
[IR] Inverted Index & Boolean retrieval
教材:《信息检索导论》
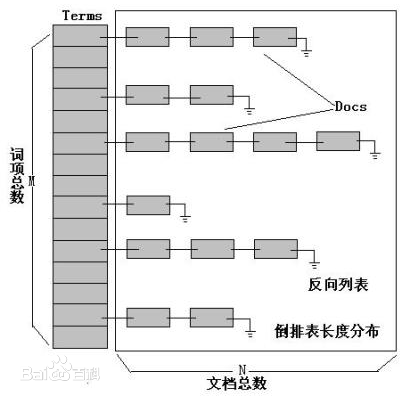
倒排索引
How to build Inverted Index?
1. Token sequence.
2. Sort by terms.
3. Dictionary & Postings
查询同时包含两单词的文档
【Qword1 and Qword2】
等高线式前进。
O(x+y)

【Qword1 and not Qword2】
O(m*log2n) = m个中的any one都要查看n个中是否也有(二分查找)。
【Qword1 or not Qword2】
O(m+n)
【Qword1 and Qword2 and Qword3 and ...】
借助 min-heap, 找 list 的时间。
Update min-heap: O(log2k), k = number of lists.
O(Total_Length * log2k)
Galloping Search
跳表:【Qword1 and Qword2】
- 源于skip pointers, but how to placing skip?
- L1/2
Normally, len(a) < len(b)
O( 2a*log2(b/a) ) [ better than O(a*log2b) 二分查找 ]
Stage1: Σi = 1log2(ni) = log2Πi=1(ni) <= log2(Σ(ni)/a)a (柯西不等式) = log2(b/a)a = a*log2(b/a)
Stage2: 二分查找的cost与Stage1相近(因为都是2的指数级增长)

Pharse Queries
Biword Indexes
Ref: 《信息检索导论》第二章总结
排列组合。但总有些组合是没用的,导致False Positive增加。
所以要Filter out.
将两个词看成一个item,即在dictionary中都是两个词为一组。
比如invert and revert,则会变成invert and和and revert;但是这种做法使得倒排记录表迅速变大。
这种方法的缺点很多:
(1)不适用于单词查询。
(2)倒排记录表太大。
(3)查询有时还不正确。需要进行后过滤(即在查询词组中过滤一遍)
折中策略
(1)对于单个单词出现次数非常多,而组成一个词组后出现次数大大减少的词组,用biword index;
(2)对于那些经常被用户查询的词组,使用biword index;
(3)其余使用positional index【接下来的内容】
Positional Index --> Proximity Queries
支持位置信息查询

k词邻近搜索
对两个单词的位置有要求,比如两个单词必须“相距五个单词以内”。


Figure, 邻近搜索中两个倒排记录表 p1 和 p2 的合并算法,算法寻找两个词项在 k 个词之内出现的情形,
返回一个三元组<文档 ID,词项在 p1中的位置,词项在 p2中的位置>的列表。
Step:
步骤(3)表示,再搜索M上的后面的词的话,这一段就不需要再看了,也就是N链其实是需要被遍历一遍。

End.

