
MDX基础
第一章
看了本书的第一章,总体一个印象,废话真多。话不多说;整理书中知识点,实践出真理!
知识点:MDX语法;简单的函数介绍;
首先语法网上流传的很多,读者应该具备cube(多维数据集)的知识基础,我这里就做简单说下:MDX是支持表达式语言和查询语言的;维度!多维数据集中的维度具有一个或者多个层级的,并且每个层次级别包含一个或多个级别。(例如:Date维度的Calendar层次结构包含下面的级别-Calendar Year、Calendar Semester、Calendar Month)。成员:每个层次结构都包含一个或多个项,这些项就是成员;每个成员都对应基础维度表中的一个或多个引用值实例。怎么引用这些项呢?有不同的引用方法,原则是一致的:确保引用的成员唯一!下面会有实例说明。单元:我们知道多维数据集是一个大的立方体,其中的组成这些立方体的组成单位也是立方体,这些相连的立方体的组合就是单元。元组:唯一标识多维数据集的一个单元或一部分的MDX表达式就是元组。元组是表达式。在多维体中表现为切片。元组记着使用圆括号括起来!集:一组元组就是集,用{}括起来。注意:是一组并非是多个元组的随意组合—> 这组元组是使用类型和数量上完全相同的一组维度定义的。{ }表示空集。集的别名:

MDX的语法结构就不说了;直接学习MDX的用法;下面为实例:
前提: 建立好一个Cube;这个Drug-Cube是分析医疗机构门诊和住院的基本运营情况的测试数据。
简单的分为时间、科室、医生以及药品维度,量值为:门诊、住院的收入明细表。见下图:从MDX语法为例说起:

1、最简单的MDX查询: select from [Drug] 结果集是什么呢?这个结果集是cube中每个维度的默认值的该度量值的对应的所有单元的聚合值!

2、完整的一个MDX查询
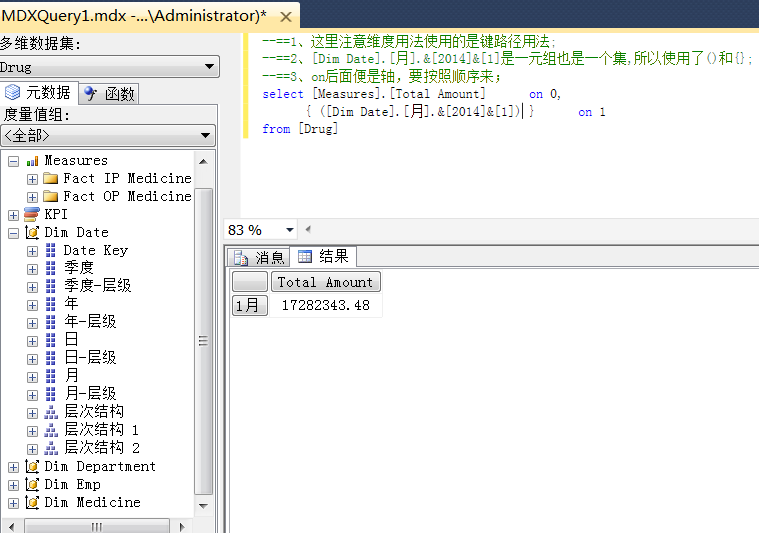
3、“:”和“,”的区别

4、Member和Children的用法:
 5、Descendants的用法:
5、Descendants的用法:

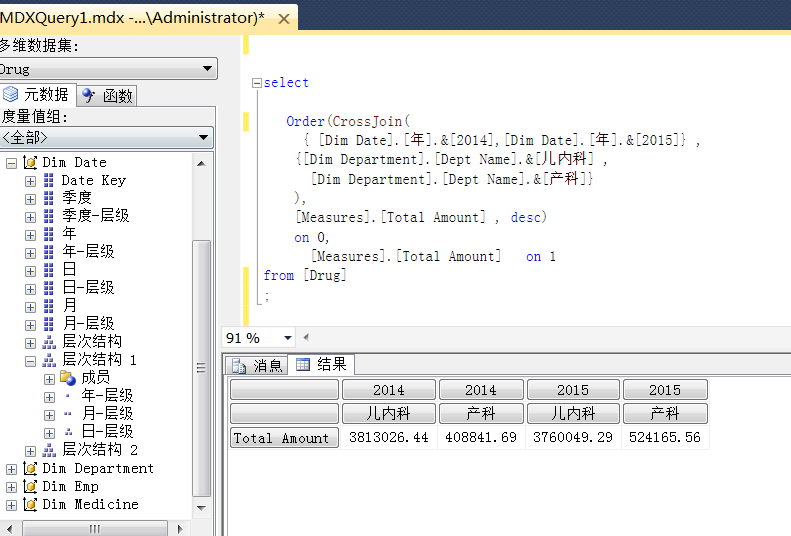
6、Order和CrossJoin的用法:
7、查询成员属性: DIMENSION PROPERTIES这个没理解,暂时先记下书中的话:固有的和数据库定义的成员属性都可以被查到,Analysis Services定义了名称为KYE、NAME、和ID的固有属性;并且每个维度的每个级别都有这些属性。成员的key属性包含维度表中描述的成员键的值。成员name的属性包含了维度表中描述的成员名称的值。id属性包含了成员在数据库维度范围内排序的内部编号。这些似乎与客户端的编程有关,与此相似的还有,查询单元的属性:cell PROPERTIES如果一个查询没有执行单元属性,默认返回3个属性:一个表示单元在结果集中索引的序数,适合任何类型的原始的单元值,以及单元的原本的格式值。如果查询指定了特殊的单元属性,那么就只有那些属性值被返回到客户端。
8、补充:HAVING字句为轴上的元组在实现 NON EMPTY 逻辑之后增加筛选提供一种方便的途径。它并没有提供什么特殊功能,而仅仅是对某些逻辑的陈述更为简单。

第二章
知识点: 计算成员和命名集
计算成员
计算成员的语法格式:MEMBER 成员标识符 AS ‘成员计算公式’;简单的计算成员就略过,接下来我们说说,当计算成员的公式出现叠加时怎么处理,这时候需要我们设置公式的优先级,以实例说明:示例中我们有两个计算成员,一个计算人均值([Measures].[avg Amount]),另一个计算时间差([Dim Date].[年].[2014-2015]),然后我们来查询一下的结果集:我们注意到最后一个值(avg 和2014-2014的交叉值)=137446.10/252927925865(即:Total Amount / Pati ID)是按照计算成员人均值([Measures].[avg Amount])来计算的。这无可厚非,但是,你有没有想到,这个值为什么不按照时间差([Dim Date].[年].[2014-2015])来计算呢?这个值处于两个计算成员的交集中,凭什么要按照人均值([Measures].[avg Amount])来计算呢?是的,因为我们设置了SOLVE_ORDER = 1级别,有了优先级,处在交集中的单元就按照优先级高的来计算。你也可以尝试将优先级更换,但是,这就不符合我们的预期了,所以设置优先级,要根据实际运算需求来设置!

另外,一个知识点,就是 CREATE MEMBER CURRENTCUBE.[Measures].[计算成员]的用法,因为我们常常在

这里新增计算成员,并且查看代码的时候是下面的格式,使用的就是CREATE来创建的计算成员,这种计算成员跟我们使用WITH的方法有什么不一样吗?当然不一样了,利用CREATE MEMBER命令定义的计算成员必须用他们所属的多维数据集和维度命名,CREATE MEMBER不是带有SELECT的查询的一部分,他本身就是一个语句。
CALCULATE;
CREATE MEMBER CURRENTCUBE.[Measures].[计算成员]
AS ([Measures].[Amount],[Dim PC Account].[Cname].&[2期投入]),
VISIBLE = 1 ;
计算成员的使用就要使用计算函数集:

命名集
命名集仅仅是一个特定的进行了命名的集。他们可以任意类型的成员或元组,只要该集有效。MDX中任何可以使用集的地方,都可以引用一个命名集。
命名集的作用域和计算成员一样。如果在一个查询的WITH部分创建一个命名集,那么在查询外它不可见;如果使用Create Set 创建一个命名集,那么它可以被多个查询使用并可以使用Drop Set命令释放。命名集的创建语句: 1: SET Set-Identifier AS 'set-formula' ; 2: CREATE DYNAMIC SET CURRENTCUBE.[命名集] AS '命名集';命名集可以在WITH部分的任何地方定义。如果一个命名集引用了一个计算成员或者另一个命名集,那么它需要出现在它引用的对象之后。反过来任意引用命名集的计算成员需要出现在集的定义之后。
第三章
知识点: mdx通用的计算和选择
博客园中已经有了一片很好的,可以参考:
http://www.cnblogs.com/microsheen/archive/2006/11/06/552237.html
http://blog.csdn.net/hero_hegang/article/details/9072889
第六章
知识点: mdx中的排序和分类
用到的函数有:Order()、Hiierarchize()、Top-Count()、BottomCount()、TopSum()、BottomSum()、TopPercent()、BottomPercent()、YTD()、CoalesceEmpty()、Rank()、ParallelPeriod()、Generate()、Ancestor()、Descendants()、.Properties()和DrillDownLevelTop()。这些函数不仅支持一维的成员集进行计算,也可以对元组集进行运算。
1.Top-Count()示例: 用法:TopCount ( set [ , numric_expression])

2.Rank()示例:


