
C++ 提取网页内容系列之五 整合爬取豆瓣读书
工作太忙 没有时间细化了 就说说 主要内容吧
下载和分析漫画是分开的
下载豆瓣漫画页面是使用之前的文章的代码
见http://www.cnblogs.com/itdef/p/4171179.html
http://www.cnblogs.com/itdef/p/4081963.html
注意 豆瓣网是https
下载后进行页面分析
fstream fs(szfileName);
stringstream ss; // 创建字符串流对象
ss << fs.rdbuf(); // 把文件流中的字符输入到字符串流中
fs.close();
string str = ss.str(); // 获取流中的字符串
页面不大 载入到string中 如果是UTF8 还需要进行GBK到UTF8的转换
然后使用正则 摘出每个漫画索引信息 存入vector<string>
string strRegex = "<li class=\"subject-item\">.*?</li>";
vector<string> vstr;
regex regExpress(strRegex);
smatch ms;
try {
while (regex_search(strText, ms, regExpress))
{
for (string::size_type i = 0; i < ms.size(); ++i)
{
vstr.push_back(ms.str(i));
}
strText = ms.suffix().str();
}
}
catch (exception& e)
{
cerr << e.what() << endl;
return vstr;
}
然后在对每本书的信息进行分析 解析出 书本名 简介 评分等
由于这些信息都是有固定标签 用正则反而麻烦 所以使用的字符串查找
basic_string <char>::size_type keyWordStart = s.find("title=\"");
basic_string <char>::size_type keyWordEnd = s.find("\"", keyWordStart + sizeof("title=\"")-1);
if ((keyWordStart != string::npos) && (keyWordEnd != string::npos) && (keyWordEnd > keyWordStart))
{
string strKeyWord = s.substr(keyWordStart+ sizeof("title=\"") - 1, keyWordEnd - keyWordStart- sizeof("title=\"")+1);
cout << strKeyWord << endl;
}
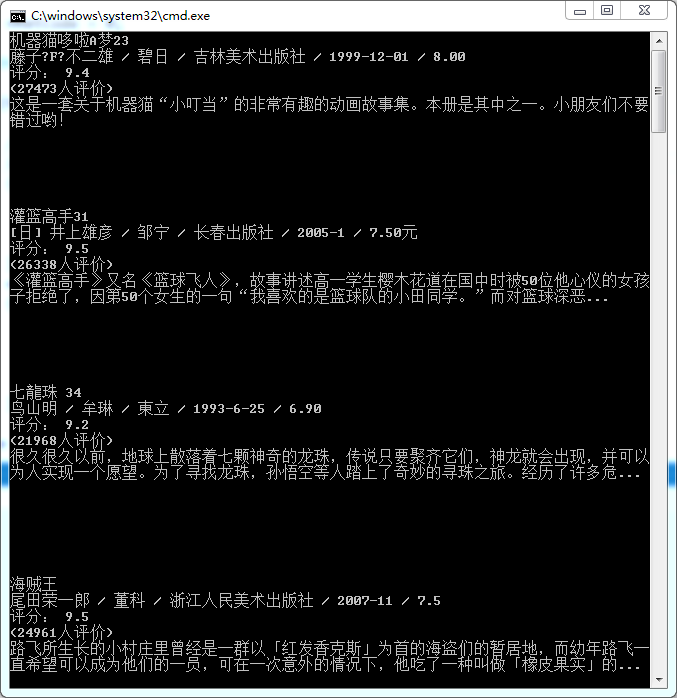
最后结果如图
欢迎转帖 请保持文本完整并注明出处
技术博客 http://www.cnblogs.com/itdef/
B站算法视频题解
https://space.bilibili.com/18508846
qq 151435887
gitee https://gitee.com/def/
欢迎c c++ 算法爱好者 windows驱动爱好者 服务器程序员沟通交流
如果觉得不错,欢迎点赞,你的鼓励就是我的动力




