************************* 一.基础部分*************************
1.1 常用数据类型
- 字符串 split/strip/replace/find/index ...
- 列表 append/extend/insert/push/pop/reverse/sort ...
- 元组 len/max/min/count/index ...
- 字典 keys/values/pop/clear/del ...
- 集合 add/remove/clear/交集&、并集 |、差集 -
- collections Python内建的一个集合模块,提供了许多有用的集合类。
1.Counter是一个简单的计数器,例如,统计字符出现的个数;
2.OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key;
3.deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈;
4.defaultdict使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict;
1.2 位和字节的关系
1.位(bit)
来自英文bit,表示二进制位。位是计算机内部数据储存的最小单位,11010100是一个8位二进制数。一个二进制位只可以表示0和1两种状态;两个二进制位可以表示00、01、10、11四种状态;三位二进制数可表示八种状态。
2.字节(byte)
字节来自英文Byte,习惯上用大写的“B”表示。
字节是计算机中数据处理的基本单位。计算机中以字节为单位存储和解释信息,规定一个字节由八个二进制位构成,即1个字节等于8个比特(1Byte=8bit)。八位二进制数最小为00000000,最大为11111111;通常1个字节可以存入一个ASCII码,2个字节可以存放一个汉字国标码。
1.3 进制转换
1) 二进制数、转换为十进制数的规律是:把二进制数按位权形式展开多项式和的形式,求其最后的和,就是其对应的十进制数——简称“按权求和”。
2) 十进制整数转换为二进制整数采用"除2取余,逆序排列"法。具体做法是:用2去除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为零时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。
10进制,当然是便于我们人类来使用,我们从小的习惯就是使用十进制,这个毋庸置疑。
2进制,是供计算机使用的,1,0代表开和关,有和无,机器只认识2进制。
16进制,内存地址空间是用16进制的数据表示, 如0x8039326。
1.4 解释型和编译型
编译型:运行前先由编译器将高级语言代码编译为对应机器的cpu汇编指令集,再由汇编器汇编为目标机器码,生成可执行文件,然最后运行生成的可执行文件。最典型的代表语言为C/C++,一般生成的可执行文件及.exe文件。
解释型:在运行时由翻译器将高级语言代码翻译成易于执行的中间代码,并由解释器(例如浏览器、虚拟机)逐一将该中间代码解释成机器码并执行(可看做是将编译、运行合二为一了)。最典型的代表语言为JavaScript、Python、Ruby和Perl等。
1.5 垃圾回收机制
Python中的垃圾回收是以引用计数为主,分代收集为辅。引用计数的缺陷是循环引用的问题。
在Python中,如果一个对象的引用数为0,Python虚拟机就会回收这个对象的内存。
http://www.cnblogs.com/Xjng/p/5128269.html
1.6 求结果
def num():
return [lambda x:i*x for i in range(4)]
print([m(2) for m in num()])
---------
[6, 6, 6, 6]
1.7 read()、readline()和readlines()区别
1) read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它范围为字符串对象
2) 从字面意思可以看出,该方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
3) readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存。
1.8 列举常用的内置函数
long(x)
float(x) # 把x转换成浮点数
complex(x) # 转换成复数
str(x) # 转换成字符串
list(x) # 转换成列表
tuple(x) # 转换成元组
进制相互转换
r= bin(10) #二进制
r= int(10) #十进制
r = oct(10) #八进制
r = hex(10) #十六进制
i= int("11",base=10)#进制间的相互转换base后跟 2/8/10/16
print(i)
chr(x)//返回x对应的字符,如chr(65)返回‘A'
ord(x)//返回字符对应的ASC码数字编号,如ord('A')返回65
abs(),all(),any(),bin(),bool(),bytes(),chr(),dict()dir(),divmod(),enumerate(),eval(),filter(),float(),gloabls(),help(),hex(),id(),input(),int(),isinstance(),len(),list(),locals(),map(),max(),min(),oct(),open(),ord(),pow(),print(),range(),round(),set(),type(),sorted(),str(),sum(),tuple()
1.9 filter、map、reduce的作用
filter:对于序列中的元素进行筛选,最终获取符合条件的序列
map:遍历序列,对序列中每个元素进行操作,最终获取新的序列
reduce:对于序列内所有元素进行累计操作
1.10 其他汇总
1) yield form
https://blog.csdn.net/chenbin520/article/details/78111399?locationNum=7&fps=1
************************* 二.函数*************************
2.1 参数是传值,还是传引用?
例一:
"""
def func(a1,a2=[]):
a2.append(a1)
print(a2)
func(1) # [1,4] [1,]
func(3,[]) # [3,] [3,]
func(4) # [1,4] [1,4]
"""
例二:
"""
def func(a1,a2=[]):
a2.append(a1)
return a2
l1 = func(1)
print(l1) # [1,]
l2 = func(3,[])
print(l2) # [3, ]
l3 = func(4)
print(l3) # [1,4]
"""
例三:
"""
def func(a1,a2=[]):
a2.append(a1)
return a2
l1 = func(1) # l1=[1,4]
l2 = func(3,[]) # l2=[3,]
l3 = func(4) # l3=[1,4]
print(l2)
print(l1)
print(l3)
"""
2.2 生成器/迭代器/可迭代对象
生成器:一个函数调用时返回一个迭代器,或函数中包含yield语法,那这个函数就会变成生成器;
应用:
-redis获取值
conn = Redis(...)
cursor = '0'
while cursor != 0:
# 去redis中获取数据:12
# cursor,下一次取的位置
# data:本地获取的12条数数据
cursor, data = self.hscan(name, cursor=cursor,
match=match, count=count)
for item in data.items():
yield item
可迭代对象:一个类内部实现__iter__方法且返回一个迭代器。
迭代器:含有__iter__和__next__方法 (包含__next__方法的可迭代对象就是迭代器)
2.3 偏函数
当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。
def add(a,b):
return a+b;
add(3,5)
add(4,7)
以上两个是我们正常调用,那么如果我们知道一个已知的参数a= 100,我们如何利用偏函数呢?
import functools import partial as pto
puls = pto(add,100)
result = puls(9)
result的结果就是109。
在这里偏函数表达的意思就是,在函数add的调用时,我们已经知道了其中的一个参数,我们可以通过这个参数,重新绑定一个函数,就是pto(add,100),然后去调用即可。
对于有很多可调用对象,并且许多调用都反复使用相同参数的情况,使用偏函数比较合适。
************************* 三.模块*************************
3.1 常用到的模块有哪些?
- re/json/logging/os/sys/requests/beautifulsoup4
3.2 正则表达式
1.匹配手机号示例
import re
def phone(arg):
s=re.match("^(13|14|15|18)[0-9]{9}$",arg)
if s:
return "正确"
return "错误"
print(phone("13722751552"))
2、match和search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
re.search匹配整个字符串,直到找到一个匹配。
3.常用正则匹配
中 文:[\u4e00-\u9fa5]
手机号:0?(13|14|15|17|18|19)[0-9]{9}
邮 箱:\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}
身份证:\d{17}[\d|x]|\d{15}
4.贪婪和非贪婪
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
http://tool.chinaz.com/regex/
3.3 根据路径找文件
import os
path = "C:\Pycharm"
print(os.listdir(path))
# 方法一:(不使用os.walk)
def print_directory_contents(sPath):
import os
for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath, sChild)
if os.path.isdir(sChildPath):
print_directory_contents(sChildPath)
else:
print(sChildPath)
# 方法二:(使用os.walk)
def print_directory_contents(sPath):
import os
for root, _, filenames in os.walk(sPath):
for filename in filenames:
print(os.path.abspath(os.path.join(root, filename)))
print_directory_contents('已知路径')
sPath-- 是你所要便利的目录的地址, 返回的是一个三元组(root,dirs,files)。
root 所指的是当前正在遍历的这个文件夹的本身的地址
_ 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
filenames 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
3.4 创建删除文件
创建目录
os.mkdir("file")
复制文件
shutil.copyfile("oldfile","newfile") oldfile和newfile都只能是文件
shutil.copy("oldfile","newfile") oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
复制文件夹
shutil.copytree("olddir","newdir") olddir和newdir都只能是目录,且newdir必须不存在
重命名文件(目录)
os.rename("oldname","newname") 文件或目录都是使用这条命令
移动文件(目录)
shutil.move("oldpos","newpos")
删除文件
os.remove("file")
删除目录
os.rmdir("dir")只能删除空目录
shutil.rmtree("dir") 空目录、有内容的目录都可以删
转换目录
os.chdir("path") 换路径
ps: 文件操作时,常常配合正则表达式:
img_dir = img_dir.replace('\\','/')
3.5 模块安装方式
- pip包管理器
- 源码安装
- 下载->解压->cd 到对应路径
- python setup.py build
- python setup.py install
************************* 四.面向对象*************************
4.1 super原理

************************* 五.网络编程*************************
5.1 OSI 7层协议
应/表/会/传/网/数/物
http://www.cnblogs.com/smile233/p/8507791.html
5.2 三次握手、四次挥手
http://www.cnblogs.com/liuxiaoming/archive/2013/04/27/3047803.html
5.3 TCP和UDP
http://www.cnblogs.com/gaopeng527/p/5255827.html
************************* 六.并发编程*************************
6.1 进程、线程、协程区别
进程:正在执行的一个程序或者一个任务,而执行任务的是cpu每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,相比线程数据相对比较稳定安全。
线程:线程是进程的一个实体,是CPU调度和分派的基本单位线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程:是单线程下的并发,或协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
优点:
1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点:
1、io阻塞
2、无法利用多核
1、进程多与线程比较
1) 地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,而进程有自己独立的地址空间
2) 资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
3) 线程是处理器调度的基本单位,但进程不是
4) 二者均可并发执行
5) 每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
2、协程多与线程进行比较
1)一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU
2) 线程进程都是同步机制,而协程则是异步
3) 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
区别:http://www.cnblogs.com/lxmhhy/p/6041001.html
总结:http://www.cnblogs.com/suoning/p/5599030.html
https://blog.csdn.net/Blateyang/article/details/78088851
6.2 GIL锁
https://blog.csdn.net/bitcarmanlee/article/details/51577014
6.3 进程池线程池
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
http://www.cnblogs.com/haiyan123/p/7461294.html
http://www.cnblogs.com/wanghzh/p/5607067.html
************************* 七.数据库*************************
7.1 引擎
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
- innodb
- 事务
- 行锁/表锁
- 表锁:
select * from tb for update;
- 行锁:
select id,name from tb where id=2 for update ;
- myisam
- 全文索引
- 快
- 表锁
7.2 数据库查表练习
习题:http://www.cnblogs.com/xuyaping/p/7106348.html
基础:http://www.cnblogs.com/xuyaping/p/6945871.html
http://www.cnblogs.com/xuyaping/p/6953288.html
7.3 索引相关
1.索引: B+/哈希索引 =》 查找速度快;更新速度慢
单列:
- 普通索引:加速查找
- 唯一索引: 加速查找 + 约束:不能重复
- 主键: 加速查找 + 约束:不能重复 + 不能为空
多列:
- 联合索引
- 联合唯一索引
PS:遵循最左前缀的规则
其他词语:
- 索引合并,利用多个单例索引查询;
- 覆盖索引,在索引表中就能将想要的数据查询到;
2.创建了索引,应该如何命中索引? 那种情况下,创建了无法命中索引?
- like '%xx'
select * from tb1 where name like '%cn';
- 使用函数
select * from tb1 where reverse(name) = 'wupeiqi';
- or
select * from tb1 where nid = 1 or email = 'seven@live.com';
特别的:当or条件中有未建立索引的列才失效,以下会走索引
select * from tb1 where nid = 1 or name = 'seven';
select * from tb1 where nid = 1 or email = 'seven@live.com' and name = 'alex'
- 类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然...
select * from tb1 where name = 999;
- !=
select * from tb1 where name != 'alex'
特别的:如果是主键,则还是会走索引
select * from tb1 where nid != 123
- >
select * from tb1 where name > 'alex'
特别的:如果是主键或索引是整数类型,则还是会走索引
select * from tb1 where nid > 123
select * from tb1 where num > 123
- order by
select email from tb1 order by name desc;
当根据索引排序时候,选择的映射如果不是索引,则不走索引
特别的:如果对主键排序,则还是走索引:
select * from tb1 order by nid desc;
3.组合索引最左前缀
如果组合索引为:(name,email)
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
7.4 慢日志等
- 如何开启慢日志查询?
slow_query_log = ON 是否开启慢日志记录
long_query_time = 2 时间限制,超过此时间,则记录
slow_query_log_file = /usr/slow.log 日志文件
log_queries_not_using_indexes = ON 为使用索引的搜索是否记录
- 执行计划
explain select * from tb;
- 导出现有数据库数据:
mysqldump -u用户名 -p密码 数据库名称 >导出文件路径 # 结构+数据
mysqldump -u用户名 -p密码 -d 数据库名称 >导出文件路径 # 结构
- 导入现有数据库数据:
mysqldump -uroot -p密码 数据库名称 < 文件路径
7.5 数据库最大历史页数查询解决方案
问:查询页数越大效率越低,如何优化?
select * form tb limit 10 offset 0
select * form tb limit 10 offset 10
select * form tb limit 10 offset 20
select * form tb limit 10 offset 30
...
select * form tb limit 10 offset 3000000
答案一:
先查主键,在分页。
select * from tb where id in (
select id from tb where limit 10 offset 30
)
答案二:
按照也无需求是否可以设置只让用户看200页
答案三:
记录当前页 数据ID最大值和最小值
在翻页时,根据条件先进行筛选;筛选完毕之后,再根据limit offset 查询。
select * from (select * from tb where id > 22222222) as B limit 10 offset 0
如果用户自己修改页码,也可能导致慢;此时对url种的页码进行加密(rest framework )
************************* redis *************************
7.6 redis 连接和基本操作
- 连接
- 直接连接:
import redis
r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print r.get('foo')
- 连接池:
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
- 5大数据类型
- 字符串 "abc"
- set('k1','123',ex=10)
- get
- mset
- mget
- incr
- 超时时间:
import redis
r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar',ex=10)
- 字典 {'k1':'v1'}
- hset(name, key, value)
- hmset(name, mapping)
- hget(name,key)
- 超时时间(字典,列表、集合、有序结合相同):
import redis
conn = redis.Redis(host='10.211.55.4', port=6379)
conn.hset('n1', 'k1','123123')
conn.expire('n1',10)
- 如果一个字典在redis中保存了10w个值,我需要将所有值全部循环并显示,请问如何实现?
for item in r.hscan_iter('k2',count=100):
print item
- 列表 [11,22,33]
- lpush
- rpush
- lpop
- blpop
- rpop
- brpop
- llen
- lrange
- 如果一个列表在redis中保存了10w个值,我需要将所有值全部循环并显示,请问如何实现?
def list_scan_iter(name,count=3):
start = 0
while True:
result = conn.lrange(name, start, start+count-1)
start += count
if not result:
break
for item in result:
yield item
for val in list_scan_iter('num_list'):
print(val)
- 集合 {'fry','bender','leela'}
- 有序集合 {('fry',59),('bender',100),('leela',1)}
- 公共操作:
- delete(*names) # 根据name删除redis中的任意数据类型
- keys(pattern='*') # 根据* ?等通配符匹配获取redis的name
- expire(name ,time) # 设置超时时间
...
http://www.cnblogs.com/melonjiang/p/5342383.html
http://www.cnblogs.com/melonjiang/p/5342505.html
7.7 redis 事务
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
conn = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = conn.pipeline(transaction=True)
# 开始事务
pipe.multi()
pipe.set('name', 'bendere')
pipe.set('role', 'sb')
# 提交
pipe.execute()
注意:咨询是否当前分布式redis是否支持事务
7.8 redis WATCH命令
在Redis的事务中,WATCH命令可用于提供CAS(check-and-set)功能。假设我们通过WATCH命令在事务执行之前监控了多个Keys,倘若在WATCH之后有任何Key的值发生了变化,EXEC命令执行的事务都将被放弃,同时返回Null multi-bulk应答以通知调用者事务执行失败。
面试题:你如何控制剩余的数量不会出问题?
- 通过redis的watch实现
import redis
conn = redis.Redis(host='127.0.0.1',port=6379)
# conn.set('count',1000)
val = conn.get('count')
print(val)
with conn.pipeline(transaction=True) as pipe:
# 先监视,自己的值没有被修改过
conn.watch('count')
# 事务开始
pipe.multi()
old_count = conn.get('count')
count = int(old_count)
print('现在剩余的商品有:%s',count)
input("问媳妇让不让买?")
pipe.set('count', count - 1)
# 执行,把所有命令一次性推送过去
pipe.execute()
- 数据库的锁
7.9 redis 发布和订阅
发布者:
import redis
conn = redis.Redis(host='127.0.0.1',port=6379)
conn.publish('104.9MH', "hahaha")
订阅者:
import redis
conn = redis.Redis(host='127.0.0.1',port=6379)
pub = conn.pubsub()
pub.subscribe('104.9MH')
while True:
msg= pub.parse_response()
print(msg)
7.10 redis 应用场景?
- 计数器
- 排行榜
- 热门商品
- 购物车信息
- rest api中访问频率控制
- 基于flask、websocket实现的投票系统(redis做消息队列)
- 配合django做缓存,常用且不易修改的数据放进来(博客)
- Session
- 缓存配置文件
- session配置文件中指定使用缓存
- scrapy中
- 去重规则
- 调度器:先进先出、后进先出、优先级队列
- pipelines
- 起始URL
7.11 redis 主从复制的作用?
目的是对redis做高可用,为每一个redis实例创建一个备份称为slave,让主和备之间进行数据同步,save/bsave。
主:写
从:读
优点:
- 性能提高,从分担读的压力。
- 高可用,一旦主redis挂了,从可以直接代替。
存在问题:当主挂了之后,需要人为手工将从变成主。
注意:
- slave设置只读
从的配置文件添加以下记录,即可:
slaveof 1.1.1.1 3306
7.12 redis的sentinel是什么?
帮助我们自动在主从之间进行切换
检测主从中 主是否挂掉,且超过一半的sentinel检测到挂了之后才进行进行切换。
如果主修复好了,再次启动时候,会变成从。
启动主redis:
redis-server /etc/redis-6379.conf 启动主redis
redis-server /etc/redis-6380.conf 启动从redis
在linux中:
找到 /etc/redis-sentinel-8001.conf 配置文件,在内部:
- 哨兵的端口 port = 8001
- 主redis的IP,哨兵个数的一半/1
找到 /etc/redis-sentinel-8002.conf 配置文件,在内部:
- 哨兵的端口 port = 8002
- 主redis的IP, 1
启动两个哨兵
7.13 redis的cluster是什么?
redis集群、分片、分布式redis
redis-py-cluster
集群方案:
- redis cluster 官方提供的集群方案。
- codis,豌豆荚技术团队。
- tweproxy,Twiter技术团队。
redis cluster的原理?
- 基于分片来完成。
- redis将所有能放置数据的地方创建了 16384 个哈希槽。
- 如果设置集群的话,就可以为每个实例分配哈希槽:
- 192.168.1.20【0-5000】
- 192.168.1.21【5001-10000】
- 192.168.1.22【10001-16384】
- 以后想要在redis中写值时,
set k1 123
将k1通过crc16的算法,将k1转换成一个数字。然后再将该数字和16384求余,如果得到的余数 3000,那么就将该值写入到 192.168.1.20 实例中。
7.14 redis是否可以做持久化?
RDB:每隔一段时间对redis进行一次持久化。
- 缺点:数据不完整
- 优点:速度快
AOF:把所有命令保存起来,如果想到重新生成到redis,那么就要把命令重新执行一次。
- 缺点:速度慢,文件比较大
- 优点:数据完整
7.15 redis的过期策略(数据淘汰策略)
voltile-lru: 从已设置过期时间的数据集(server.db[i].expires)中挑选最近频率最少数据淘汰
volatile-ttl: 从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru: 从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random: 从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
7.16 redis的分布式锁实现
- 写值并设置超时时间
- 超过一半的redis实例设置成功,就表示加锁完成。
- 使用:安装redlock-py
from redlock import Redlock
dlm = Redlock(
[
{"host": "localhost", "port": 6379, "db": 0},
{"host": "localhost", "port": 6379, "db": 0},
{"host": "localhost", "port": 6379, "db": 0},
]
)
# 加锁,acquire
my_lock = dlm.lock("my_resource_name",10000)
if my_lock:
# J进行操作
# 解锁,release
dlm.unlock(my_lock)
else:
print('获取锁失败')
http://www.redis.cn/
7.17 redis 如何提高并发
目前你们公司项目1000用户,QPS=1000 ,如果用户猛增10000w?
项目如何提高的并发?
1. 数据库读写分离
2. 设置缓存
3. 负载均衡
7.18 其他汇总
redis常见面试题
http://www.cnblogs.com/Survivalist/p/8119891.html
http://www.cnblogs.com/wupeiqi/articles/5132791.html
************************* 八.前端*************************
8.1 响应式布局
@media (min-width: 768px){
.pg-header{
background-color: green;
}
}
@media (min-width: 992px){
.pg-header{
background-color: pink;
}
}
8.2 跨域实现(JSONP&CORS)
AJAX即“Asynchronous Javascript And XML”(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术
AJAX可以在不重新加载整个页面的情况下,与服务器交换数据
Ajax的核心是XMLHttpRequest对象(XHR)。XHR为向服务器发送请求和解析服务器响应提供了接口。能够以异步方式从服务器获取新数据。
1.JSONP
JSONP是一个非官方的协议,它允许在服务器端集成Script tags返回至客户端,通过javascript callback的形式实现跨域访问。jsonp只能通过get方式进行跨域请求
2.CORS
http://www.cnblogs.com/aylin/p/5732242.html
************************* 九.Django*************************
9.1 你了解哪些web框架及其区别
django:大而全的全的框架,重武器;内置很多组件:ORM、admin、Form、ModelForm、中间件、信号、缓存、csrf等
flask: 微型框架、可扩展强,如果开发简单程序使用flask比较快速,如果实现负责功能就需要引入一些组件:flask-session/flask-SQLAlchemy/wtforms/flask-migrate/flask-script/blinker
这两个框架都是基于wsgi协议实现的,默认使用的wsgi模块不一样。
还有一个显著的特点,他们处理请求的方式不同:
django: 通过将请求封装成Request对象,再通过参数进行传递。
flask:通过上下文管理实现。
9.2 Django请求的生命周期
a. wsgi, 创建socket服务端,用于接收用户请求并对请求进行初次封装。
b. 中间件,对所有请求到来之前,响应之前定制一些操作。
c. 路由匹配,在url和视图函数对应关系中,根据当前请求url找到相应的函数。
d. 执行视图函数,业务处理【通过ORM去数据库中获取数据,再去拿到模板,然后将数据和模板进行渲染】
e. 再经过所有中间件。
f. 通过wsgi将响应返回给用户。
9.3 什么是WSGI?
WSGI : Web Server Gateway Interface web 服务器网关接口
是web服务网关接口,是一套协议。以下模块实现了wsgi协议:
- wsgiref
- werkzurg
- uwsgi
本质上就是编写了socket服务端,用来监听用户请求,如果有请求到来,则将请求进行一次封装,然后将【请求】交给 web框架来进行下一步处理。
from wsgiref.simple_server import make_server
def run_server(environ, start_response):
"""
environ: 封装了请求相关的数据
start_response:用于设置响应头相关数据
"""
start_response('200 OK', [('Content-Type', 'text/html')])
return [bytes('<h1>Hello, web!</h1>', encoding='utf-8'), ]
if __name__ == '__main__':
httpd = make_server('', 8000, run_server)
httpd.serve_forever()
9.4 中间件
中间件的作用?对所有的请求进行批量处理,在视图函数执行前后进行自定义操作。
中间件的应用?cors跨域/用户登录校验/权限处理/CSRF/session/缓存
中间件中方法?5个方法,分别是:
process_request(self,request)
process_view(self, request, callback, callback_args, callback_kwargs)
process_template_response(self,request,response)
process_exception(self, request, exception)
process_response(self, request, response)
1 请求先执行所有中间件的process_request,然后做路由匹配,找到函数不执行。
2 再执行所有的process_view,在执行视图函数。
3 再执行process_response
4 如果程序报错执行process_exception
5 如果程序有render方法则执行process_template_response
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
9.5 路由视图
urlpatterns = [url(正则表达式, views视图函数,参数,别名),]
9.6 视图
1 fbv方式请求的过程
用户发送url请求,Django会依次遍历路由映射表中的所有记录,一旦路由映射表其中的一条匹配成功了,
就执行视图函数中对应的函数名,这是fbv的执行流程
2 cbv方式请求的过程
当服务端使用cbv模式的时候,用户发给服务端的请求包含url和method,这两个信息都是字符串类型
服务端通过路由映射表匹配成功后会自动去找dispatch方法,然后Django会通过dispatch反射的方式找到类中对应的方法并执行
类中的方法执行完毕之后,会把客户端想要的数据返回给dispatch方法,由dispatch方法把数据返回经客户端
把上面的例子中的视图函数修改成如下:
from django.views import View
class CBV(View):
def dispatch(self, request, *args, **kwargs):
print("dispatch......")
res=super(CBV,self).dispatch(request,*args,**kwargs)
return res
def get(self,request):
return render(request, "cbv.html")
def post(self,request):
return HttpResponse("cbv.get")
3 FBV和CBV的区别?
- 没什么区别,因为他们的本质都是函数。CBV的.as_view()返回的view函数,view函数中调用类的dispatch方法,在dispatch方法中通过反射执行get/post/delete/put等方法。
- CBV比较简洁,GET/POST等业务功能分别放在不同get/post函数中。FBV自己做判断进行区分。
http://www.cnblogs.com/renpingsheng/p/7534897.html
9.7 csrf原理
目标:防止用户直接向服务端发起POST请求。
方案:先发送GET请求时,将token保存到:cookie、Form表单中(隐藏的input标签),以后再发送请求时只要携带过来即可。
问题:如果想后台发送POST请求?
1).form表单提交:
<form method="POST">
{% csrf_token %}
<input type='text' name='user' />
<input type='submit' />
</form>
2).ajax提交:
$.ajax({
url:'/index',
type:'POST',
data:{csrfmiddlewaretoken:'{{ csrf_token }}',name:'alex'}
})
前提:引入jquery + 引入jquery.cookie
$.ajax({
url: 'xx',
type:'POST',
data:{name:'oldboyedu'},
headers:{
X-CSRFToken: $.cookie('csrftoken')
},
dataType:'json', // arg = JSON.parse('{"k1":123}')
success:function(arg){
}
})
优化方案:
<body>
<input type="button" onclick="Do1();" value="Do it"/>
<input type="button" onclick="Do2();" value="Do it"/>
<script src="/static/jquery-3.3.1.min.js"></script>
<script src="/static/jquery.cookie.js"></script>
<script>
$.ajaxSetup({
beforeSend: function(xhr, settings) {
xhr.setRequestHeader("X-CSRFToken", $.cookie('csrftoken'));
}
});
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
});
}
function Do2(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
});
}
</script>
</body>
3).爬虫:
reqeusts.post()
9.8 如何动态获取数据库字段
方式一:重写构造方法,在构造方法中重新去数据库获取值
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = fields.ChoiceField(
# choices=[(1,'二B用户'),(2,'山炮用户')]
choices=[]
)
def __init__(self,*args,**kwargs):
super(UserForm,self).__init__(*args,**kwargs)
self.fields['ut_id'].choices = models.UserType.objects.all().values_list('id','title')
方式二: ModelChoiceField字段
from django.forms import Form
from django.forms import fields
from django.forms.models import ModelChoiceField
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = ModelChoiceField(queryset=models.UserType.objects.all())
依赖:
class UserType(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
9.9 CBV装饰器注意事项
- 装饰器
from django.views import View
from django.utils.decorators import method_decorator
def auth(func):
def inner(*args,**kwargs):
return func(*args,**kwargs)
return inner
class UserView(View):
@method_decorator(auth)
def get(self,request,*args,**kwargs):
return HttpResponse('...')
- csrf的装饰器要加到dispath
from django.views import View
from django.utils.decorators import method_decorator
from django.views.decorators.csrf import csrf_exempt,csrf_protect
class UserView(View):
@method_decorator(csrf_exempt)
def dispatch(self, request, *args, **kwargs):
return HttpResponse('...')
或
from django.views import View
from django.utils.decorators import method_decorator
from django.views.decorators.csrf import csrf_exempt,csrf_protect
@method_decorator(csrf_exempt,name='dispatch')
class UserView(View):
def dispatch(self, request, *args, **kwargs):
return HttpResponse('...')
- 对用户请求的数据进行校验
- 生成HTML标签
PS:
- form对象是一个可迭代对象。
9.11 如何在一个项目中使用多数据库
python manage.py makemigraions
python manage.py migrate app名称 --databse=配置文件数据名称的别名
手动操作:
models.UserType.objects.using('db1').create(title='普通用户')
result = models.UserType.objects.all().using('default')
自动操作:
根目录下db_router.py :
class Router1:
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
return 'db1'
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
return 'default'
配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db1': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db1.sqlite3'),
},
}
DATABASE_ROUTERS = ['db_router.Router1',]
使用:
models.UserType.objects.create(title='VVIP')
result = models.UserType.objects.all()
print(result)
补充:粒度更细
class Router1:
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.model_name == 'usertype':
return 'db1'
else:
return 'default'
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
return 'default'
9.12 如何在不同app中使用不同数据库
# 第一步:
python manage.py makemigraions
# 第二步:
app01中的表在default数据库创建
python manage.py migrate app01 --database=default
# 第三步:
app02中的表在db1数据库创建
python manage.py migrate app02 --database=db1
# 手动操作:
m1.UserType.objects.using('default').create(title='VVIP')
m2.Users.objects.using('db1').create(name='VVIP',email='xxx')
# 自动操作:
配置:
class Router1:
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.app_label == 'app01':
return 'default'
else:
return 'db1'
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
if model._meta.app_label == 'app01':
return 'default'
else:
return 'db1'
DATABASE_ROUTERS = ['db_router.Router1',]
使用:
m1.UserType.objects.using('default').create(title='VVIP')
m2.Users.objects.using('db1').create(name='VVIP',email='xxx')
9.13 如何在数据库迁移时进行读写约束
class Router1:
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
All non-auth models end up in this pool.
"""
if db=='db1' and app_label == 'app02':
return True
elif db == 'default' and app_label == 'app01':
return True
else:
return False
# 如果返回None,那么表示交给后续的router,如果后续没有router,则相当于返回True
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.app_label == 'app01':
return 'default'
else:
return 'db1'
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
if model._meta.app_label == 'app01':
return 'default'
else:
return 'db1'
9.14 轮询和长轮询
- 什么是轮询?
- 通过定时器让程序每隔n秒执行一次操作。
- 什么是长轮询?
- 浏览器向后端发起请求,后端会将请求 hang 住,最多hang 30s。
如果一直不返回数据:则最多等待30s,紧接着用户立即再发送请求。
如果有数据返回:则操作数据并立即再发送请求。
PS:后台可以使用队列或redis的列表来hang主请求。
- 轮询和长轮询目的?
由于Http请求是无状态、短连接所以服务端无法向客户端实时推送消息,
所以,我们就是可以使用:轮询和长轮询去服务端获取实时数据。
a. 实时消息推送,利用什么技术实现?
- 轮询 ,优点:简单; 缺点:请求次数多,服务器压力大,消息延迟。
- 长轮询 ,优点:实时接收数据,兼容性好; 缺点:请求次数比原来少,但是相对来也不少。
- websocket ,优点:代码简单,不再反复创建连接。 缺点:兼容性。
b. 在框架中使用WebSocket:
- django,channel
- flask,gevent-websocket
- tornado,内置
9.15 websocket
websocket是一套类似于http的协议。
扩展:
http协议:\r\n分割、请求头和请求体\r\n分割、无状态、短连接。
websocket协议:\r\n分割、创建连接后不断开、 验证+数据加密;
websocket本质:
- 就是一个创建连接后不断开的socket
- 当连接成功之后:
- 客户端(浏览器)会自动向服务端发送消息,包含: Sec-WebSocket-Key: iyRe1KMHi4S4QXzcoboMmw==
- 服务端接收之后,会对于该数据进行加密:
base64(sha1(swk + magic_string))
- 构造响应头:
HTTP/1.1 101 Switching Protocols\r\n
Upgrade:websocket\r\n
Connection: Upgrade\r\n
Sec-WebSocket-Accept: 加密后的值\r\n
WebSocket-Location: ws://127.0.0.1:8002\r\n\r\n
- 发给客户端(浏览器)
- 建立:双工通道,接下来就可以进行收发数据
- 发送的数据是加密,解密,根据payload_len的值进行处理:
- payload_len <=125
- payload_len ==126
- payload_len ==127
- 获取内容:
- mask_key
- 数据
根据mask_key和数据进行位运算,就可以把值解析出来。
面试:
a. 什么是websocket?
websocket是给浏览器新建一套协议。协议规定:浏览器和服务端连接之后不断开,以此可以完成:服务端向客户端主动推送消息。
websocket协议额外做的一些前天操作:
- 握手,连接前进行校验
- 发送数据加密
b. websocket本质
- socket
- 握手,魔法字符串+加密
- 加密,payload_len=127/126/<=125 -> mask key
9.16 自定义模板方法
- simple_tag
- filter
http://www.cnblogs.com/SunsetSunrise/p/7680491.html
- inclusion_tags
http://www.cnblogs.com/iyouyue/p/8626515.html
9.17 其他汇总
1) django所有组件?
分页
session
form
modelform 利用model生成form
auth
2) MTV和MVC?
MVC: model view controller
MTV: model tempalte view
3) 模板
- 索引: {{v.0}}
- 方法执行: {% for item in dic.items %} {%endfor%}
- 模板继承
- 自定义方法:
- simple_tag
- inclusion_tags
- filter
4) Form和ModelForm的作用?区别?应用场景?
- 作用:
- 对用户请求数据格式进行校验
- 自动生成HTML标签
- 区别:
- Form,字段需要自己手写。
class Form(Form):
xx = fields.CharField(.)
xx = fields.CharField(.)
xx = fields.CharField(.)
xx = fields.CharField(.)
- ModelForm,可以通过Meta进行定义
class MForm(ModelForm):
class Meta:
fields = "__all__"
model = UserInfo
- 应用:只要是客户端向服务端发送表单数据时,都可以进行使用,如:用户登录注册
5) 为什么要用缓存?
将常用且不太频繁修改的数据放入缓存。
以后用户再来访问,先去缓存查看是否存在,如果有就返回
否则,去数据库中获取并返回给用户(再加入到缓存,以便下次访问)
6) django内部支持哪些缓存?
Django中提供了6种缓存方式:
开发调试(不加缓存)
内存
文件
数据库
Memcache缓存(python-memcached模块)
Memcache缓存(pylibmc模块)
安装第三方组件支持redis:
django-redis组件
7) 设置缓存
- 全站缓存
- 视图函数缓存
- 局部模板缓存
8) django的信号作用?
django的信号其实就是django内部为开发者预留的一些自定制功能的钩子。
只要在某个信号中注册了函数,那么django内部执行的过程中就会自动触发注册在信号中的函数。
如:
pre_init # django的modal执行其构造方法前,自动触发
post_init # django的modal执行其构造方法后,自动触发
pre_save # django的modal对象保存前,自动触发
post_save # django的modal对象保存后,自动触发
用信号做过什么?
在数据库某些表中添加数据时,可以进行日志记录。
9) 序列化
内置:
from django.core import serializers
#queryset = [obj,obj,obj]
ret = models.BookType.objects.all()
data = serializers.serialize("json", ret)
json:
import json
#ret = models.BookType.objects.all().values('caption')
ret = models.BookType.objects.all().values_list('caption')
ret=list(ret)
result = json.dumps(ret)
补充:
- json.dumps(ensure_ascii=True)
- json.dumps( cls=JSONEncoder)
10) admin & stark组件
- 为公司定制更适用于自己的组件: stark组件
11) ContentType的作用?以及应用场景?
contenttype是django的一个组件(app),为我们找到django程序中所有app中的所有表并添加到记录中。
可以使用他再加上表中的两个字段实现:一张表和N张表创建FK关系。
- 字段:表名称
- 字段:数据行ID
应用:路飞表结构优惠券和专题课和学位课关联。
http://www.cnblogs.com/iyouyue/p/8810464.html
12) 幂等性是什么意思?
就是多次相同的操作,结果都不变
比如,读取一个文件,1次和10次,读出来的内容应该是一样的。
13) 远程数据交互的三种方式:
- webservice, webservice是在rest api广泛引用之前大家使用的一个跨平台交互的接口。
- restfull api
- RPC
扩展:WCF他是创建了一个双工通道。
14) HTTPS
Http: 80端
https: 443端口
- 自定义证书
- 服务端:创建一对证书
- 客户端:必须携带证书
- 购买证书
- 服务端: 创建一对证书……
- 客户端: 去机构获取证书,数据加密后发给咱们的服务单
- 证书机构:公钥给改机构
************************* 十.Flask*************************
10.1 django和flask区别?
(1)Flask
Flask确实很“轻”,不愧是Micro Framework,从Django转向Flask的开发者一定会如此感慨,除非二者均为深入使用过
Flask自由、灵活,可扩展性强,第三方库的选择面广,开发时可以结合自己最喜欢用的轮子,也能结合最流行最强大的Python库
入门简单,即便没有多少web开发经验,也能很快做出网站
非常适用于小型网站
非常适用于开发web服务的API
开发大型网站无压力,但代码架构需要自己设计,开发成本取决于开发者的能力和经验
各方面性能均等于或优于Django
Django自带的或第三方的好评如潮的功能,Flask上总会找到与之类似第三方库
Flask灵活开发,Python高手基本都会喜欢Flask,但对Django却可能褒贬不一
Flask与关系型数据库的配合使用不弱于Django,而其与NoSQL数据库的配合远远优于Django
Flask比Django更加Pythonic,与Python的philosophy更加吻合
(2)Django
Django太重了,除了web框架,自带ORM和模板引擎,灵活和自由度不够高
Django能开发小应用,但总会有“杀鸡焉用牛刀”的感觉
Django的自带ORM非常优秀,综合评价略高于SQLAlchemy
Django自带的模板引擎简单好用,但其强大程度和综合评价略低于Jinja
Django自带ORM也使Django与关系型数据库耦合度过高,如果想使用MongoDB等NoSQL数据,需要选取合适的第三方库,且总感觉Django+SQL才是天生一对的搭配,Django+NoSQL砍掉了Django的半壁江山
Django目前支持Jinja等非官方模板引擎
Django自带的数据库管理app好评如潮
Django非常适合企业级网站的开发:快速、靠谱、稳定
Django成熟、稳定、完善,但相比于Flask,Django的整体生态相对封闭
Django是Python web框架的先驱,用户多,第三方库最丰富,最好的Python库,如果不能直接用到Django中,也一定能找到与之对应的移植
Django上手也比较容易,开发文档详细、完善,相关资料丰富
10.2 flask组件
内置:
- 配置
- 路由
- 视图
- 模板
- session
- 闪现
- 蓝图
- 中间件
- 特殊装饰器
第三方:
- Flask组件:
- flask-session
- flask-SQLAlchemy
- flask-migrate
- flask-script
- blinker
- 公共组件:
- wtforms
- dbutile
- sqlalchemy
- 自定义Flask组件
- auth ,参考flask-login组件
10.3 上下文管理流程主要涉及到了那些类?并描述类主要作用?
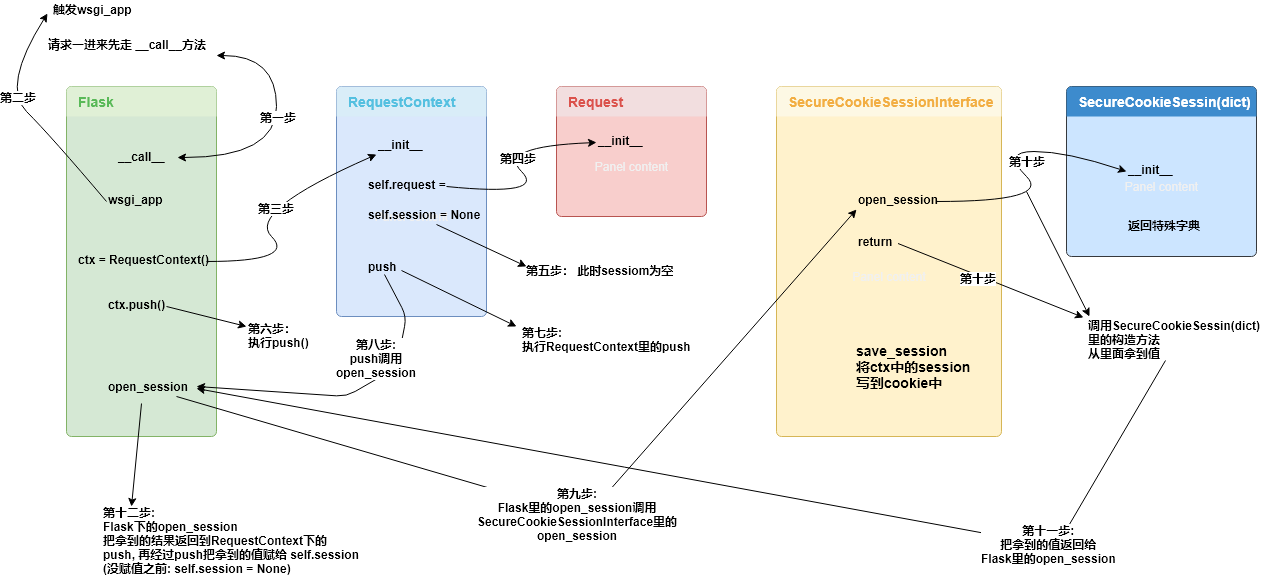
每次有请求过来的时候,flask 会先创建当前线程或者进程需要处理的两个重要上下文对象,把它们保存到隔离的栈里面,这样视图函数进行处理的时候就能直接从栈上获取这些信息。
参考链接:http://python.jobbole.com/87398/
10.4 为什么实用LocalStack对Local对象进行操作?
目的是想要将local中的值维护成一个栈,例如:在多app应用中编写离线脚本时,可以实用上。
from m_app import app01,app02
from flask import current_app
"""
{
1231: {
stack: [app01,app02,]
}
}
"""
with app01.app_context():
print(current_app)
with app02.app_context():
print(current_app)
print(current_app)
10.5 threading.local 以及作用
a. threading.local
作用:为每个线程开辟一块空间进行数据存储。
问题:自己通过字典创建一个类似于threading.local的东西。
storage={
4740:{val:0},
4732:{val:1},
4731:{val:3},
...
}
b. 自定义Local对象
作用:为每个线程(协程)开辟一块空间进行数据存储。
try:
from greenlet import getcurrent as get_ident
except Exception as e:
from threading import get_ident
from threading import Thread
import time
class Local(object):
def __init__(self):
object.__setattr__(self,'storage',{})
def __setattr__(self, k, v):
ident = get_ident()
if ident in self.storage:
self.storage[ident][k] = v
else:
self.storage[ident] = {k: v}
def __getattr__(self, k):
ident = get_ident()
return self.storage[ident][k]
obj = Local()
def task(arg):
obj.val = arg
obj.xxx = arg
print(obj.val)
for i in range(10):
t = Thread(target=task,args=(i,))
t.start()
10.6 SQLAlchemy中的 session 的创建有几种方式?
- 直接创建Session对象
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
def task(arg):
session = Session()
obj1 = Users(name="alex1")
session.add(obj1)
session.commit()
for i in range(10):
t = threading.Thread(target=task, args=(i,))
t.start()
- 基于scoped_session(Flask-SQLAlchemy中的连接默认使用该方法)
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = scoped_session(Session)
def task(arg):
obj1 = Users(name="alex1")
session.add(obj1)
session.commit()
for i in range(10):
t = threading.Thread(target=task, args=(i,))
t.start()
https://www.cnblogs.com/wupeiqi/articles/8259356.html
10.7 其他汇总
1)flask源码解析之简介两个依赖
(werkzeug和jinja2)
2)Flask中的g的作用?
g对象是在一个请求中共享变量,不同的请求对应的是不同的g对象。
************************* 十一.ORM*************************
11.1 增删改查
增
1) models.UserInfo.objects.create()
2) obj = models.UserInfo(name='xx')
obj.save()
3) models.UserInfo.objects.bulk_create([models.UserInfo(name='xx'),models.UserInfo(name='xx')])
删
1) models.UserInfo.objects.all().delete()
改
1) models.UserInfo.objects.all().update(age=18)
2) b = Book.objects.get(id=5) # 注意这里是get方法,只能拿1个,不能用filter。
b.price = 300
b.save()
3) models.UserInfo.objects.all().update(salary=F('salary')+1000)
查
1) 见下文详细介绍
11.2 13条常用查询方法
返回QuerySet对象的方法有:
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet:
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元组序列
返回具体对象的:
get()
first()
last()
返回布尔值的方法有:
exists()
返回数字的方法有:
count()
11.3 双下划线方法
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
models.Tb1.objects.filter(name__contains="ven") # 获取name字段包含"ven"的
models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
models.Tb1.objects.filter(id__range=[1, 3]) # id范围是1到3的,等价于SQL的bettwen and
类似的还有:startswith,istartswith, endswith, iendswith
date字段还可以:
models.Class.objects.filter(first_day__year=2017)
11.4 执行原生SQL的三种方式
1.使用execute执行自定义SQL
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()
2.使用extra方法
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
3.使用raw方法
解释:执行原始sql并返回模型
说明:依赖model多用于查询
用法:
book = Book.objects.raw("select * from hello_book")
for item in book:
print(item.title)
https://www.cnblogs.com/413xiaol/p/6504856.html
设置了related_query_name 反向查找时就是obj.别名_set.all()保留了_set
from django.db import models
class Userinfo(models.Model):
nikename=models.CharField(max_length=32)
username=models.CharField(max_length=32)
password=models.CharField(max_length=64)
sex=((1,'男'),(2,'女'))
gender=models.IntegerField(choices=sex)
'''把男女表混合在一起,在代码层面控制第三张关系表的外键关系 '''
#写到此处问题就来了,原来两个外键 对应2张表 2个主键 可以识别男女
#现在两个外键对应1张表 反向查找 无法区分男女了了
# object对象女.U2U.Userinfo.set object对象男.U2U.Userinfo.set
#所以要加related_query_name对 表中主键 加以区分
class U2U(models.Model):
b=models.ForeignKey(Userinfo,related_query_name='a')
g=models.ForeignKey(Userinfo,related_query_name='b')
****************
设置了related_name就是 反向查找时就说 obj.别名.all()
上面例子换成
class U2U(models.Model):
b=models.ForeignKey(Userinfo,related_name='a')
g=models.ForeignKey(Userinfo,related_name='b')
#查找方法
# 男 obj.a.all()
# 女 obj.b.all()
http://www.cnblogs.com/heysn21/articles/8652211.html
11.6 分组函数和聚合函数
1、aggregate(*args,**kwargs) 聚合函数
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成聚合。
from django.db.models import Avg,Sum,Max,Min
#求书籍的平均价
ret=models.Book.objects.all().aggregate(Avg('price'))
#{'price__avg': 145.23076923076923}
#参与西游记著作的作者中最老的一位作者
ret=models.Book.objects.filter(title__icontains='西游记').values('author__age').aggregate(Max('author__age'))
#{'author__age__max': 518}
#查看根哥出过得书中价格最贵一本
ret=models.Author.objects.filter(name__contains='根').values('book__price').aggregate(Max('book__price'))
#{'book__price__max': Decimal('234.000')}
2、annotate(*args,**kwargs) 分组函数
#查看每一位作者出过的书中最贵的一本(按作者名分组 values() 然后annotate 分别取每人出过的书价格最高的)
ret=models.Book.objects.values('author__name').annotate(Max('price'))
# < QuerySet[
# {'author__name': '吴承恩', 'price__max': Decimal('234.000')},
# {'author__name': '吕不韦','price__max': Decimal('234.000')},
# {'author__name': '姜子牙', 'price__max': Decimal('123.000')},
# {'author__name': '亚微',price__max': Decimal('123.000')},
# {'author__name': '伯夷 ', 'price__max': Decimal('2010.000')},
# {'author__name': '叔齐','price__max': Decimal('200.000')},
# ] >
#查看每本书的作者中最老的 按作者姓名分组 分别求出每组中年龄最大的
ret=models.Book.objects.values('author__name').annotate(Max('author__age'))
# < QuerySet[
# {'author__name': '吴承恩', 'author__age__max': 518},
# {'author__name': '金庸', 'author__age__max': 89},
# ] >
#查看 每个出版社 出版的最便宜的一本书
ret=models.Book.objects.values('publish__name').annotate(Min('price'))
# < QuerySet[
# {'publish__name': '清华出版社','price__min': Decimal('67.000')},
# {'publish__name': '机械出版社','price__min': Decimal('34.000')},
# ] >
11.7 F和Q查询
F:
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
修改操作也可以使用F函数,比如将每一本书的价格提高30元
例:把所有书名后面加上(第一版)
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.all().update(title=Concat(F("title"), Value("("), Value("第一版"), Value(")")))
Q:
Q(条件1) | Q(条件2) 或
Q(条件1) & Q(条件2) 且
Q(条件1) & ~Q(条件2) 非
title = models.CharField(max_length=32)
class UserInfo(models.Model):
name = models.CharField(max_length=32)
email = models.CharField(max_length=32)
ut = models.ForeignKey(to='UserType')
ut = models.ForeignKey(to='UserType')
ut = models.ForeignKey(to='UserType')
ut = models.ForeignKey(to='UserType')
# 1次SQL
# select * from userinfo
objs = UserInfo.obejcts.all()
for item in objs:
print(item.name)
# n+1次SQL
# select * from userinfo
objs = UserInfo.obejcts.all()
for item in objs:
# select * from usertype where id = item.id
print(item.name,item.ut.title)
示例1:
.select_related()
# 1次SQL
# select * from userinfo inner join usertype on userinfo.ut_id = usertype.id
objs = UserInfo.obejcts.all().select_related('ut')
for item in objs:
print(item.name,item.ut.title)
示例2:
.prefetch_related()
# select * from userinfo where id <= 8
# 计算:[1,2]
# select * from usertype where id in [1,2]
objs = UserInfo.obejcts.filter(id__lte=8).prefetch_related('ut')
for obj in objs:
print(obj.name,obj.ut.title)
两个函数的作用都是减少查询次数
示例3:
update()和对象.save()修改方式的性能PK
方式1
models.Book.objects.filter(id=1).update(price=3)
方式2
book_obj=models.Book.objects.get(id=1)
book_obj.price=5
book_obj.save()
结论:
update() 方式1修改数据的方式,比obj.save()性能好
11.9 取消外键约束用 db_constraint=False
无约束:
class UserType(models.Model):
title = models.CharField(max_length=32)
class UserInfo(models.Model):
name = models.CharField(max_length=32)
email = models.CharField(max_length=32)
# 无数据库约束,但可以进行链表
ut = models.ForeignKey(to='UserType',db_constraint=False)
11.10 QuerySet方法大全
##################################################################
# PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
##################################################################
def all(self)
# 获取所有的数据对象
def filter(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
model.tb.objects.all().select_related()
model.tb.objects.all().select_related('外键字段')
model.tb.objects.all().select_related('外键字段__外键字段')
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
# 获取所有用户表
# 获取用户类型表where id in (用户表中的查到的所有用户ID)
models.UserInfo.objects.prefetch_related('外键字段')
from django.db.models import Count, Case, When, IntegerField
Article.objects.annotate(
numviews=Count(Case(
When(readership__what_time__lt=treshold, then=1),
output_field=CharField(),
))
)
students = Student.objects.all().annotate(num_excused_absences=models.Sum(
models.Case(
models.When(absence__type='Excused', then=1),
default=0,
output_field=models.IntegerField()
)))
def annotate(self, *args, **kwargs)
# 用于实现聚合group by查询
from django.db.models import Count, Avg, Max, Min, Sum
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo
注:只有在PostgreSQL中才能使用distinct进行去重
def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by('-id','age')
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列数据
def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id')
def using(self, alias):
指定使用的数据库,参数为别名(setting中的设置)
##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
##################################################
def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid from 其他表')
# 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default")
################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
def values(self, *fields):
# 获取每行数据为字典格式
def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖
def dates(self, field_name, kind, order='ASC'):
# 根据时间进行某一部分进行去重查找并截取指定内容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并获取转换后的时间
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日
models.DatePlus.objects.dates('ctime','day','DESC')
def datetimes(self, field_name, kind, order='ASC', tzinfo=None):
# 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo时区对象
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC)
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai'))
"""
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai’)
"""
def none(self):
# 空QuerySet对象
####################################
# METHODS THAT DO DATABASE QUERIES #
####################################
def aggregate(self, *args, **kwargs):
# 聚合函数,获取字典类型聚合结果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid'))
===> {'k': 3, 'n': 4}
def count(self):
# 获取个数
def get(self, *args, **kwargs):
# 获取单个对象
def create(self, **kwargs):
# 创建对象
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
def get_or_create(self, defaults=None, **kwargs):
# 如果存在,则获取,否则,创建
# defaults 指定创建时,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2})
def update_or_create(self, defaults=None, **kwargs):
# 如果存在,则更新,否则,创建
# defaults 指定创建时或更新时的其他字段
obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1})
def first(self):
# 获取第一个
def last(self):
# 获取最后一个
def in_bulk(self, id_list=None):
# 根据主键ID进行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list)
def delete(self):
# 删除
def update(self, **kwargs):
# 更新
def exists(self):
# 是否有结果
11.11 其他汇总
如果A表的1条记录对应B表中N条记录成立,两表之间就是1对多关系;在1对多关系中 A表就是主表,B表为子表,ForeignKey字段就建在子表;
如果B表的1条记录也对应A表中N条记录,两表之间就是双向1对多关系,也称为多对多关系
char 和 varchar的区别 :
char和varchar的共同点是存储数据的长度,不能 超过max_length限制,不同点是varchar根据数据实际长度存储,char按指定max_length()存储数据;所有前者更节省硬盘空间
http://www.cnblogs.com/liwenzhou/p/8660826.html
************************* 十二.rest framework*************************
12.1 谈谈你对restfull 规范的认识?
- restful其实就是一套编写接口的协议,协议规定如何编写以及如何设置返回值、状态码等信息。
- 最显著的特点:
restful: 给用户一个url,根据method不同在后端做不同的处理,比如:post 创建数据、get获取数据、put和patch修改数据、delete删除数据。
no rest: 给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/
- 当然,还有协议其他的,比如:
- 版本,来控制让程序有多个版本共存的情况,版本可以放在 url、请求头(accept/自定义)、GET参数
- 状态码,200/300/400/500
- url中尽量使用名词,restful也可以称为“面向资源编程”
- api标示:
api.YueNet.com
www.YueNet.com/api/
-------------------------------------------------
- https
- 域名
- api.oldboy.com
- www.oldboy.com/api
- 版本:
- www.oldboy.com/api/v1
- URL资源,名词
- www.oldboy.com/api/v1/student
- 请求方式:
- GET/POST/PUT/DELETE/PATCH/OPTIONS/HEADERS/TRACE
- 返回值:
- www.oldboy.com/api/v1/student/ -> 结果集
- www.oldboy.com/api/v1/student/1/ -> 单个对象
- URL添加条件
- www.oldboy.com/api/v1/student?page=11&size=9
- 状态码:
- 200
- 300
- 301
- 302
- 400
- 403
- 404
- 500
- 错误信息
{
code:1000,
meg:'xxxx'
}
- hyperlink
{
id:1
name: ‘xiangl’,
type: http://www.xxx.com/api/v1/type/1/
}
12.2 rest framework都有哪些组件?
- 路由,自动帮助开发者快速为一个视图创建4个url
www.oldboyedu.com/api/v1/student/$
www.oldboyedu.com/api/v1/student(?P<format>\w+)$
www.oldboyedu.com/api/v1/student/(?P<pk>\d+)/$
www.oldboyedu.com/api/v1/student/(?P<pk>\d+)(?P<format>\w+)$
- 版本处理
- 问题:版本都可以放在那里?
- url
- GET
- 请求头
- 认证
- 问题:认证流程?
- 权限
- 权限是否可以放在中间件中?以及为什么?
- 访问频率的控制
- 匿名用户可以真正的防止?无法做到真正的访问频率控制,只能把小白拒之门外。
如果要封IP,使用防火墙来做。
- 登录用户可以通过用户名作为唯一标示进行控制,如果有人注册很多账号,也无法防止。
- 视图
- 解析器 ,根据Content-Type请求头对请求体中的数据格式进行处理。request.data
- 分页
- 序列化
- 序列化
- source
- 定义方法
- 请求数据格式校验
- 渲染器
12.3 视图中都可以继承哪些类?
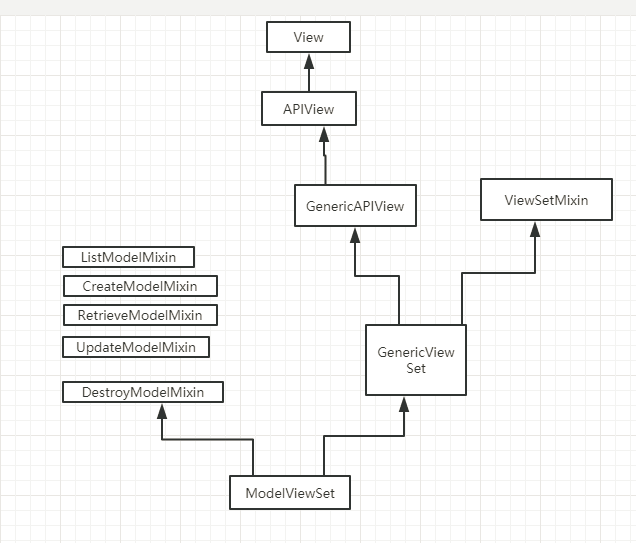
a. 继承 APIView
这个类属于rest framework中顶层类,内部帮助我们实现了只是基本功能:认证、权限、频率控制,但凡是数据库、分页等操作都需要手动去完成,比较原始。
class GenericAPIView(APIView)
def post(...):
pass
b. 继承 GenericViewSet(ViewSetMixin, generics.GenericAPIView)
如果继承它之后,路由中的as_view需要填写对应关系 .as_view({'get':'list','post':'create'})
在内部也帮助我们提供了一些方便的方法:
- get_queryset
- get_object
- get_serializer
注意:要设置queryset字段,否则会跑出断言的异常。
# 只提供增加功能
class TestView(GenericViewSet):
serializer_class = XXXXXXX
def create(self,*args,**kwargs):
pass # 获取数据并对数据进行操作
c. 继承
- ModelViewSet
- mixins.CreateModelMixin,GenericViewSet
- mixins.CreateModelMixin,DestroyModelMixin,GenericViewSet
对数据库和分页等操作不用我们在编写,只需要继承相关类即可。
示例:只提供增加功能
class TestView(mixins.CreateModelMixin,GenericViewSet):
serializer_class = XXXXXXX
http://www.cnblogs.com/iyouyue/p/8798572.html#_label3
12.4 认证流程
- 如何编写?写类并实现authticate
- 方法中可以定义三种返回值:
- (user,auth),认证成功
- None , 匿名用户
- 异常 ,认证失败
- 流程:
- dispatch
- 再去request中进行认证处理
https://www.cnblogs.com/haiyan123/p/8419872.html
12.5 访问频率控制
- 匿名用户,根据用户IP或代理IP作为标识进行记录,为每一个用户在redis中创建一个列表
{
throttle_1.1.1.1:[1526868876.497521,152686885.497521...]
throttle_1.1.1.2:[1526868876.497521,152686885.497521...]
throttle_1.1.1.3:[1526868876.497521,152686885.497521...]
throttle_1.1.1.4:[1526868876.497521,152686885.497521...]
throttle_1.1.1.5:[1526868876.497521,152686885.497521...]
}
每个用户再来访问时,需要先去记录中剔除以及过期时间,再根据列表的长度判断是否可以继续访问。
如何封IP:在防火墙中进行设置
- 注册用户,根据用户名或邮箱进行判断。
{
throttle_xxxx1:[1526868876.497521,152686885.497521...]
throttle_xxxx2:[1526868876.497521,152686885.497521...]
throttle_xxxx3:[1526868876.497521,152686885.497521...]
throttle_xxxx4:[1526868876.497521,152686885.497521...]
}
每个用户再来访问时,需要先去记录中剔除以及过期时间,再根据列表的长度判断是否可以继续访问。
1分钟:40次
12.6 接口的幂等性(判断是否会造成二次伤害)
一个接口通过首先进行1次访问,然后对该接口进行N次相同访问的时候,对访问对象不造成影响,那么就认为接口具有幂等性。
比如:
GET, 第一次获取数据、第二次也是获取结果,幂等。
POST, 第一次新增数据,第二次也会再次新增,非幂等。
PUT, 第一次更新数据,第二次不会再次更新,幂等。
PATCH,第一次更新数据,第二次可能再次更新,非幂等。
DELTE,第一次删除数据,第二次不会再次删除,幂等。
12.7 为什么要使用django rest framework框架?
在编写接口时可以不适用django rest framework框架,
如果不使用:也可以做,那么就可以django的CBV来实现,开发者编写的代码会更多一些。
如果 使用:内部帮助我们提供了很多方便的组件,我们通过配置就可以完成相应操作,如:
- 序列化,可以做用户请求数据校验+queryset对象的序列化称为json
- 解析器,获取用户请求数据request.data,会自动根据content-type请求头的不能对数据进行解析
- 分页,将从数据库获取到的数据在页面进行分页显示。
还有其他:
- 认证
- 权限
- 访问频率控制
...
12.8 其他汇总
1)渲染器有坑
- 指定渲染器只用JSON
- 视图:
class UserView(...):
queryset = [] # 必写
...
2)assert 是的作用?
条件成立则继续往下,否则跑出异常,一般用于:满足某个条件之后,才能执行,否则应该跑出异常。
应用场景:rest framework
class GenericAPIView(views.APIView):
queryset = None
serializer_class = None
# If you want to use object lookups other than pk, set 'lookup_field'.
# For more complex lookup requirements override `get_object()`.
lookup_field = 'pk'
lookup_url_kwarg = None
# The filter backend classes to use for queryset filtering
filter_backends = api_settings.DEFAULT_FILTER_BACKENDS
# The style to use for queryset pagination.
pagination_class = api_settings.DEFAULT_PAGINATION_CLASS
def get_queryset(self):
assert self.queryset is not None, (
"'%s' should either include a `queryset` attribute, "
"or override the `get_queryset()` method."
% self.__class__.__name__
)
queryset = self.queryset
if isinstance(queryset, QuerySet):
# Ensure queryset is re-evaluated on each request.
queryset = queryset.all()
return queryset
3) 用django写接口时,有没有用什么框架?
- 使用rest framework框架
- 原生CBV
4) rest framework框架优点?
rest framework帮助开发者提供了很多组件,可以提高开发效率。
************************* 十三.计算机基础*************************
13.1 HTTP协议请求方法和状态码
流程:
1.域名解析
域名解析检查顺序为:浏览器自身DNS缓存---》OS自身的DNS缓存--》读取host文件--》本地域名服务器--》权限域名服务器--》根域名服务器。如果有且没有过期,则结束本次域名解析。域名解析成功之后,进行后续操作
2.tcp3次握手建立连接
3.建立连接后,发起http请求
4.服务器端响应http请求,浏览器得到到http请求的内容
5.浏览器解析html代码,并请求html代码中的资源
6.浏览器对页面进行渲染,展现在用户面前
请求方法有8种,分别为:
GET:请求获取由 Request-URI 所标识的资源。
POST:在 Request-URI 所标识的资源后附加新的数据。
HEAD:请求获取由 Request-URI 所标识的资源的响应消息报头。
OPTIONS:请求查询服务器的性能,或查询与资源相关的选项和需求。
PUT:请求服务器存储一个资源,并用 Request-URI作为其标识。
DELETE:请求服务器删除由 Request-URI所标识的资源。
TRACE:请求服务器回送收到的请求信息,主要用语测试或诊断。
CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
常见的响应状态码有以下几种,在各种下面分别列几个常见的状态码:
1开头(信息)
2开头(成功)
200(OK):请求成功
202(Accepted):已接受请求,尚未处理
204(No Content):请求成功,且不需返回内容
3开头(重定向)
301(Moved Permanently):被请求的资源已永久移动到新位置
301(Moved Temporarily):被请求的资源已临时移动到新位置
4开头(客户端错误)
400(Bad Request):请求的语义或是参数有错
403(Forbidden):服务器拒绝了请求
404(Not Found):未找到请求的资源
5开头(服务器错误)
500(Internal Server Error):服务器遇到错误,无法完成请求
502(Bad Getway):网关错误,一般是服务器压力过大导致连接超时
503(Service Unavailable):服务器宕机
https://blog.csdn.net/zixiaomuwu/article/details/60778462


