


Hive笔记
摘自:https://www.cnblogs.com/jiang-it/p/7943769.html http://blog.csdn.net/wangyang1354/article/details/50570903
Hive概述
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。Hive的替代品:impala / spark shark /spark sql
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。【可扩展】
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。【延展性】
Hive良好的容错性,节点出现问题SQL仍可完成执行。【容错性】
Hive架构和组成
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- 元数据存储:通常是存储在关系数据库如 mysql、derby中。
- 解释器、编译器、优化器、执行器。
- 用户接口主要由三个:CLI、JDBC/ODBC和WebGUI。CLI为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
- 元数据存储:Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成查询计划存储在HDFS中,随后MapReduce调用执行。
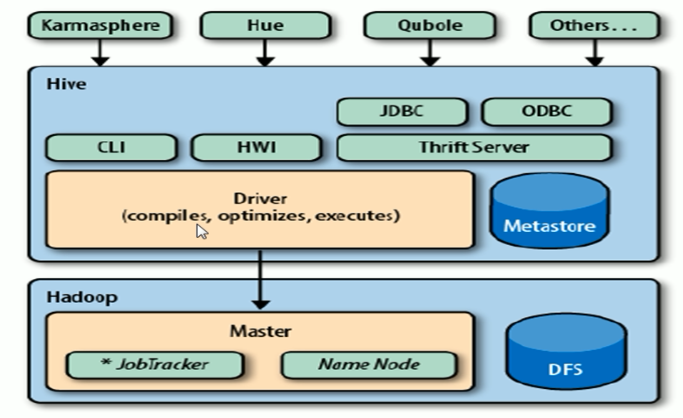
Hive流程大致步骤为:
- 用户提交查询等任务给Driver。
- 编译器获得该用户的任务Plan。
- 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
- 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce),最后选择最佳的策略。
- 将最终的计划提交给Driver。
- Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
- 获取执行的结果。
- 取得并返回执行结果。
Hive编译过程:
将HiveQL转化为抽象语法树再转为查询块然后转为逻辑查询计划再转为物理查询计划最终选择最佳决策的过程。优化器的主要功能:
- 将多Multiple join 合并为一个Muti-way join
- 对join、group-by和自定义的MapReduce操作重新进行划分。
- 消减不必要的列。
- 在表的扫描操作中推行使用断言。
- 对于已分区的表,消减不必要的分区。
- 在抽样查询中,消减不必要的桶。
- 优化器还增加了局部聚合操作用于处理大分组聚合和增加再分区操作用于处理不对称的分组聚合。
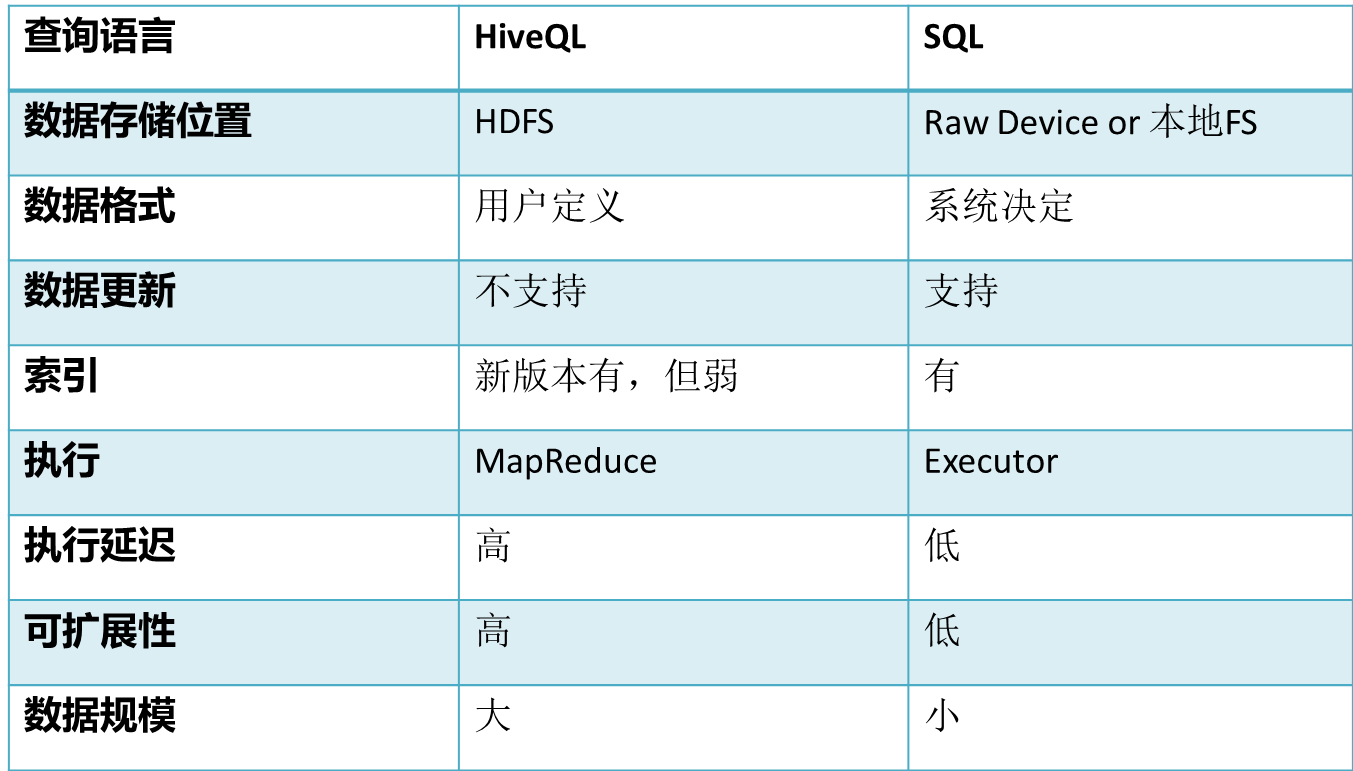
- Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)。
- 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
- Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
- db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹。
- table:在hdfs中表现所属db目录下一个文件夹。
- external table:与table类似,不过其数据存放位置可以在任意指定路径。
- partition:在hdfs中表现为table目录下的子目录。
- bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件。
Hive的安装部署:https://www.cnblogs.com/kinginme/p/7233315.html
Hive的SQL操作:http://blog.csdn.net/qq_806913882/article/details/53576356?locationNum=4&fps=1
Hive函数:https://www.iteblog.com/archives/2258.html
Hive Shell参数: https://www.cnblogs.com/skyl/p/4736129.html

