
java容器类:HashMap
HashMap源码分块阅读(2)#
HashMap类定义了属性和方法,其中方法又有共用方法(get,put,remove等)和私用方法(hash,resize等)
HashMap的属性##
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
如果未指定HashMap的容量,那么默认容量就是16,HashMap的容量都是偶数.- static final int MAXIMUM_CAPACITY = 1 << 30;
如果指定的容量超过这个这个值,那么这个值将会被启用.应该是用来防止容量过大的.- static final float DEFAULT_LOAD_FACTOR = 0.75f;
如果未指定HashMap负载因子,那么默认的因子就是0.75.- static final Entry[] EMPTY_TABLE = {};
一个空的Entry数组,后面会被用来下面的table比较- transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
用于存储HashMap数据的数组对象.用transient修饰表示这个对象不可被序列化.- transient int size;
代表HashMap的大小,由HashMap中的键值对决定- int threshold;
HashMap的阀值,假设容量和负载因子为默认值,那么HashMap中存储的键值对超过16*0.75,也就是阀值等于12,那么HashMap就会扩容.- final float loadFactor;
负载因子- transient int modCount;
HashMap的结构被改变的次数,结构性改变是指改变HashMap键值对映射的数量或者修改内部结构(例如:再哈希).这个域用来造成Collecttion类的迭代器的快速失败.- HashMap采用除数取余法实现散列,假定一个键值对的key为一个String字符串,那么用String类的hashCode()方法获得hashCode.hashCode/size得到的余数就是这个键值对要存储在HashMap中的位置.我使用的jdk版本是1.7,类中还提供了一个替代哈希方法.如果启用替代hash方法,若key为String类型,那么就将计算哈希码的方法从hashCOde()替换为StringHash32().是否使用替代哈希取决于系统变量jdk.map.althashing.threshold,然而我并不知道怎么设置这个变量,System.setProperty方法也没有用.
- 这些转换都是在静态内部类Holder中处理的
private static class Holder {
/**
* Table capacity above which to switch to use alternative hashing.
*/
static final int ALTERNATIVE_HASHING_THRESHOLD;
static {
String altThreshold = java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction(
"jdk.map.althashing.threshold"));
int threshold;
try {
threshold = (null != altThreshold)
? Integer.parseInt(altThreshold)
: ALTERNATIVE_HASHING_THRESHOLD_DEFAULT;
// disable alternative hashing if -1
if (threshold == -1) {
threshold = Integer.MAX_VALUE;
}
if (threshold < 0) {
throw new IllegalArgumentException("value must be positive integer.");
}
} catch(IllegalArgumentException failed) {
throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed);
}
ALTERNATIVE_HASHING_THRESHOLD = threshold;
}
}
HashMap运行步骤##
- 1.初始化: HashMap有三种构造方法:1.HashMap(int initialCapacity, float loadFactor),2.HashMap(int initialCapacity),3.HashMap().
第一种可以指定容量和负载因子,第二种指定容量,负载因子默认为0.75,第三种调用第一种的构造方法,容量和负载因子都是默认值:16,0.75- 2.插入数据:最基础的就是put()方法了,put步骤分5步:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
//1.判断表是否为空,若为空,则进行膨胀.
//inflateTable方法做了什么?:
//a.将容量扩充最小的2的n次幂,且大于之前设置的容量,例如设置为5,那么会膨胀为8;如果是9,那么膨胀为16.
//b.初始化阀值threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//c.初始化table = new Entry[capacity];
//调用initHashSeedAsNeeded(capacity)方法初始化hashseed,这个变量决定要不要使用StringHash32()方法生成哈希码
}
if (key == null)
return putForNullKey(value);
//2.若key为空,调用putForNullKey()方法,key为null的值默认保存在table数组的第一个位置,即table[0],通过遍历table[0]的Entry节点来定位和处理数据.
int hash = hash(key);
//3.hash方法计算得出传入key的hashCode
int i = indexFor(hash, table.length);
//4.indexFor方法得出键值对在table中的位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
//5.遍历Entry节点定位并处理数据
}
modCount++;
addEntry(hash, key, value, i);
return null;
}

- 这是HashMap的数据结构图,table是一个Entry数组,通过put方法添加的键值对将以Entry类的形式添加到table[i]中,i即为indexFor方法得出的余数,若多个不同的hashCode得到的余数一致,那么就会像table[1]一样挂了好多的Entry对象,这被称为散列冲突,冲突越厉害,那么对HashMap的性能影响越大.
- 可以分析一下addEntry方法
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {//如果Entry的数量高于阀值,而且这个索引的table中没有存放任何Entry,那么进行扩容
resize(2 * table.length);//将table的长度扩充一倍,并将table中存储的Entry在重新通过除数取余法进行排布,工作量比较大,很影响性能.
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);//重新计算存放的位置
}
createEntry(hash, key, value, bucketIndex);//实例化一个Entry对象,将key和value存入其中
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; //得到当前节点存储的Entry
table[bucketIndex] = new Entry<>(hash, key, value, e); //然后将新的Entry放入table的对应节点,并将刚刚得到的Entry挂在新的Entry尾部.
size++; //扩充Entry的数量
}
上述三张图就是一个键值对存入HashMap中的过程
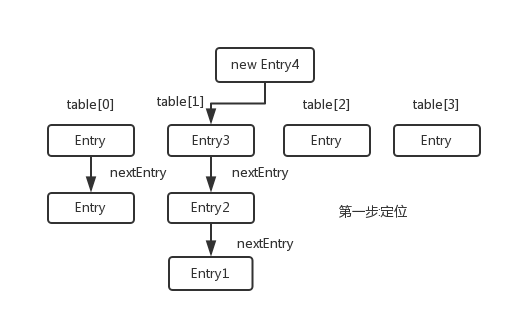


- 3.查找数据
查找和添加类似,首先根据key计算出数组的索引值(如果key为null,则索引值为0),然后顺序查找该索引值对应的Entry链,如果在Entry链中找到相等的key,则表示找到相应的Entry记录,否则,表示没找到,返回null。对get()操作返回Entry中的Value值,对于containsKey()操作,则判断是否存在记录,两个方法都调用getEntry()方法:
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
- 4.删除数据
移除操作(remove())也是先通过key值计算数组中的索引号(当key为null时索引号为0),从而找到Entry链,查找Entry链中的Entry,并将该Entry删除。
- 5.遍历
HashMap中实现了一个HashIterator,它首先遍历数组,查找到一个非null的Entry实例,记录该Entry所在数组索引,然后在下一个next()操作中,继续查找下一个非null的Entry,并将之前查找到的非null Entry返回。为实现遍历时不能修改HashMap的内容(可以更新已存在的记录的值,但是不可以添加、删除原有记录),HashMap记录一个modCount字段,在每次添加或删除操作起效时,将modCount自增,而在创建HashIterator时记录当前的modCount值(expectedModCount),如果在遍历过程中(next()、remove())操作时,HashMap中的modCount和已存储的expectedModCount不一样,表示HashMap已经被修改,抛出ConcurrentModificationException。即上面提到的fail fast。
在HashMap中返回的key、value、Entry集合都是基于该Iterator实现.

