

[Spark内核] 第37课:Task执行内幕与结果处理解密
本课主题
- Task执行内幕与结果处理解密
引言
这一章我们主要关心的是 Task 是怎样被计算的以及结果是怎么被处理的
- 了解 Task 是怎样被计算的以及结果是怎么被处理的
Task 执行原理流程图
[下图是Task执行原理流程图]

- Executor 会通过 TaskRunner 在 ThreadPool 来运行具体的 Task,TaskRunner 内部会做一些准备的工作,例如反序例化 Task,然后通过网络获取需要的文件、Jar等
- 运行 Thread 的 run 方法,导致 Task 的 runTask 被调用来执行具体的业务逻辑处理
- 在Task 的 runTask内部会调用 RDD 的 iterator( ) 方法,该方法就是我们针对当前 Task 所对应的 Partition 进行计算的关键之所在,在处理内部会迭代 Partition 的元素并交给我们先定义的 Function 进行处理
- ShuffleMapTask: ShuffleMapTask 在计算具体的 Partition 之后实际上会通过 ShuffleManager 获得的 ShuffleWriter 把当前 Task 计算的数据具体 ShuffleManger 的实现来写入到具体的文件。操作完成后会把 MapStatus 发送给 DAGScheduler; (把 MapStatus 汇报给 MapOutputTracker)
- ResultTask: 根据前面 Stage 的执行结果进行 Shuffle 产生整个 Job 最后的结果;(MapOutputTracker 會把 ShuffleMapTask 執行結果交給 ResultTask)
Task 执行内幕源码解密
- 当 Driver 中的 CoarseGrainedSchedulerBackend 给 CoarseGrainedExecutorBackend 发送 LaunchTask 之后,CoarseGrainedExecutorBackend 在收到 LaunchTask 消息后,首先会判断一下有没有 Executor,没有的话直接退出和打印出提示信息,有的话会反序例化 TaskDescription,在执行具体的业务逻辑前会进行3次反序例化,第一个是 taskDescription,第二个是任务 Task 本身进行反序例化,还有的是RDD 的反序例化。
[下图是 CoarseGrainedExecutorBackend.scala 接收 LaunchTask case class 信息后的逻辑]
然后再发 LaunchTask 消息,里面会创建一个 TaskRunner,然后把它交给一个 runningTasks 的数据结构中,然后交给线程池去执行 Thread Pool。
[下图是 Executor.scala 中的 launchTask 方法]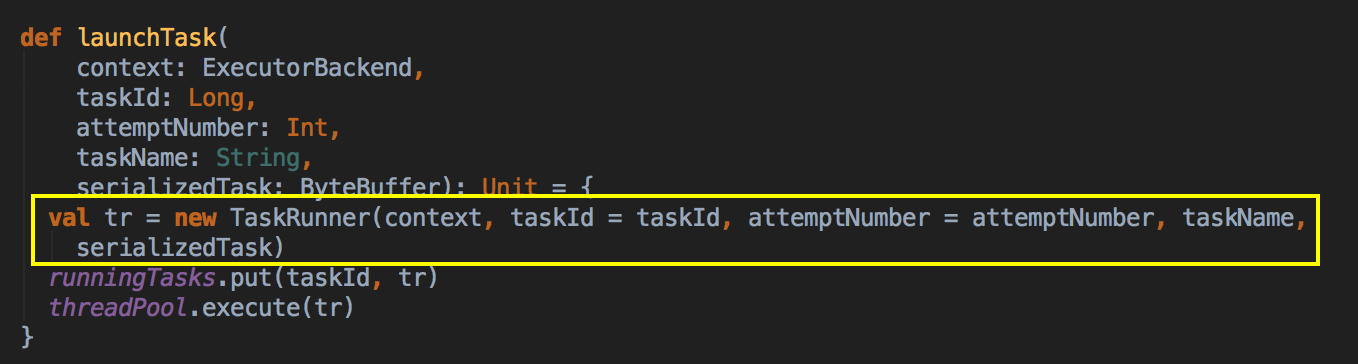
- Executor 会通过 TaskRunner 在ThreadPool 来运行具体的 Task,在 TaskRunner 的 run( )方法中首先会通过调用 stateUpdate 给 Driver 发信息汇报自己的状态,说明自己的RUNNING 状态。
[下图是 Executor.scala 中的 TaskRunner 类]
[下图是 Executor.scala 中的 run 方法]
[下图是 ExecutorBackend.scala 中的 statusUpdate 方法]
- TaskRunner 内部会做一些准备的工作,例如反序例化 Task 的依赖,这个反序例化得出一个 Tuple,然后通过网络获取需要的文件、Jar等;
[下图是在 Executor.scala 中 run 方法内部具体的代码实现]
-
在同一个 Stage 的内部需要共享资源。在同一个 Stage 中我们 ExecutorBackend 会有很多并发线程,此时它们所依赖的 Jar 跟文件肯定是一样的,每一个 TaskRunner 运行的时候都会运行在线程中,这个方法会被多个线程去调,所以线程需要一个加锁,而这个方法是有全区中的。这主要是要防止资源竞争。下载一切这个 Task 需要的 Jar 文件,我们通 Executor 在不同的线程中共享全区资源。
[下图是 Executor.scala 中的 updateDependencies 方法]
- 在 Task 的 runTask 内部会调用 RDD 的 iterator( ) 方法,该方法就是我们针对当前 Task 所对应的 Partition 进行计算的关键之所在,在处理内部会迭代 Partition 的元素并交给我们先定义的 Function 进行处理对于 ShuffleMapTask,首先要对 RDD 以及其他的依赖关系进行反序例化:
[下图是 Executor.scala 中 run 方法内部具体的代码实现]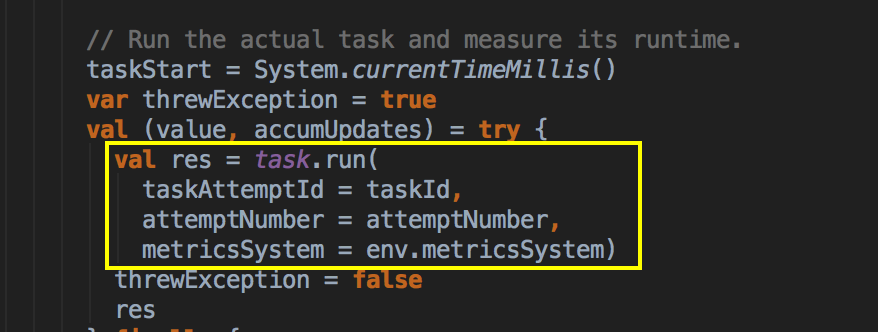
[下图是 Task.scala 中的 run 方法]
因为 Task 是一个 abstract class,它的子类是 ShuffleMapTask 或者是 ResultsMapTask,是乎我们当前的 Task 是那个类型。
[下图是 ShuffleMapTask.scala 中的 runTask 方法]
[下图是 RDD.scala 中的 iterator 方法]
[下图是 RDD.scala 中的 computeOrReadCheckpoint 方法]
最终计算会调用 RDD 的 compute 的方法具体计算的时候有具体的 RDD,例如 MapPartitionsRDD.compute,其中的 f 就是在当前 Stage 计算具体 Partition 的业务逻辑代码。
[下图是 RDD.scala 中的 compute 方法]
[下图是 MapPartitionsRDD.scala 中的 compute 方法]
- 调用反序例化后的 Task.run 方法来执行任务并获得执行结果,其中 Task 的 run 方法调用的时候会导致 Task 的抽象方法 runTask 的调用
[下图是 Executor.scala 中 run 方法内部具体的代码实现]
- 把执行结果序例化
[下图是 Executor.scala 中 run 方法内部具体的代码实现]
- 运行 Thread 的 run 方法,导致 Task 的 runTask 被调用来执行具体的业务逻辑处理
- 对于 ResultTask
[下图是 ResultsMapTask.scala 中的 runTask 方法]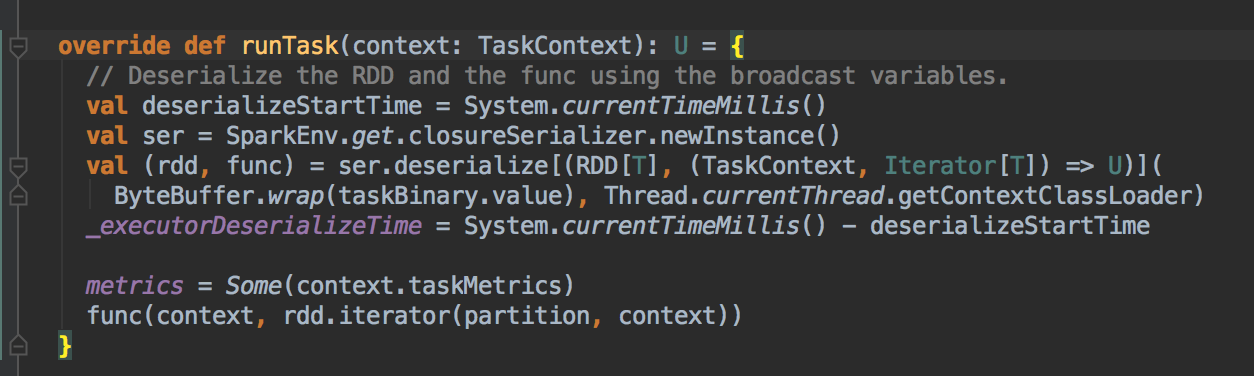
- 在 Spark 中 AkaFrameSize 是 128MB,所以可以扩播非常大的任务,而任务
- 并根据大小判断不同的结果传回给 Driver 的方式
- CoraseGrainedExectorBackend 给 DriverEndpoint 发送 StatusUpdate 来传执行结果
[下图是 Executor.scala 中 run 方法内部具体的代码实现]
[下图是 CoraseGrainedExectorBackend.scala 中 statusUpdate 方法]
[下图是 DriveEndPoint.scala 中 receive 方法]
- DriverEndpoint 会把执行结果传给 TaskSchedulerImpl 处理,然后交给 TaskResultGetter 去分别处理执行成功和失败时候的不同情况,然后告X DAGScheduler 任务处理结的情况重
[下图是 TaskSchedulerImpl.scala 中 statusUpdate 方法]
[下图是 TaskResultsGetter.scala 中 handleSuccessfulTask 方法]
[下图是 TaskSchedulerImpl.scala 中 handleSuccessfulTask 方法]
[下图是 TaskSetManager.scala 中 handleSuccessfulTask 方法]
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第37课:Task执行内幕与结果处理解密
Spark源码图片取自于 Spark 1.6.0版本
