分布式系统设计(6)
 分布式系统的实践中,广泛使用了日志技术做宕机恢复,甚至如 BigTable 等系统将日志保存到一个分布式系统中进一步增强了系统容错能力。本节介绍两种实用的日志技术 Redo Log结合checkpoint 与 No Redo/No undo Log。
分布式系统的实践中,广泛使用了日志技术做宕机恢复,甚至如 BigTable 等系统将日志保存到一个分布式系统中进一步增强了系统容错能力。本节介绍两种实用的日志技术 Redo Log结合checkpoint 与 No Redo/No undo Log。
再回忆一下我们前面介绍的几节:
第一节介绍数据分布方式:http://www.cnblogs.com/jacksu-tencent/p/3405680.html
第二节介绍副本控制协议:http://www.cnblogs.com/jacksu-tencent/p/3407712.html
第三节介绍基于Lease的分布式cache系统:http://www.cnblogs.com/jacksu-tencent/p/3409646.html
第四节介绍Lease机制本质以及判断节点状态:http://www.cnblogs.com/jacksu-tencent/p/3415529.html
第五节介绍基于quorum机制选择primary:http://www.cnblogs.com/jacksu-tencent/p/3416531.html
分布式系统的实践中,广泛使用了日志技术做宕机恢复,甚至如 BigTable 等系统将日志保存到一个分布式系统中进一步增强了系统容错能力。本节介绍两种实用的日志技术 Redo Log结合checkpoint 与 No Redo/No undo Log。
Redo Log 与 Check point
Redo Log
Redo Log 更新流程
1. 将更新操作的结果(例如 Set K1=1,则记录 K1=1)以追加写(append)的方式写入磁盘的日志文件
2. 按更新操作修改内存中的数据
3. 返回更新成功
用 Redo Log 进行宕机恢复非常简单,只需要“回放”日志即可。
Redo Log 的宕机恢复
1. 从头读取日志文件中的每次更新操作的结果,用这些结果修改内存中的数据。
从 Redo Log 的宕机恢复流程也可以看出,只有写入日志文件的更新结果才能在宕机后恢复。这也是为什么在 Redo Log 流程中需要先更新日志文件再更新内存中的数据的原因。假如先更新内存中的数据,那么用户立刻就能读到更新后的数据,一旦在完成内存修改与写入日志之间发生宕机,那么最后一次更新操作无法恢复,但之前用户可能已经读取到了更新后的数据,从而引起不一致的问题。
Check point
宕机恢复流量的缺点是需要回放所有 redo 日志,效率较低,假如需要恢复的操作非常多,那么这个宕机恢复过程将非常漫长。解决这一问题的方法即引入 check point 技术。在简化的模型下, check point 技术的过程即将内存中的数据以某种易于重新加载的数据组织方式完整的 dump 到磁盘,从而减少宕机恢复时需要回放的日志数据。
Check point更新过程
1. 向日志文件中记录“Begin Check Point”
2. 将内存中的数据以某种易于重新加载的数据组织方式 dump 到磁盘上
3. 向日志文件中记录“End Check Point”
在 check point 流程中,数据可以继续按照redo log更新流程被更新, 这段过程中新更新的数据可以 dump到磁盘也可以不 dump 到磁盘,具体取决于实现。例如,check point 开始时 k1=v1,check point 过程中某次更新为 k1 = v2,那么 dump 到磁盘上的 k1 的值可以是 v1 也可以是 v2。
基于 check point 的宕机恢复流程
1. 将 dump 到磁盘的数据加载到内存。
2. 从后向前扫描日志文件,寻找最后一个“End Check Point”日志。
3. 从最后一个“End Check Point”日志向前找到最近的一个“Begin Check Point”日志,并回放该日志之后的所有更新操作日志。
注意
上述 check point 的方式依赖 redo 日志中记录的都是更新后的数据结果这一特征,所以即使 dump的数据已经包含了某些操作的结果,重新回放这些操作的日志也不会造成数据错误。同一条日志可以重复回放的操作即所谓具有“幂等性”的操作。工程中,有些时候 Redo 日志无法具有幂等性,例如加法操作、append 操作等。此时,dump 的内存数据一定不能包括“begin check point”日志之后的操作。为此,有两种方法,其一是 check point 的过程中停更新服务,不再进行新的操作,另一种方法是,设计一种支持快照(snapshot)的内存数据结构,可以快速的将内存生成快照,然后写入check point 日志再 dump 快照数据。至于如何设计支持快照的内存数据结构,方式也很多,例如假设内存数据结构维护 key-value 值,那么可以使用哈希表的数据结构,当做快照时,新建一个哈希表接收新的更新,原哈希表用于 dump 数据,此时内存中存在两个哈希表,查询数据时查询两个哈希表并合并结果。
No Undo/No Redo log
若数据维护在磁盘中,某批更新由若干个更新操作组成,这些更新操作需要原子生效,即要么同时生效,要么都不生效。
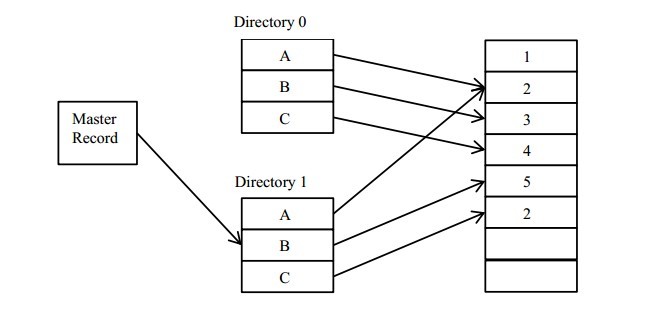
0/1 目录技术中有两个目录结构,称为目录 0(Directory 0)和目录 1(Directory 1)。另有一个结构称为主记录(Master record)记录当前正在使用的目录称为活动目录。主记录中要么记录使用目录 0,要么记录使用目录 1。目录 0 或目录 1 中记录了各个数据的在日志文件中的位置。
活动目录为目录 1,数据有 A、B、C 三项。查目录 1 可得A、B、C 三项的值分别为 2、5、2。0/1 目录的数据更新过程始终在非活动目录上进行,只是在数据生效前,将主记录中的 0、1 值反转,从而切换主记录。
0/1 目录数据更新流程
1. 将活动目录完整拷贝到非活动目录。
2. 对于每个更新操作,新建一个日志项纪录操作后的值,并在非活动目录中将相应数据的位置修改为新建的日志项的位置。
3. 原子性修改主记录:反转主记录中的值,使得非活动目录生效。
0/1 目录的更新流程非常简单,通过 0、1 目录的主记录切换使得一批修改的生效是原子的。
0/1 目录将批量事务操作的原子性通过目录手段归结到主记录的原子切换。由于多条记录的原子修改一般较难实现而单条记录的原子修改往往可以实现,从而降低了问题实现的难度。在工程中0/1 目录的思想运用非常广泛,其形式也不局限在上述流程中,可以是内存中的两个数据结构来回切换,也可以是磁盘上的两个文件目录来回生效切换。
zookeeper
在 zookeeper 系统中,为了实现高效的数据访问,数据完全保存在内存中,但更新操作的日志不断持久化到磁盘,另一方面,为了实现较快速度的宕机恢复,zookeeper周期性的将内存数据以 checkpoint 的方式 dump 到磁盘。
