

SQL Server 分组后取Top N
近日,工作中突遇一需求:将一数据表分组,而后取出每组内按一定规则排列的前N条数据。乍想来,这本是寻常查询,无甚难处。可提笔写来,终究是困住了笔者好一会儿。冥思苦想,遍查网络,不曾想这竟然是SQL界的一个经典话题。今日将我得来的若干方法列出,抛砖引玉,以期与众位探讨。
正文之前,对示例表结构加以说明。
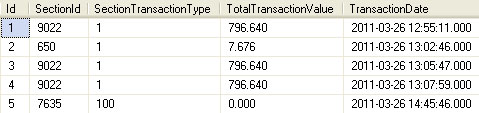
表SectionTransactionLog,用来记录各部门各项活动的日志表
SectionId,部门Id
SectionTransactionType,活动类型
TotalTransactionValue,活动花费
TransactionDate,活动时间
我们设定的场景为:选出每部门(SectionId)最近两次举行的活动。
笔者用来测试的SectionTransactionLog表中数据超3,000,000。
一、 嵌套子查询方式
1
1 SELECT * FROM SectionTransactionLog mLog 2 where 3 (select COUNT(*) from SectionTransactionLog subLog 4 where subLog.SectionId = mLog.SectionId and subLog.TransactionDate >= mLog.TransactionDate)<=2 5 order by SectionId, TransactionDate desc
运行时间:34秒
该方式原理较简单,只是在子查询中确定该条记录是否是其Section中新近发生的2条之一。
2
1 SELECT * FROM SectionTransactionLog mLog 2 where mLog.Id in 3 (select top 2 Id 4 from SectionTransactionLog subLog 5 where subLog.SectionId = mLog.SectionId 6 order by TransactionDate desc) 7 order by SectionId, TransactionDate desc
运行时间:1分25秒
在子查询中使用TransactionDate排序,取top 2。并应用in关键字确定记录是否符合该子查询。
二、 自联接方式
1 select mLog.* from SectionTransactionLog mLog 2 inner join 3 (SELECT rankLeft.Id, COUNT(*) as rankNum FROM SectionTransactionLog rankLeft 4 inner join SectionTransactionLog rankRight 5 on rankLeft.SectionId = rankRight.SectionId and rankLeft.TransactionDate <= rankRight.TransactionDate 6 group by rankLeft.Id 7 having COUNT(*) <= 2) subLog on mLog.Id = subLog.Id 8 order by mLog.SectionId, mLog.TransactionDate desc
运行时间:56秒
该实现方式较为巧妙,但较之之前方法也稍显复杂。其中,以SectionTransactionLog表自联接为基础而构造出的subLog部分为每一活动(以Id标识)计算出其在Section内部的排序rankNum(按时间TransactionDate)。
在自联接条件rankLeft.SectionId = rankRight.SectionId and rankLeft.TransactionDate <= rankRight.TransactionDate的筛选下,查询结果中对于某一活动(以Id标识)而言,与其联接的只有同其在一Section并晚于或与其同时发生活动(当然包括其自身)。下图为Id=1的活动自联接示意:

从上图中一目了然可以看出,基于此结果的count计算,便为Id=1活动在Section 9022中的排次rankNum。
而后having COUNT(*) <= 2选出排次在2以内的,再做一次联接select出所需信息。
三、 应用ROW_NUMBER()(SQL SERVER 2005及之后)
1 select * from 2 ( 3 select *, ROW_NUMBER() over(partition by SectionId order by TransactionDate desc) as rowNum 4 from SectionTransactionLog 5 ) ranked 6 where ranked.rowNum <= 2 7 order by ranked.SectionId, ranked.TransactionDate desc
运行时间:20秒
这是截至目前效率最高的实现方式。ROW_NUMBER() over(partition by SectionId order by TransactionDate desc)完成了分组、排序、取行号的整个过程。
效率思考
下面我们对上述的4种方法做一个效率上的统计。
| 方法 | 耗时(秒) | 排名 |
| 应用ROW_NUMBER() | 20 | 1 |
| 嵌套子查询方式1 | 34 | 2 |
| 自联接方式 | 56 | 3 |
| 嵌套子查询方式2 | 85 | 4 |
4种方法中,嵌套子查询2所用时最长,其效率损耗在什么地方了呢?难道果真是使用了in关键字的缘故?下图为其执行计划(execute plan):

从图中,我们可以看出优化器将in解析为了Left Semi Join, 其损耗极低。而该查询绝大部分性能消耗在子查询的order by处(Top N Sort)。果然,若删掉子查询中的order by TransactionDate desc子句(当然结果不正确),其耗时仅为8秒。
添加有效索引可提高该查询方法的性能。

