
python实例31[urllib.request.urlopen获取股票信息]
① 在Python中通过HTTP下载东西是非常简单的; 实际上,只需要一行代码。urllib.request模块有一个方便的函数urlopen() ,它接受你所要获取的页面地址,然后返回一个类文件对象,您只要调用它的read()方法就可以获得网页的全部内容。没有比这更简单的了。
② urlopen().read()方法总是返回bytes对象,而不是字符串。记住字节仅仅是字节,字符只是一种抽象。 HTTP 服务器不关心抽象的东西。如果你请求一个资源,你得到字节。 如果你需要一个字符串,你需要确定字符编码,并显式的将其转化成字符串。
代码如下:
import urllib.request
debug=False
class Utility:
def ToGB(str):
if(debug): print(str)
return str.decode('gb2312')
class StockInfo:
"""get stock information"""
def GetStockStrByNum(num):
f= urllib.request.urlopen('http://hq.sinajs.cn/list='+ str(num))
if(debug) : print(f.geturl())
if(debug) : print(f.info())
return f.readline()
f.close()
def ParseResultStr(resultstr):
if(debug) : print(resultstr)
slist=resultstr.split(',')
name=slist[0][-4:]
yesterdayendprice=slist[2]
todaystartprice=slist[1]
nowprice=slist[3]
upgraderate=(float(nowprice)-float(yesterdayendprice))/float(yesterdayendprice)
upgraderate= upgraderate * 100
dateandtime=slist[30] + ' ' + slist[31]
print('*******************************')
print('name is :',name)
print('yesterday end price is :', yesterdayendprice)
print('today start price is :', todaystartprice)
print('now price is :', nowprice)
print('upgrade rate is :', upgraderate,'%')
print('date and time is :', dateandtime)
print('*******************************')
def GetStockInfo(num):
str=StockInfo.GetStockStrByNum(num)
strGB=Utility.ToGB(str)
StockInfo.ParseResultStr(strGB)
def Main():
stocks = ['sh600547', 'sh600151', 'sz000593']
for stock in stocks:
StockInfo.GetStockInfo(stock)
Main()
结果:
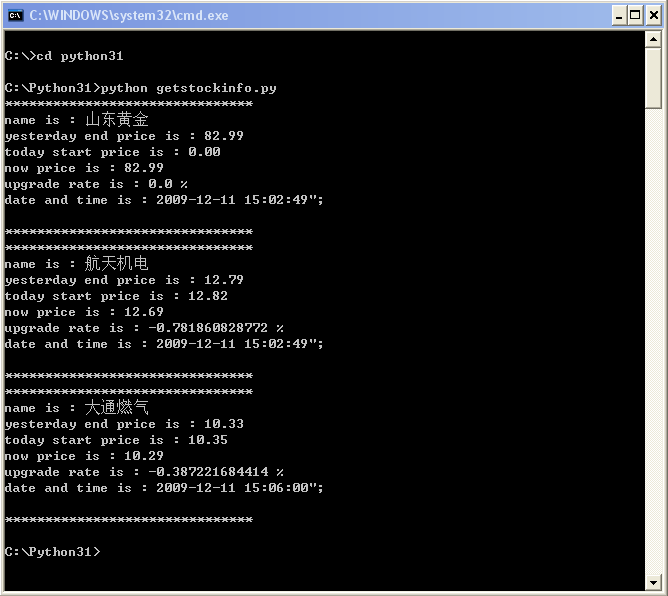
参考:http://www.cnblogs.com/blodfox777/archive/2009/02/10/1387229.html
完!


