
python类库31[httplib2处理http的get和post]
一 http的get和post
get和post的区别:get是从服务器上获取数据,post是向服务器传送数据。
(1)参数传输方式,
GET提交,请求的数据会附在URL之后,以?分割URL和传输数据,多个参数用&连接;例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体中。因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变。
(2)传输数据的大小,
首先声明HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。因此对于GET提交时,传输数据就会受到URL长度的限制。
POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
(3)安全性:
POST的安全性要比GET的安全性高。这里安全的含义是真正的Security的含义,比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存, (2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击。
get和post的相同: get,post协议都是在http上运行的。
get:请求参数是作为一个key/value对的序列(查询字符串)附加到URL上的查询字符串的长度受到web浏览器和web服务器的限制(如IE最多支持2048个字符),不适合传输大型数据集同时,它很不安全。
post:请求参数是在http标题的一个不同部分(名为entity body)传输的,这一部分用来传输表单信息,因此必须将Content-type设置为:application/x-www-form- urlencoded。post设计用来支持web窗体上的用户字段,其参数也是作为key/value对传输。但是:它不支持复杂数据类型,因为post没有定义传输数据结构的语义和规则。
简单地讲,HTTP web 服务是指以编程的方式直接使用 HTTP 操作从远程服务器发送和接收数据。如果你要从服务器获取数据,使用HTTP GET;如果你要向服务器发送新数据,使用HTTP POST. 一些更高级的HTTP Web 服务 API也允许使用HTTP PUT 和 HTTP DELETE来创建、修改和删除数据。
二 web实例
实例来自:http://fy.webxml.com.cn/webservices/EnglishChinese.asmx?op=TranslatorString ,用来实现中英文的翻译的免费的webservice,同时提供get+post+soap访问支持。
三 python的http web库
Python 3 带有两个库用于和HTTP web 服务交互:
•http.client 是HTTP 协议的底层库.
•urllib.request 建立在http.client之上一个抽象层。它为访问HTTP 和 FTP 服务器提供了一个标准的API,可以自动跟随HTTP 重定向, 并且处理了一些常见形式的HTTP 认证。
•httplib2,一个第三方的开源库,它比http.client更完整的实现了HTTP协议,同时比urllib.request提供了更好的抽象。
python的HTTP库不支持缓存,而httplib2支持。
Python的HTTP 库不支持最后修改时间检查,而httplib2 支持。
Python HTTP库不支持ETag,而httplib2支持.
Python的 HTTP库不支持压缩,但httplib2支持。
httplib2 帮你处理了永久重定向。它不仅会告诉你发生了永久重定向,而且它会在本地记录这些重定向,并且在发送请求前自动重写为重定向后的URL。
httplib2的
下载:http://code.google.com/p/httplib2/
安装:python31 setup.py install
四 httplib2使用get和post实例

# -*- coding: UTF-8 -*-
def TestHttpGet():
import httplib2
#httplib2.debuglevel = 1
word='中国'
urlstr = 'http://fy.webxml.com.cn/webservices/EnglishChinese.asmx/TranslatorString' + '?wordKey=' + word
h = httplib2.Http('.cache')
response,content = h.request(urlstr)
#for item in response.items(): print(item)
print(content.decode('utf-8'))
#print(content)
def TestHttpPost():
import httplib2
from urllib.parse import urlencode
#httplib2.debuglevel = 1
word='美国'
urlstr = 'http://fy.webxml.com.cn/webservices/EnglishChinese.asmx/TranslatorString'
data={'wordKey':word}
h = httplib2.Http('.cache')
response,content = h.request(urlstr, 'POST', urlencode(data), headers={'Content-Type': 'application/x-www-form-urlencoded'})
#for item in response.items(): print(item)
print(content.decode('utf-8'))
#print(content)
TestHttpGet()
TestHttpPost()
结果如下:
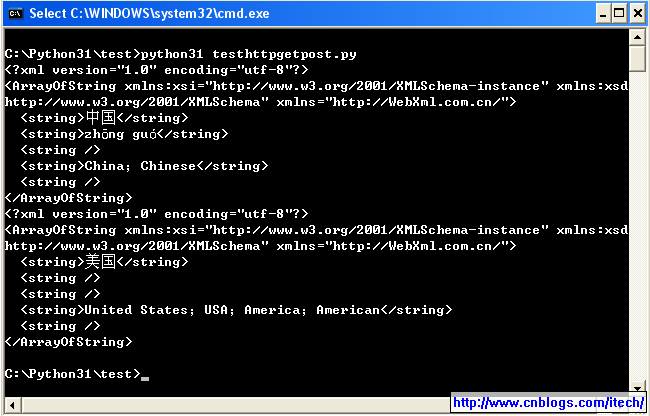
当从英文到中文翻译后得到的结果xml貌似不是utf8的,总是有错误:
content.decode('utf-8')报错UnicodeEncodeError: 'gbk' codec can't encode character '\u0283' in position 224: illegal multibyte sequence
完!


【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步