高性能页面加载技术--BigPipe设计原理及Java简单实现
1.技术背景
动态web网站的历史可以追溯到万维网初期,相比于静态网站,动态网站提供了强大的可交互功能.经过几十年的发展,动态网站在互动性和页面显示效果上有了很大的提升,但是对于网站动态网站的整体页面加载架构没有做太大的改变.对于用户而言,页面的加载速度极大的影响着用户体验感.与静态网站不同,除了页面的传输加载时间外,动态网站还需考虑服务端数据的处理时间.像facebook这样大型的用户社交网站,必须考虑用户访问速度问题,
传统web模式采用了顺序处理的流程来处理用户请求.即用户向客户端发送一个请求后,服务器处理请求,加载数据并渲染页面;最后将页面返回给客户端.整个过程是串行执行的,具体流程如下:
1. 浏览器发送一个HTTP请求到Web服务器。
2. Web服务器解析请求,然后读取数据存储层,制定一个HTML文件,并用一个HTTP响应把它发送到客户端。
3. HTTP响应通过互联网传送到浏览器。
4. 浏览器解析Web服务器的响应,使用HTML文件构建了一个的DOM树,并且下载引用的CSS和JavaScript文件。
5. CSS资源下载后,浏览器解析它们,并将它们应用到DOM树。
6. JavaScript资源下载后,浏览器解析并执行它们。
整个流程按必须顺序执行,不能重叠,这也是为什么传统模式随着网络速度的提升访问速度没有很大提升的原因.解决顺序执行的速度问题,一般能想到的就是多线程并发执行.Facebook 的前端性能研究小组采用浏览器和服务端并发执行的思路,经过了六个月的努力,开发出了BigPipe页面异步加载技术,成功的将个人空间主页面加载耗时由原来的5 秒减少为现在的2.5 秒。这就是我们本文要介绍的高性能页面加载技术---BigPipe.
2.BigPipe设计原理
BigPipe的主要思想是实现浏览器和服务器的并发执行,实现页面的异步加载从而提高页面加载速度.为了达到这个目的,BigPipe首先根据页面的功能或位置将一个页面分成若干模块(模块称作pagelet),并对这几个模块进行标识.举个例子,在博客园个人首页包括几大板块,如头部信息,左边信息,博文列表,footer等.我们可以将首页按这些功能分块,并用唯一id或名称标识pagelet.客户端向服务端发送请求后(发出一次访问请求,如请求访问个人博客首页),服务端采用并发形式获取各个pagelet的数据并渲染pagelet的页面效果.一旦某个pagelet页面渲染完成则立刻采用json形式将该pagelet页面显示结果返回给客户端.客户端浏览器会根据pagelet的id或标识符,在页面的制定区域对pagelet进行转载渲染.客户端的模块加载采用js技术.具体流程如下:
1. 请求解析:Web服务器解析和完整性检查的HTTP请求。
2. 数据获取:Web服务器从存储层获取数据。
3. 标记生成:Web服务器生成的响应的HTML标记。
4. 网络传输:响应从Web服务器传送到浏览器。
5. CSS的下载:浏览器下载网页的CSS的要求。
6. DOM树结构和CSS样式:浏览器构造的DOM文档树,然后应用它的CSS规则。
7. JavaScript中下载:浏览器下载网页中JavaScript引用的资源。
8. JavaScript执行:浏览器的网页执行JavaScript代码
前三个阶段由Web服务器执行,最后四个阶段(5,6,7,8)是由浏览器执行。所以在服务器可以采用多线程并发方式对每个pagelet进行数据获取和标记生成页面,生成好的pagelet页面发送给前端.同时在浏览器端,对css,js的下载可以采用并行化处理.这就达到了浏览器和服务器的并发执行的效果,这样使得多个流程可以叠加执行,加少了整体页面的加载时间.浏览器端的并行化交给浏览器自己处理不需要我们做额外工作.在BigPipe中主要是处理服务端的并行性.
3. BigPipe的实现原理
在BigPipe,一个用户请求的生命周期是这样的:在浏览器发送一个HTTP请求到Web服务器。在收到的HTTP请求,并在上面进行一些全面的检查, 网站服务器立即发回一个未关闭的HTML文件,其中包括一个HTML 标签和标签的开始标签。标签包括BigPipe的JavaScript库来解析Pagelet以后收到的答复。在标签,有一个模板,它指定了页面的逻辑结构和Pagelets占位符。例如:



1 <html> 2 <head> 3 <title>struts2-bigpipe-plugin</title> 4 <script type="application/javascript"> 5 function replace(id, content) { 6 var pagelet = document.getElementById(id); 7 pagelet.innerHTML = content; 8 } 9 </script> 10 </head> 11 <body> 12 <table width="100%"> 13 <tr border="1"> 14 <td width="50%" bgcolor="#f0f8ff"><div id="one">${one}</div></td> 15 <td width="50%" bgcolor="#faebd7"><div id="two">${two}</div></td> 16 </tr> 17 <tr> 18 <td width="50%" bgcolor="#7fffd4"><div id="three">${three}</div></td> 19 <td width="50%" bgcolor="#8a2be2"><div id="four">${four}</div></td> 20 </tr> 21 </table>
注意:这个html没有以</body> </html>结束,这是一个未关闭的页面模板(这里定义为index.ftl,是freemarker模板).如果是封闭的页面,那么浏览器就不会等待也不接收服务器之后返回的数据.所以这里必须设置为未关闭的页面.
服务端返回给客户端页面模板(index.ftl)后,并行的处理各个pagelet的数据并和将数据填补pagelet对应的页面显示模板(如下面代码的one.ftl)中得到一个渲染完成的页面.如果某个pagelet的页面渲染完成,那么就将pagelet的id或标示符,html内容及相关数据组成json数据立刻发送给客户端.客户端根据pagelet的id和html内容,以及之前传回来的模板(index.ftl),利用模板(index.ftl)中的JavaScript解析函数将pagelet的数据加载到页面对应的位置.下面是对应上面模板中id为one的pagelet的页面模板(one.ftl):
<h1>Part One</h1> <h2>你好:${user.name},现在时间时 ${time} </h2>
服务端将数据填充到one.ftl页面后,将构建json数据,并立即将json数据发送给客户端(浏览器).下面是服务器发回给客户端的pagelet one对应的数据.为了使解析的js书写简单(index.ftl的js解析方法replace()),这里没有直接转换为json,而是用html数据返回给前端:
<script type="application/javascript\"> replace("one", "<h1>Part One</h1> <h2>你好:John,现在时间时 23:20 </h2>" ); </script>
如果用json表达的话,一般是以下格式,但是需要将index.ftl的replace()函数改写:
<script type=”text/javascript”> replace( {id:”one”, content:”<h1>Part One</h1> <h2>你好:John,现在时间时 23:20 </h2>”,
css:”[..]“,
js:”[..]“,
…} );
</script>
这样浏览器就会完成pagelet one的加载,其他pagelet按此方法进行.它们之间不是顺序执行的,而是并行执行,因为在服务端采用并行方式.上面便是整个bigpipe的执行过程了.
4.java实现代码
这里以我的博客园个人首页做例子,实现一个基于servlet的BigPipe简单demo.因为是简单的demo,没有实现数据库访问和页面的渲染操作,只是做一个简单的模仿.
4.1 页面模板
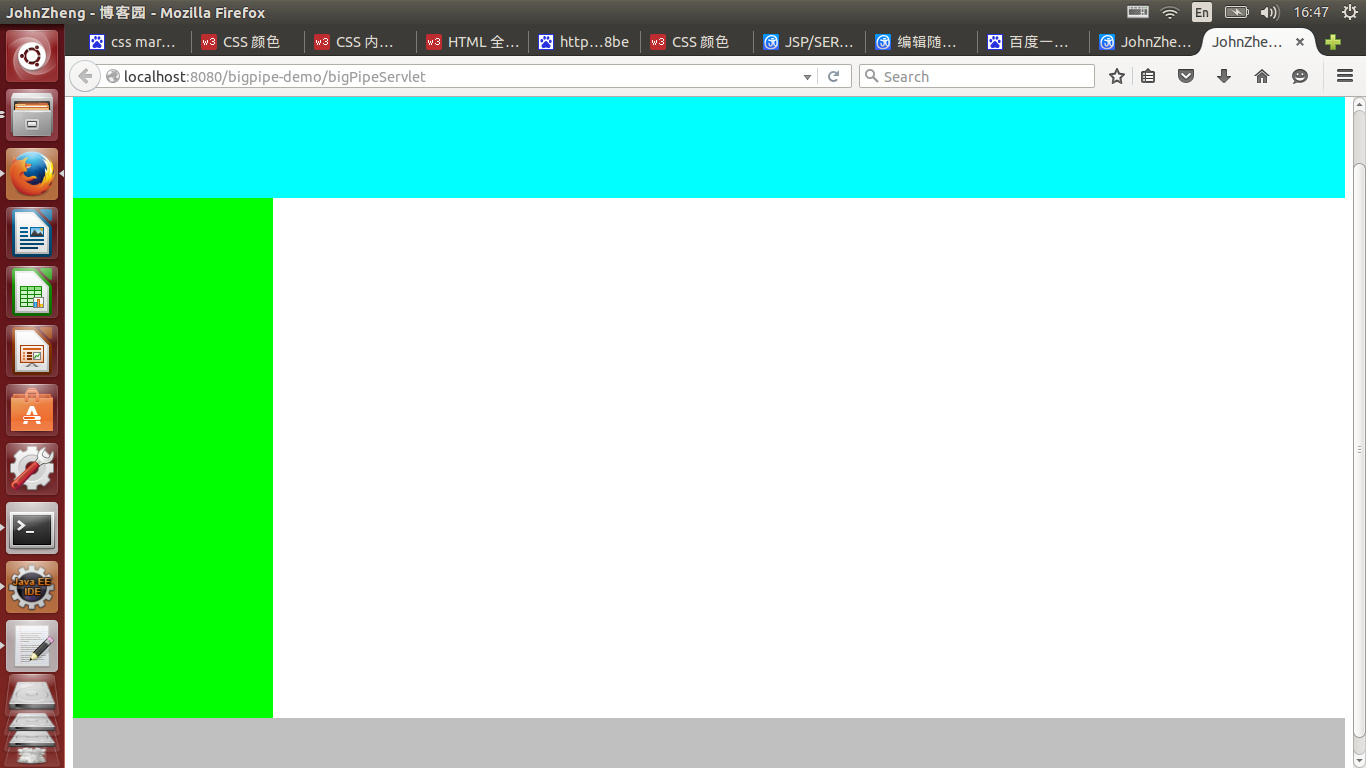
首先我将个人模块主页分为header(顶部),sideBar(左边),mainContent(文章列表),footer四个pagelet,写了一个简单的页面框架,代码如下:
<html xmlns="http://www.w3.org/1999/xhtml" lang="zh-cn"> <head> <meta http-equiv="Content-Type" content="text/html;charset=utf-8"/> <title>JohnZheng - 博客园</title> <!-- JS 解析函数 --> <script type="application/javascript"> function replace(id,content) { var pagelet = document.getElementById(id); pagelet.innerHTML = content; } </script> </head> <body> <div style="margin:0px 0px;padding:0px 0px;"> <!-- header 头部 --> <div id="header" style="height:150px;background-color:#00FFFF;"></div> <div style="clear:both"></div> <div id="main"> <!--sideBar 侧边栏容器 --> <div id="sideBar" style="width:200px;height:420px;float:left;background-color:#00ff00;"></div> <!--mainContent 主体内容容器--> <div id="mainContent" style="float:left;width:800px; height:420px;padding-left:10px;"></div> <div style="clear:both"></div> </div><!--end: main --> <div style="clear:both"></div> <!--footer --> <div id="footer" style="background-color:#C0C0C0;height:60px;text-align:center"></div> </div><!--end: home 自定义的最大容器 --> <!--</body>--> <!--</html>-->
这里需要注意以下几点:
- 模板页面必须是未封闭的.
- 因为这里只是模仿实现,所以我在模板中加入了Js解析函数.如代码注解处.该解析函数用于将之后的服务端返回的pagelet解析并插入到模板中的对应位置.
- 本案例是采用freemarker来写的(其实在该案例中,将后缀名改为html也是可以的)
- 虽然此处没有引入css和js,但如果文件中有css,js,一般是将css放在头部,而js则是返回所有的pagelet之后再将js返回给前端.
显示效果如下图所示:
4.2 各个Pagelet
未各个pagelet编写视图模板,该视图模板负责显示对应的pagelet,规定了pagelet的显示样式.所以案例中编写了header.ftl,sideBar.ftl, mainContent.ftl, footer.ftl. (这里的文件名不需要和pagelet的div id对应).
顶部视图模板 header.ftl:
<div> <h1><a href="http://www.cnblogs.com/jaylon/">John Zheng</a></h1> <h2>知止而后定,定而后能静,静而后能安,安而后能虑,虑而后能得.</h2> </div><!--end: blogTitle 博客的标题和副标题 --> <div id="navigator"> 博客园 首页 新闻 新随笔 联系 管理 订阅 <div> <!--done--> 随笔- 4 文章- 0 评论- 2 </div><!--end: blogStats --> </div><!--end: navigator 博客导航栏 -->
左边视图模板 sideBar.ftl
<div> <h3 class="catListTitle">公告</h3> 昵称:JohnZheng</br> 园龄:6个月</br> 粉丝:4</br> 关注:1</br> </div>
文章列表视图模板 mainContent.ftl
<div class="forFlow"> </br> <div class="day"> <div class="dayTitle"> <a href="http://www.cnblogs.com/jaylon/archive/2015/10/29.html">2015年10月29日</a> </div> <div> <a href="http://www.cnblogs.com/jaylon/p/4918914.html">Spring 入门知识点笔记整理</a> </div> <div ><div >摘要: spring入门学习的笔记整理,主要包括spring概念,容器和aop的入门知识点笔记的整理.<a href="http://www.cnblogs.com/jaylon/p/4918914.html" class="c_b_p_desc_readmore">阅读全文</a></div></div> <div ></div> <div >posted @ 2015-10-29 19:59 JohnZheng 阅读(395) 评论(2) <a href ="http://i.cnblogs.com/EditPosts.aspx?postid=4918914" rel="nofollow">编辑</a></div> </div> </br> <div > <div> <a href="http://www.cnblogs.com/jaylon/archive/2015/10/28.html">2015年10月28日</a> </div> <div > <a href="http://www.cnblogs.com/jaylon/p/4908075.html">spring远程服务知识梳理</a> </div> <div> <div>摘要: 本文主要是对spring中的几个远程调度模型做一个知识梳理.spring所支持的RPC框架可以分为两类,同步调用和异步调用.同步调用如:RMI,Hessian,Burlap,Http Invoker,JAX-WS. RMI采用java序列化,但很难穿过防火墙.Hessian,Burlap都是基于http协议,能够很好的穿过防火墙.但使用了私有的对象序列化机制,Hessian采用二进制传送数据,而Burlap采用xml,所以Burlap能支持很多语言如python,java等.Http Invoker 是sping基于HTTP和java序列化协议的远程调用框架,只能用于java程序的通行.Web service(JAX-WS)是连接异构系统或异构语言的首选协议,它使用SOAP形式通讯,可以用于任何语言,目前的许多开发工具对其的支持也很好. 同步通信有一定的局限性.所以出现了异步通信的RPC框架,如lingo和基于sping JMS的RPC框架.<a href="http://www.cnblogs.com/jaylon/p/4908075.html">阅读全文</a></div> </div> <div >posted @ 2015-10-28 14:31 JohnZheng 阅读(424) 评论(0) <a href ="http://i.cnblogs.com/EditPosts.aspx?postid=4908075" rel="nofollow">编辑</a> </div> </div> </br> <div> <div > <a href="http://www.cnblogs.com/jaylon/archive/2015/10/24.html">2015年10月24日</a> </div> <div > <a href="http://www.cnblogs.com/jaylon/p/4905769.html">Spring Security 入门详解</a> </div> <div ><div class="c_b_p_desc">摘要: spring security主要是对spring应用程序的安全控制,它包括web请求级别和方法调度级别的安全保护。本文是主要介绍spring security的基础知识,对spring security所涉及的所有知识做一个梳理。<a href="http://www.cnblogs.com/jaylon/p/4905769.html" class="c_b_p_desc_readmore">阅读全文</a></div></div> <div></div> <div>posted @ 2015-10-24 11:47 JohnZheng 阅读(331) 评论(0) <a href ="http://i.cnblogs.com/EditPosts.aspx?postid=4905769" rel="nofollow">编辑</a></div> </div> </div><!--end: forFlow -->
尾部视图模板 footer.ftl
</br>Copyright ©2015 JohnZheng
4.3 BigPipe 案例核心代码
现在是构建一个Servlet负责将访问个人博客首页的请求用BigPipe方式来加载页面.这里我构建了一个BigPipeServlet实现bigPipe的整个流程.当用户请求BigPipeServlet时
- 首先将index.ftl页面模板返回给流浏览器,因为只返回一个页面框架所以用户很快就可以看到上面显示的那张图的效果.
- 将index.ftl发送出去以后,BigPipeServlet采用并行的方式获取数据和渲染界面(这部分工作交给PageletWorker.java)这个线程完成,
- 如果某个pagelet渲染完成则BigPipeServlet将起flush给浏览器.
- 如果所有的pagelet都flush完成了,那么封闭页面,告诉浏览器已经完成请求则不用接受服务器端的数据.
下面是BigPipeServlet.java的代码:
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.setHeader("Content-type", "text/html;charset=UTF-8"); response.setCharacterEncoding("UTF-8"); PrintWriter writer = response.getWriter(); //这里是得到一个渲染的页面框架 String frameView = Renderer.render("index.ftl"); //将页面框架返回给前端 flush(writer,frameView);
//并行处理pagelet ExecutorService executor = Executors.newCachedThreadPool(); CompletionService<String> completionService = new ExecutorCompletionService<String>(executor); completionService.submit(new PageletWorker(1500,"header","pagelets/header.ftl")); //处理头部 completionService.submit(new PageletWorker(2000,"sideBar","pagelets/sideBar.ftl"));//处理左边信息 completionService.submit(new PageletWorker(4000,"mainContent","pagelets/mainContent.ftl"));//处理文章列表 completionService.submit(new PageletWorker(1000,"footer","pagelets/footer.ftl"));//处理尾部 //如果某个pagelet处理完成则返回给前端 try { for(int i = 0;i < 4; i++){ Future<String> future = completionService.take(); String result = future.get(); flush(writer,result); } } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } //最后关闭页脚 closeHtml(writer); } /** * 返回给前端 * @param writer * @param content */ private void flush(PrintWriter writer,String content){ writer.println(content); writer.flush(); } /** * 关闭页面 * @param writer */ private void closeHtml(PrintWriter writer){ writer.println("</body>"); writer.println("</html>"); writer.flush(); writer.close(); }
这里采用了ExecutorCompletionService来负责并行处理pagelet,ExecutorCompletionService是一个包含Executor 和阻塞队列的类.提交的线程会交给Executor执行,执行的结果放到阻塞队列中,所以只要从队列中获取数据就可以了,简化了多线程操作.
代码中为每个pagelet设置了不同的处理时间,这样在浏览器可以看到不同页面的在不同时间显示.以上代码中还引用了另一个类,PageletWorker. 该类主要负责pagelet的业务逻辑处理,获取所需数据及页面的渲染.最终将渲染完成的页面交给BigPipeServlet处理.PageletWorker.java代码如下:
public class PageletWorker implements Callable<String> { //模拟完成业务逻辑的运行时间(pagelet所需要的数据,渲染页面等的总时间) private int runtime; //pagelet视图模板 private String pageletViewPath; private String pageletKey; /** * 创建一个pagelet 执行器.执行pagelet的业务逻辑和渲染页面.这里只是模拟. * @param runtime 进行业务处理,数据获取等的运行时间
* @param pageletKey 对应html 中div id * @param pageletViewPath 模板的视图路径 */ public PageletWorker(int runtime,String pageletKey, String pageletViewPath) { this.runtime = runtime; this.pageletKey = pageletKey; this.pageletViewPath = pageletViewPath; } public String call() throws Exception { //模仿业务逻辑的处理和相关数据获取时间 Thread.sleep(runtime); //模仿页面渲染过程 String result = Renderer.render(pageletViewPath); result = buildJsonResult(result); return result; } /** * 将结果转化为json形式 * @param result * @return */ private String buildJsonResult(String result) { StringBuilder sb = new StringBuilder(); sb.append("<script type=\"application/javascript\">") .append("\nreplace(\"") .append(pageletKey) .append("\",\'") .append(result.replaceAll("\n","")).append("\');\n</script>"); return (String) sb.toString(); } }
该类主要逻辑如下:
- Thread.sleep(runtime) 表示模仿该pagelet的业务处理,数据获取的时间
- 将获取到的数据及该pagelet的视图模板交给渲染器渲染,得到渲染后的页面内容.这里用Renderer类模仿页面的渲染过程.
- 将该页面内容封装成json形式返回
Renderer.java 是模仿获取渲染过程,这里主要是读取pagelet视图内容.具体代码如下:
public class Renderer { /** * 模范页面的渲染,这里主要是获取对应的页面信息. * @param viewPath * @return */ public static String render(String viewPath){ String absolutePath = Renderer.class.getClassLoader().getResource(viewPath).getPath(); File file = new File(absolutePath); StringBuilder contentBuilder = new StringBuilder(); BufferedReader br = null; try { br = new BufferedReader(new FileReader(file)); String str; while ((str = br.readLine()) != null) {//使用readLine方法,一次读一行 contentBuilder.append(str + "\n"); } } catch (Exception e) { // TODO: handle exception }finally{ if(br != null) try { br.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } return contentBuilder.toString(); } }
在web.xml中配置BigPipeServlet:
<servlet> <servlet-name>bigPipeServlet</servlet-name> <display-name>bigPipeServlet</display-name> <description></description> <servlet-class>org.opensjp.bigpipe.servlet.BigPipeServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>bigPipeServlet</servlet-name> <url-pattern>/bigPipeServlet</url-pattern> </servlet-mapping>
在页面输入/bigPipeServlet就可以看到效果了.先是显示页面框架内容,然后陆续的显示各个pagelet的内容.
代码下载地址:https://github.com/JohnZhengHub/BigPipe-ServletDemo
5.实现细节
如果要实现一个具有良好性能的BigPipe,需要考虑的东西还挺多.可以从一下几个方面考虑,提高BigPipe框架的性能.
1.对搜索引擎的支持.
这是一个必须考虑的问题,如今是搜索引擎的时代,如果网页对搜索引擎不友好,或者使搜索引擎很难识别内容,那么会降低网页在搜索引擎中的排名,直接 减少网站的访问次数。在BigPipe 中,页面的内容都是动态添加的,所以可能会使搜索引擎无法识别。但是正如前面所说,在服务器端首先要根据user-agent 判断客户端是否是搜索引擎的爬虫,如果是的话,则转化为原有的模式,而不是动态添加。这样就解决了对搜索引擎的不友好。
2.将资源文件进行压缩,提高传输速度.可以考虑使用G-zip对css和js文件进行压缩
3.对js文件进行精简:对js 文件进行精简,可以从代码中移除不必要的字符,注释以及空行以减小js 文件的大小,从而改善加载的页面的时间。精简js 脚本的工具可以使用JSMin,使用精简后的脚本的大小会减少20%左右。这也是一个很大的提升。
4.将样式表放在顶部
将html 内容所需的css 文件放在首部加载是非常重要的。如果放在页面尾部,虽然会使页面内容更快的加载(因为将加载css 文件的时间放在最后,从而使页面内容先显示出来),但是这样的内容是没有使用样式表的,在css 文件加载进来后,浏览器会对其使用样式表,即再次改变页面的内容和样式,称之为“无样式内容的闪烁”,这对于用户来说当然是不友好的。实现的时候将css 文件放在<head>标签中即可。
5.将js放在底部
支持页面动态内容的Js 脚本对于页面的加载并没有什么作用,把它放在顶部加载只会使页面更慢的加载,这点和前面的提到的css 文件刚好相反,所以可以将它放在页尾加载。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步