

前言
首先在学习react的时候就对setSate的实现有比较浓厚的兴趣,那么对于下边的代码,可以快速回答吗?
class Root extends React.Component { constructor(props) { super(props); this.state = { count: 0 }; } componentDidMount() { let me = this; me.setState({ count: me.state.count + 1 }); console.log(me.state.count); // 打印 me.setState({ count: me.state.count + 1 }); console.log(me.state.count); // 打印 setTimeout(function(){ me.setState({ count: me.state.count + 1 }); console.log(me.state.count); // 打印 }, 0); setTimeout(function(){ me.setState({ count: me.state.count + 1 }); console.log(me.state.count); // 打印 }, 0); } render() { return ( <h1>{this.state.count}</h1> ) } }
这段代码大家可能在很多地方看见过,结果是让你匪夷所思的0,0,2,3。 大部分人相信都不知道其中的原因,首先肯定会问:
- 为什么前两次为零,而加上setTimeout就可以打印出来?
- 为什么setTimeout打印出不同的结果?
那么请你接下来向下看,我首先说一下Batch Updata(批量更新)。如下图:
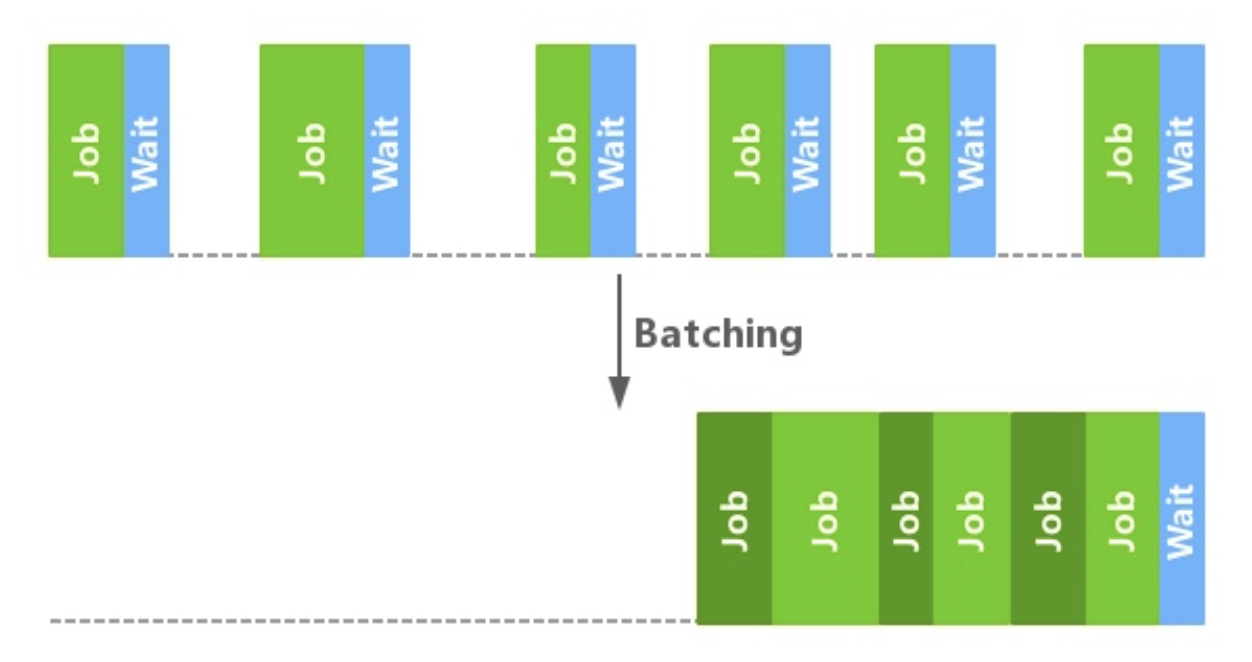
什么事Batch Update
在一些MV*框架中,就是将一段时间内对model的修改批量更新到view的机制。比如那前端比较火的React、vue为例。
在React中,我们在componentDidMount生命周期连续调用SetState:
componentDidMount () { this.setState({ foo: 1 }) this.setState({ foo: 2 }) this.setState({ foo: 3 }) }
在没有Batch Update的情况下,上面的操作会导致三次组件渲染,但是使用Batch Update机制下时间上只运行了一次渲染。componentDidMount中三次对model的操作被优化为一次view更新,
不必要的Vitual Dom计算被忽略,从而提高了框架的效率。
Batch Update的实现
我们想到的可能就是数据结构中的栈和队列,比较一下还是使用一个queue来保存update,并在合适的时机对这个queue进行flush操作。那么现在有两个问题:
- 什么时候创建这个queue
- 什么时候对这个queue进行flush
那么我们要对Reac和Vue的源码进行分析,首先React:React中的Batch Update是通过Transaction(事务)来实现的。在React源码关于Transaction的部分可以用一幅画解释:
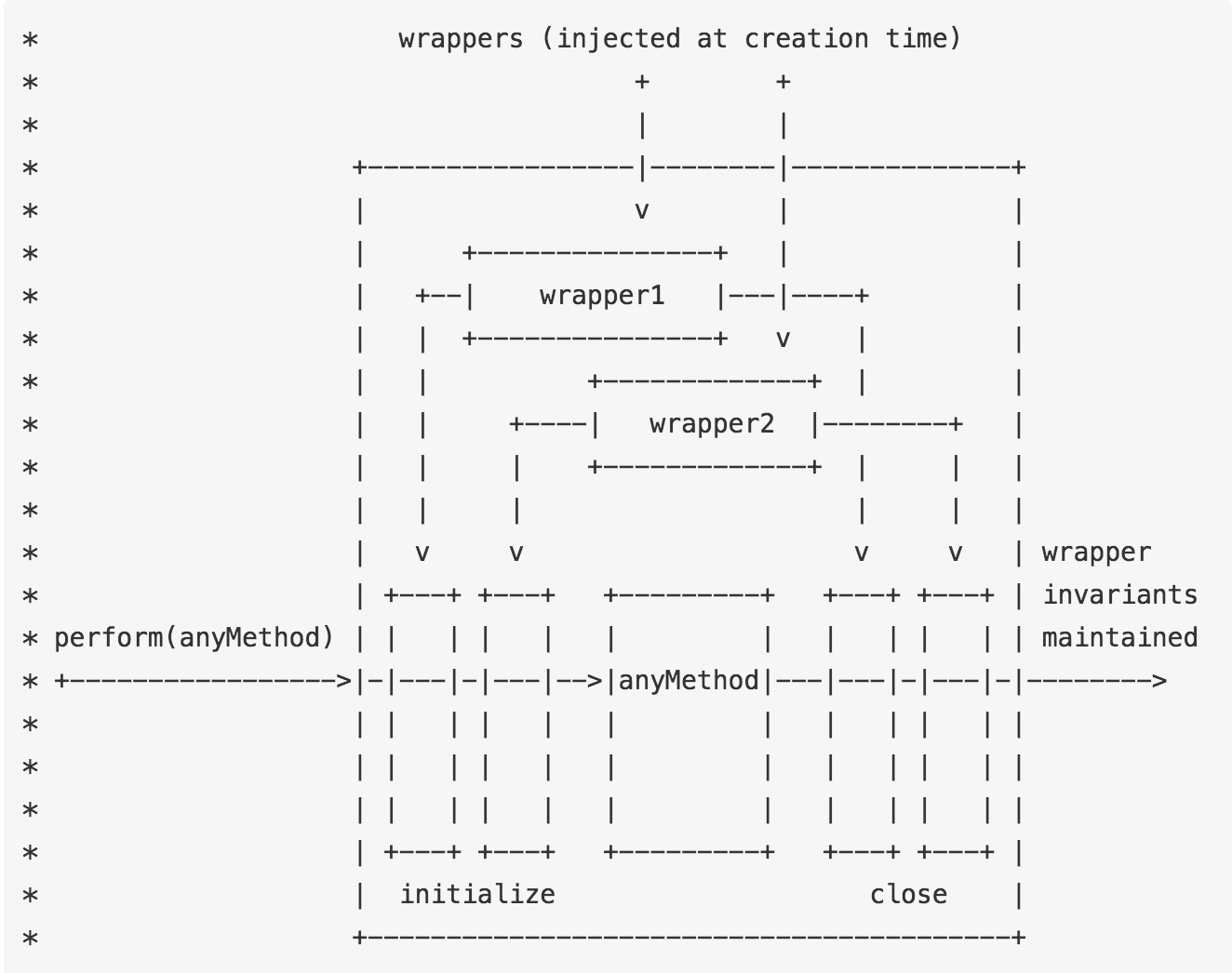
Transaction对一个函数进行包装,让React有机会在一个函数执行前和执行后运行特定的逻辑,从而完成对整个Batch Update流程的控制。
简单的说就是在要执行的函数中用事务包裹起来,在函数执行前加入initialize阶段,函数执行,最后执行close阶段。那么Batch Update中
在事件initialize阶段,一个update queue被创建。在事件中调用setState方法时,状态不会被立即调用,而是被push进Update queue中。
函数执行结束调用事件的close阶段,Update queue会被flush,这事新的状态才会被应用到组件上并开始后续的Virtual DOM更新,biff算法来对
model更新。
对比于React,Vue实现Batch update就简单多了:直接借助JS中的Event Loop。(参考阮老师的http://www.ruanyifeng.com/blog/2013/10/event_loop.html)
Vue中的核心代码就仅仅20多行,如下:
// https://github.com/vuejs/vue/blob/dev/src/core/observer/scheduler.js#L122-L148 /** * Push a watcher into the watcher queue. * Jobs with duplicate IDs will be skipped unless it's * pushed when the queue is being flushed. */ export function queueWatcher (watcher: Watcher) { const id = watcher.id if (has[id] == null) { has[id] = true if (!flushing) { queue.push(watcher) } else { // if already flushing, splice the watcher based on its id // if already past its id, it will be run next immediately. let i = queue.length - 1 while (i > index && queue[i].id > watcher.id) { i-- } queue.splice(i + 1, 0, watcher) } // queue the flush if (!waiting) { waiting = true nextTick(flushSchedulerQueue) } } }
当model被修改时,对应的watcher会被推入Update queue, 与此同时还会在异步队列中添加一个task用于flush当前的Update queue。
这样一来,当前的task中的其他watcher会被推进同一个Update queue中。当前task执行结束后,异步队列下一个task执行,update queue
会被 flush,并进行后续的更新操作。
为了让 flush 动作能在当前 Task 结束后尽可能早的开始,Vue 会优先尝试将任务 micro-task 队列,具体来说,在浏览器环境中 Vue 会优
先尝试使用 MutationObserver API 或 Promise,如果两者都不可用,则 fallback 到 setTimeout。
对比两个框架可以发现 React 基于 Transition 实现的 Batch Query 是一个不依赖语言特性的通用模式,因此有更稳定可控的表现,但缺点
是无法完全覆盖所有情况,例如对于如下代码:
componentDidMount () { setTimeout(_ => { this.setState({ foo: 1 }) this.setState({ foo: 2 }) this.setState({ foo: 3 }) }, 0) }
由于 setTimeout 的回调函数「不受 React 控制」,其中的 setState 就无法得到优化,最终会导致 render 函数执行三次。
而 Vue 的实现则对语言特性乃至运行环境有很强的依赖,但可以更好的覆盖各种情况:只要是在同一个 task 中的修改都可以进行 Batch Update 优化。
总结一下:
React 在这里的更新和事务机制使用比较通用的处理方式。
比如默认第一次应用初始化的时候是一次事务的进行,在用户交互的时候是一次新的事务开始,会在同一次同步事务中标记 batchUpdate=true,这样的做法是不破坏使用者的代码。
然后如果是 Ajax,setTimeout 等要离开主线程进行异步操作的时候会脱离当前 UI 的事务,这时候再进入此次处理的时候 batchUpdate=false,所以才会 setState 几次就 render 几次。
Vue 的策略虽然在机制上雷同,但是从根本上来讲是一种延迟的批量更新机制。
Angular 在这里也处理得很巧妙,利用 zone.js 对 task 进行拦截,对 JS 现有场景进行 AOP,这样就成功的桥接了代码。
React 的事务是纯粹的 IO 模型的适配。
那么Batch Update介绍到这里 ,在下一篇我们将参考React源码来分析setState的实现过程。

