- 如果在每块的处理中,不将词项映射成词项ID,而是直接对“词项-文 档ID”对进行排序,排序的代价将大大增加(整数的比较VS字符串的 比较)。
小缺陷
因为实际使用的是ID。并且一开始就整理出所有的词项 ID—文档 ID 并对它们进行排序的做法。
既然要排序,所以相对耗时。
内存式单遍扫描索引构建方法

注释:
拥有同一hash value的terms的排序设计:
Insert-at-back and move-to-front heuristic
每个块fi 建立新dict;
去除了高代价的sort最后一步依然是 MergeBlocks(.)
突出特点
用了词对索引的直接关联。还有1个比较大的特点是他不经过排序,直接按照先后顺序构建索引。
Term list采用了hash的方式去查找,故构建的过程中不需要排序。
动态索引 - Dynamic Indexing
同时保持着两个索引:一个是大的主索引,另外一个是用于存储新文档信息的辅助索引。
其中辅助索引保存在内存中,辅助索引用于对文档新增内容建立索引,用户在检索时对主索引和辅助索引一起检索,当辅助索引很大时候,将其与磁盘中的主索引进行合并;

注释:
Main Index在Disk; Auxiliary Index在Memory。
可以视为 Immediate Merge 与 No merge 的一个折中。
由于每个倒排记录在 log2(T/n)层 的每一层中都只处理一次,因此整个索引构建的时间是Θ(T*log2(T/n))。
引伸:
求Disk中最后留下的Index的数量。
We use |C| to denote the total size of the document collection, and M to denote the memory size.
Let's assume that: C = h*M
For i in [0, log2h] { X = [h - (2i – 1)] mod [2i+1] If X belong to (0, 2i], exist in column. Else, not exist. }
The sum of existing X is the answer.
大数据量排序
数据多到内存装不下怎么办?
假设内存有100M容量
比如1G的数据,分10份,每份100M。先用快排让每一份各自排好序,然后写到文件中。这10份100M的 文件这个时候已经有序了。
这10份每份取9M,一共90M,使得他们合并。合并后的结果放到10M的缓存区中,满了就clear,IO到 文件中。
理解
有点小根对的意思,例如总是将最小的数字放入10M缓存中,放满后也就是top 10M小的elements,然后save to disk中。
End.
