


Hadoop笔记
前言:
HADOOP的核心组成部分:HDFS文件系统和Mapreduce。在构建这个大数据分布式应用框架的过程中,解决了很多了共性问题并且都封装为开源的框架,这些框架完全可以拿来用《Hadoop API》。
Pig 是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简易的操作和编程接口。
Chukwa 是基于Hadoop的集群监控系统,由yahoo贡献。用于管理大型分布式系统的数据收集系统(2000+以上的节点, 系统每天产生的监控数据量在T级别)。
Hive 是基于Hadoop的一个工具,提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
ZooKeeper 高效的,可扩展的协调系统,存储和协调关键共享状态。
HBase 是一个开源的,基于列存储模型的分布式数据库。
HDFS 是一个分布式文件系统。有着高容错性的特点,并且设计用来部署在低廉的硬件上,适合那些有着超大数据集的应用程序。
MapReduce 是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
Hadoop RPC 远程过程调用RPC。
Hadoop YARN 任务调度和集群资源管理。
其他相关:
Avro 数据序列化系统,由Doug Cutting牵头开发,是一个数据序列化系统。
Cassandra 可扩展的多主数据库,没有单点故障。是一套开源分布式NoSQL数据库系统。
Mahout Apache旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Tez 用于构建高性能批处理和交互式数据处理应用程序的可扩展框架,由Apache Hadoop中的YARN协调。
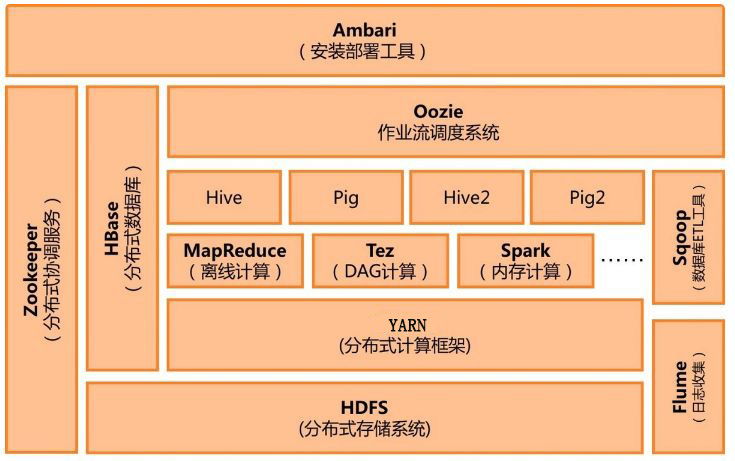
1、HDFS文件系统
1.1 HDFS有很多特点:摘自https://www.cnblogs.com/laov/p/3434917.html 源码分析
① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。多大?多小?HDFS默认会将文件分割成block,64M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。
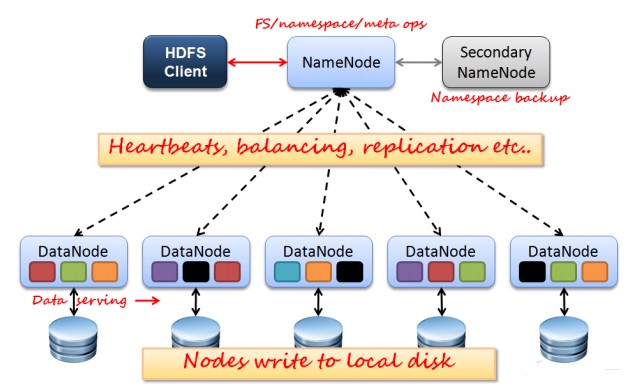
NameNode元数据管理机制(非HA模式):
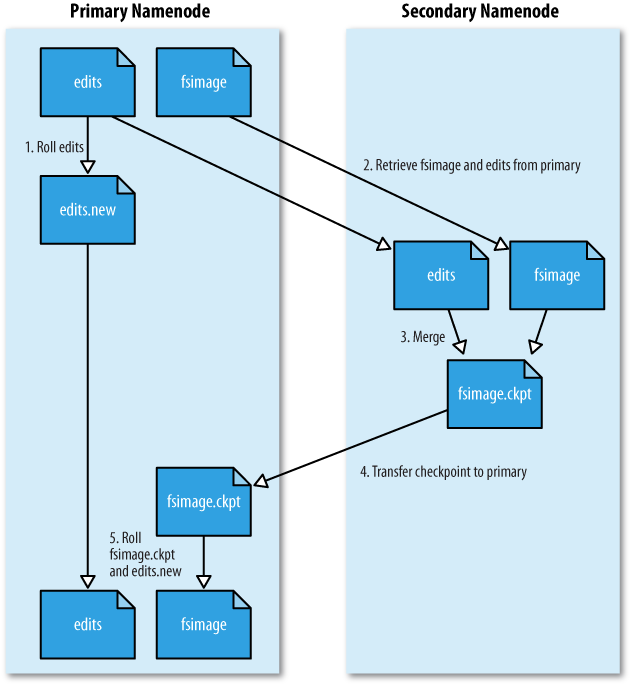


如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。 NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间; SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。 DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。 热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。 冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。 fsimage:元数据镜像文件(文件系统的目录树。) edits:元数据的操作日志(针对文件系统做的修改操作记录) namenode内存中存储的是=fsimage+edits。 SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
1.2 工作原理
写操作
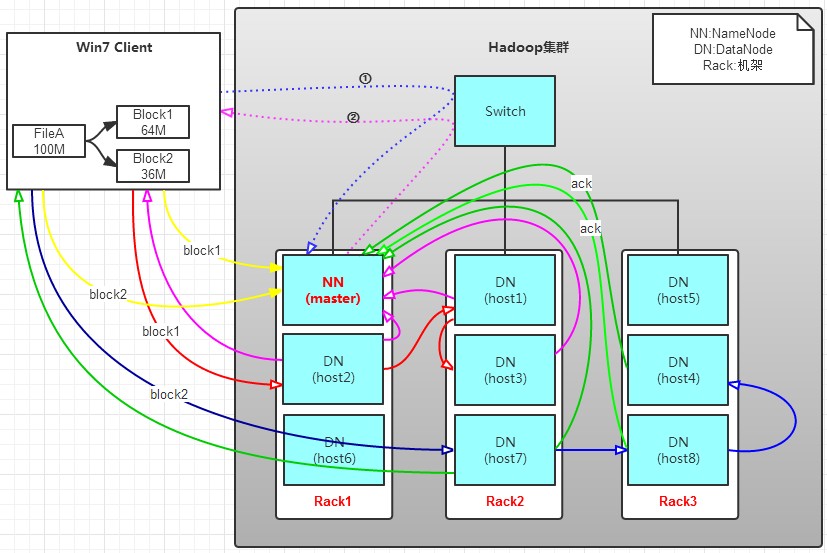
有一个文件FileA,100M大小。Client将FileA写入到HDFS上。 HDFS按默认配置。 HDFS分布在三个机架上Rack1,Rack2,Rack3。 a. Client将FileA按64M分块。分成两块,block1和Block2; b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。 c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。 Block1: host2,host1,host3 Block2: host7,host8,host4 原理: NameNode具有RackAware机架感知功能,这个可以配置。 若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。 若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。 d. client向DataNode发送block1;发送过程是以流式写入。 流式写入过程, 1>将64M的block1按64k的package划分; 2>然后将第一个package发送给host2; 3>host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package; 4>host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。 5>以此类推,如图红线实线所示,直到将block1发送完毕。 6>host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。 7>client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线 8>发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。 9>发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。 10>client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。 分析,通过写过程,我们可以了解到: ①写1T文件,我们需要3T的存储,3T的网络流量贷款。 ②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。 ③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
读操作

操作就简单一些了,如图所示,client要从datanode上,读取FileA。而FileA由block1和block2组成。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
上面例子中,client位于机架外,那么如果client位于机架内某个DataNode上,例如,client是host6。那么读取的时候,遵循的规律是:
优选读取本机架上的数据。
2、MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想。MapReduce极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。摘自:http://www.cnblogs.com/wangxin37/p/6501495.html
补充: 多个job在同一个main方法中提交:使用Shell脚本组织并执行。
2.1 单词分词实例




WCMapper.java
import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; //4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型 //map 和 reduce 的数据输入输出都是以 key-value对的形式封装的 //默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ //mapreduce框架每读一行数据就调用一次该方法 @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中 key-value //key 是这一行数据的起始偏移量 value 是这一行的文本内容 //将这一行的内容转换成string类型 String line = value.toString(); //对这一行的文本按特定分隔符切分 String[] words = StringUtils.split(line, " "); //遍历这个单词数组输出为kv形式 k:单词 v : 1 for(String word : words){ context.write(new Text(word), new LongWritable(1)); } } }
WCReducer.java
import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ //框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法 //<hello,{1,1,1,1,1,1.....}> @Override protected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException { long count = 0; //遍历value的list,进行累加求和 for(LongWritable value:values){ count += value.get(); } //输出这一个单词的统计结果 context.write(key, new LongWritable(count)); } }
WCRunner.java
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 用来描述一个特定的作业 * 比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce * 还可以指定该作业要处理的数据所在的路径 * 还可以指定改作业输出的结果放到哪个路径 * .... * @author duanhaitao@itcast.cn * */ public class WCRunner { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //设置整个job所用的那些类在哪个jar包 wcjob.setJarByClass(WCRunner.class); //本job使用的mapper和reducer的类 wcjob.setMapperClass(WCMapper.class); wcjob.setReducerClass(WCReducer.class); //指定reduce的输出数据kv类型 wcjob.setOutputKeyClass(Text.class); wcjob.setOutputValueClass(LongWritable.class); //指定mapper的输出数据kv类型 wcjob.setMapOutputKeyClass(Text.class); wcjob.setMapOutputValueClass(LongWritable.class); //指定要处理的输入数据存放路径 FileInputFormat.setInputPaths(wcjob, new Path("hdfs://weekend110:9000/wc/srcdata/")); //指定处理结果的输出数据存放路径 FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://weekend110:9000/wc/output3/")); //将job提交给集群运行 wcjob.waitForCompletion(true); } }
MR程序的几种提交运行模式:
本地模型运行 1/在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行 ----输入输出数据可以放在本地路径下(c:/wc/srcdata/) ----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata) 2/在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行 ----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/) ----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata) 集群模式运行 1/将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner 2/在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施: ----在工程src目录下加入 mapred-site.xml 和 yarn-site.xml ----将工程打成jar包(wc.jar),同时在main方法中添加一个conf的配置参数 conf.set("mapreduce.job.jar","wc.jar"); 3/在windows的eclipse中直接运行main方法,也可以提交给集群中运行,但是因为平台不兼容,需要做很多的设置修改 ----要在windows中存放一份hadoop的安装包(解压好的) ----要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件 ----再要配置系统环境变量 HADOOP_HOME 和 PATH ----修改YarnRunner这个类的源码
2.2 MapReduce执行过程
MR的分发和管理依赖YARN,MR被放在Yarn上运行,实际是放在Yarn的ApplicationMaster中,由ApplicationMaster管理,ApplicationMaster在运行起来后,先向Yarn中ResourceManager注册并所要资源,ResourceManager就通知每个节点上的小弟:NodeManager,NodeManager接到通知,立刻执行,最终给ApplicationMaster提供一个运行的环境:Container。然后在Container中MapReduce(也可以是Spark/Storm其他计算)中就开始了自己计算。
MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件(InputFormat),然后调用自己的方法,处理数据(Shuffle),最后输出(OutputFormat)。Reducer任务会接收Mapper任务输出的数据,作为自己的输入数据,调用自己的方法,最后输出到HDFS的文件中。在这个过程中,用户可以自定义Reduce的并发数,Map的并发数依赖切片Spilt数,切片数依赖每个切片的大小,可以设置。整个流程如图: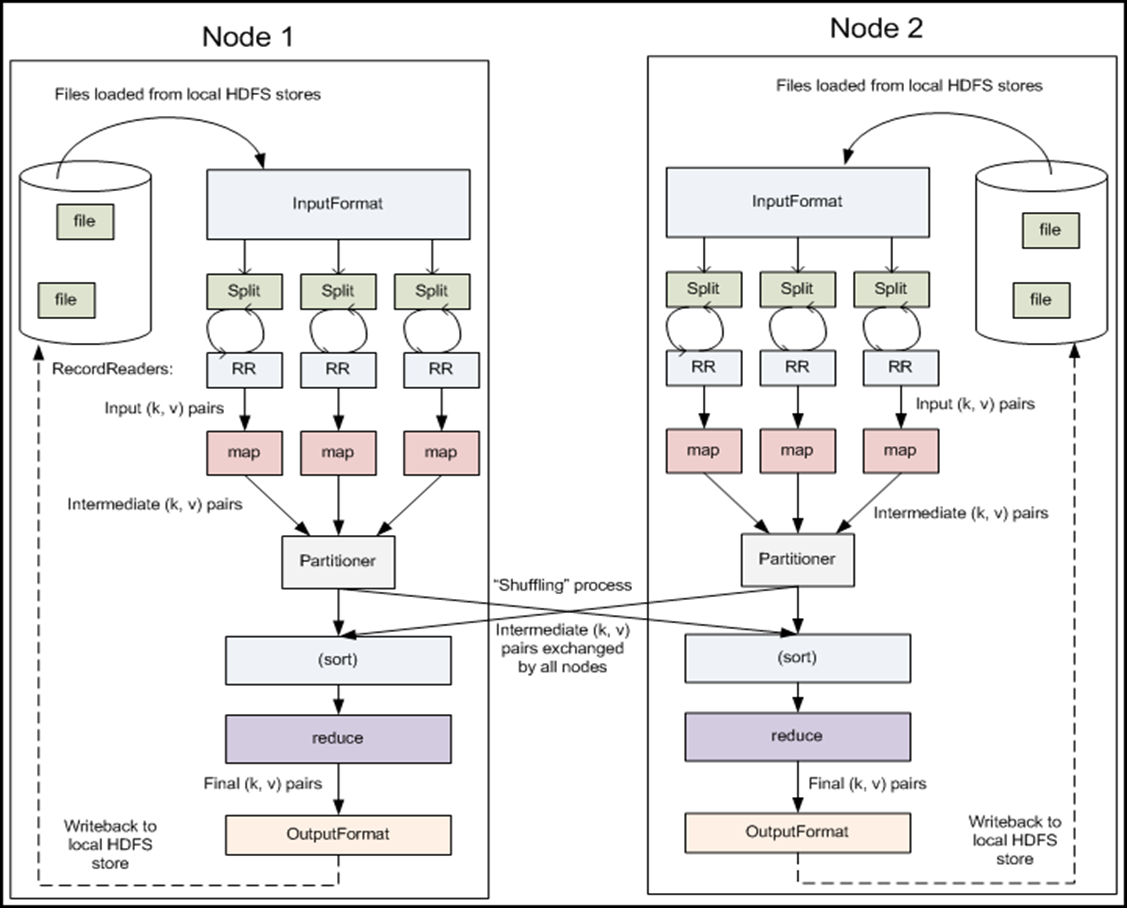

1.执行MR的命令:
hadoop jar <jar在linux的路径> <main方法所在的类的全类名> <参数> 例子:
hadoop jar /root/wc1.jar cn.itcast.d3.hadoop.mr.WordCount hdfs://itcast:9000/words /out2
2.MR执行流程
(1).客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar ...) (2).JobClient通过RPC和JobTracker进行通信,返回一个存放jar包的地址(HDFS)和jobId (3).client将jar包写入到HDFS当中(path = hdfs上的地址 + jobId) (4).开始提交任务(任务的描述信息,不是jar, 包括jobid,jar存放的位置,配置信息等等) (5).JobTracker进行初始化任务 (6).读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask (7).TaskTracker通过心跳机制领取任务(任务的描述信息) (8).下载所需的jar,配置文件等 (9).TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask) (10).将结果写入到HDFS当中
2.3 Mapper任务详解
每个Mapper任务是一个java进程,它会读取HDFS中的文件,解析成很多的键值对,经过我们覆盖的map方法处理后,转换为很多的键值对再输出。整个Mapper任务的处理过程又可以分为以下几个阶段,如图所示:
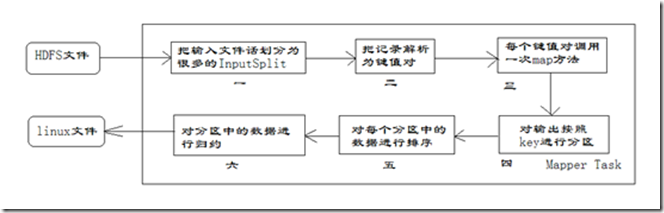
第一阶段是把输入文件按照一定的标准进行分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper进程处理。这里的三个输入片,会有三个Mapper进程处理。 第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。 第三阶段是调用Mapper类中的map方法。第二阶段中解析出来的每一个键值对,调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map方法会输出零个或者多个键值对。 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。比较是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux文件中。 第六阶段是对数据进行归约处理,也就是reduce处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
2.4 Reducer任务详解
每个Reducer任务是一个java进程。Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段:

第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中
2.5 Shuffle
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。摘自:http://blog.csdn.net/github_36444580/article/details/75208992
1、MapReduce中,Map阶段处理的数据如何传递给Reduce阶段,是MapReduce框架中最关键的一个流程,这个流程就叫Shuffle;
2、Shuffle: 洗牌、发牌(核心机制:数据分区、排序、缓存);
3、具体来说:就是将map task输出的处理结果数据,分发给reduce task,并在分发的过程中,对数据按key进行了分区和排序,分区和排序可以分别根据WritableComparable接口、Partitioner接口( 见下图:AreaPartitioner.java)实现自定义。
Shuffle是MR处理流程中的一个过程,它的每一个处理步骤是分散在各个map task和reduce task节点上完成的。
Shuffle缓存流程

Shuffle运行机制
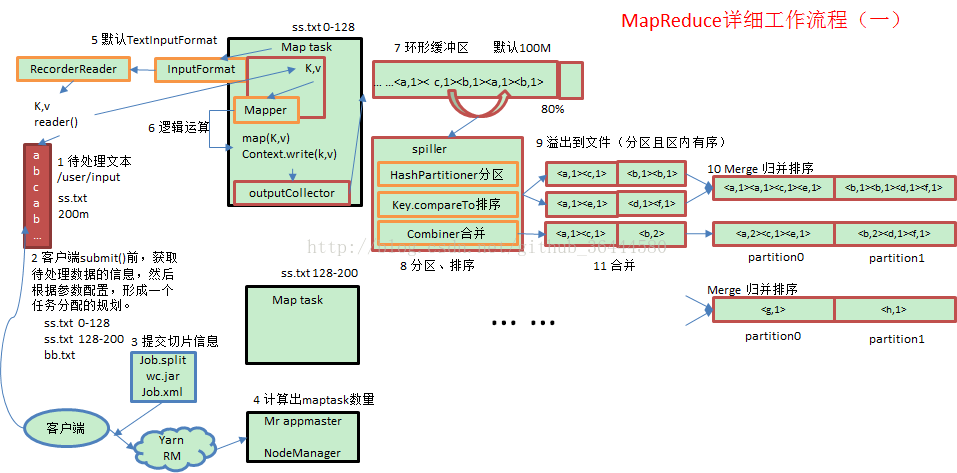
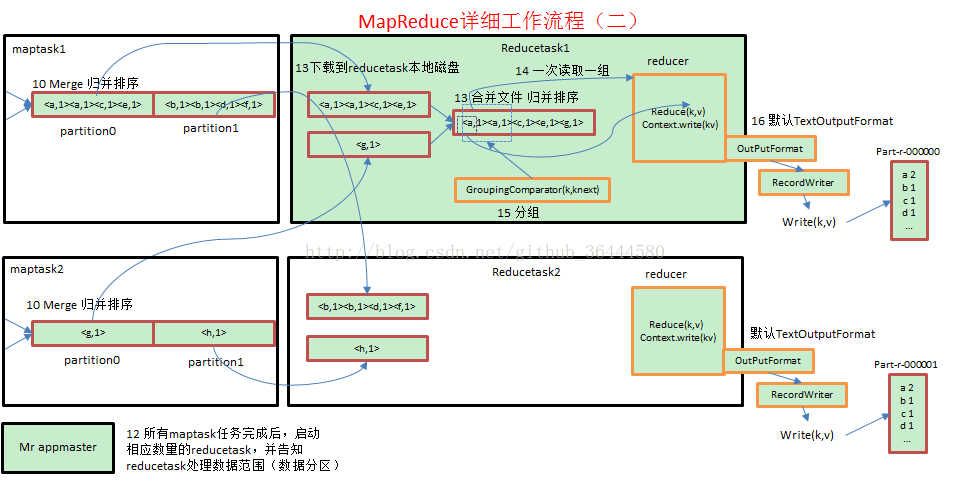
上面的流程是整个mapreduce最全工作流程,但是shuffle过程只是从第7步开始到第16步结束,具体shuffle过程详解,如下: 1)maptask收集我们的map()方法输出的kv对,放到内存缓冲区中 2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件 3)多个溢出文件会被合并成大的溢出文件 4)在溢出过程中,及合并的过程中,都要调用partitoner进行分组和针对key进行排序 5)reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据 6)reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序) 7)合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法) 注意 Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。 缓冲区的大小可以通过参数调整,参数:io.sort.mb 默认100M
Partition分区
如果reduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
如果1<reduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
如果reduceTask的数量=1,则不管mapTask端输出多少个分区文件,最终结果都交给这一个reduceTask,最终也就只会产生一个结果文件 part-r-00000;
例如:假设自定义分区数为5,则
(1)job.setNumReduceTasks(1);会正常运行,只不过会产生一个输出文件
(2)job.setNumReduceTasks(2);会报错
(3)job.setNumReduceTasks(6);大于5,程序会正常运行,会产生空文件
改变分组数(Partition):直接影响就是最终Reduce输出文件个数,Reduce的并发个数=Partintion个数。
AreaPartitioner.java
package cn.itcast.hadoop.mr.areapartition; import java.util.HashMap; import org.apache.hadoop.mapreduce.Partitioner; public class AreaPartitioner<KEY, VALUE> extends Partitioner<KEY, VALUE>{ private static HashMap<String,Integer> areaMap = new HashMap<>(); static{ areaMap.put("135", 0); areaMap.put("136", 1); areaMap.put("137", 2); areaMap.put("138", 3); areaMap.put("139", 4); } @Override public int getPartition(KEY key, VALUE value, int numPartitions) { //从key中拿到手机号,查询手机归属地字典,不同的省份返回不同的组号 int areaCoder = areaMap.get(key.toString().substring(0, 3))==null?5:areaMap.get(key.toString().substring(0, 3)); return areaCoder; } }
FlowSumArea.java
package cn.itcast.hadoop.mr.areapartition; import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.itcast.hadoop.mr.flowsum.FlowBean; /** * 对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件 * 需要自定义改造两个机制: * 1、改造分区的逻辑,自定义一个partitioner * 2、自定义reduer task的并发任务数 * * @author duanhaitao@itcast.cn * */ public class FlowSumArea { public static class FlowSumAreaMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //拿一行数据 String line = value.toString(); //切分成各个字段 String[] fields = StringUtils.split(line, "\t"); //拿到我们需要的字段 String phoneNB = fields[1]; long u_flow = Long.parseLong(fields[7]); long d_flow = Long.parseLong(fields[8]); //封装数据为kv并输出 context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow)); } } public static class FlowSumAreaReducer extends Reducer<Text, FlowBean, Text, FlowBean>{ @Override protected void reduce(Text key, Iterable<FlowBean> values,Context context) throws IOException, InterruptedException { long up_flow_counter = 0; long d_flow_counter = 0; for(FlowBean bean: values){ up_flow_counter += bean.getUp_flow(); d_flow_counter += bean.getD_flow(); } context.write(key, new FlowBean(key.toString(), up_flow_counter, d_flow_counter)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowSumArea.class); job.setMapperClass(FlowSumAreaMapper.class); job.setReducerClass(FlowSumAreaReducer.class); //设置我们自定义的分组逻辑定义 job.setPartitionerClass(AreaPartitioner.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //设置reduce的任务并发数,应该跟分组的数量保持一致 job.setNumReduceTasks(1); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1); } }
Combiner合并
1)combiner是MR程序中Mapper和Reducer之外的一种组件;
2)combiner组件的父类就是Reducer;
3)combiner和reducer的区别在于运行的位置:Combiner是在每一个maptask所在的节点运行,Reducer是接收全局所有Mapper的输出结果;
4)combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量;
6)combiner能够应用的前提是不能影响最终的业务逻辑,而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来Mapper;

