
[How to] 使用HBase协处理器---基本概念和regionObserver的简单实现
1. 简介
对于HBase的协处理器概念可由其官方博文了解:https://blogs.apache.org/hbase/entry/coprocessor_introduction
总体来说其包含两种协处理器:Observers和Endpoint。
其中Observers可以理解问传统数据库的触发器,当发生某一个特定操作的时候出发Observer。
- RegionObserver:提供基于表的region上的Get, Put, Delete, Scan等操作,比如可以在客户端进行get操作的时候定义RegionObserver来查询其时候具有get权限等。具体的方法(拦截点)有:
preOpen, postOpen: Called before and after the region is reported as online to the master. preFlush, postFlush: Called before and after the memstore is flushed into a new store file. preGet, postGet: Called before and after a client makes a Get request. preExists, postExists: Called before and after the client tests for existence using a Get. prePut and postPut: Called before and after the client stores a value. preDelete and postDelete: Called before and after the client deletes a value.
- WALObserver:提供基于WAL的写和刷新WAL文件的操作,一个regionserver上只有一个WAL的上下文。具体的方法(拦截点)有:
preWALWrite/postWALWrite: called before and after a WALEdit written to WAL.
- MasterObserver:提供基于诸如ddl的的操作检查,如create, delete, modify table等,同样的当客户端delete表的时候通过逻辑检查时候具有此权限场景等。其运行于Master进程中。具体的方法(拦截点)有:
preCreateTable/postCreateTable: Called before and after the region is reported as online to the master. preDeleteTable/postDeleteTable
以上对于Observer的逻辑以RegionObserver举例来说其时序图如下:
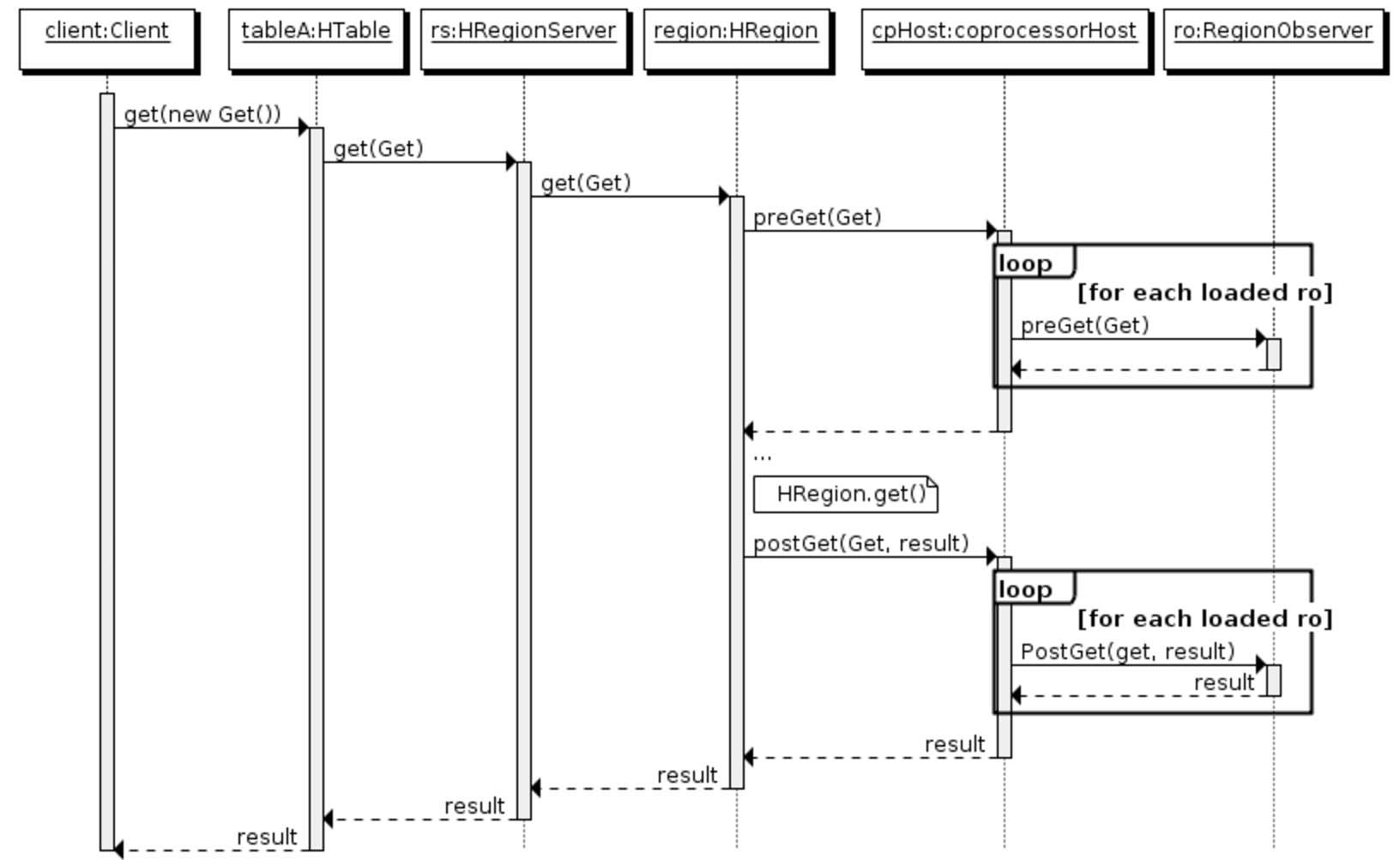
其中Endpoint可以理解为传统数据库的存储过程操作,比如可以进行某族某列值得加和。无Endpoint特性的情况下需要全局扫描表,通过Endpoint则可以在多台
分布有对应表的regionserver上同步加和,在江加和数返回给客户端进行全局加和操作,充分利用了集群资源,增加性能。Endpoint基本概念如下图: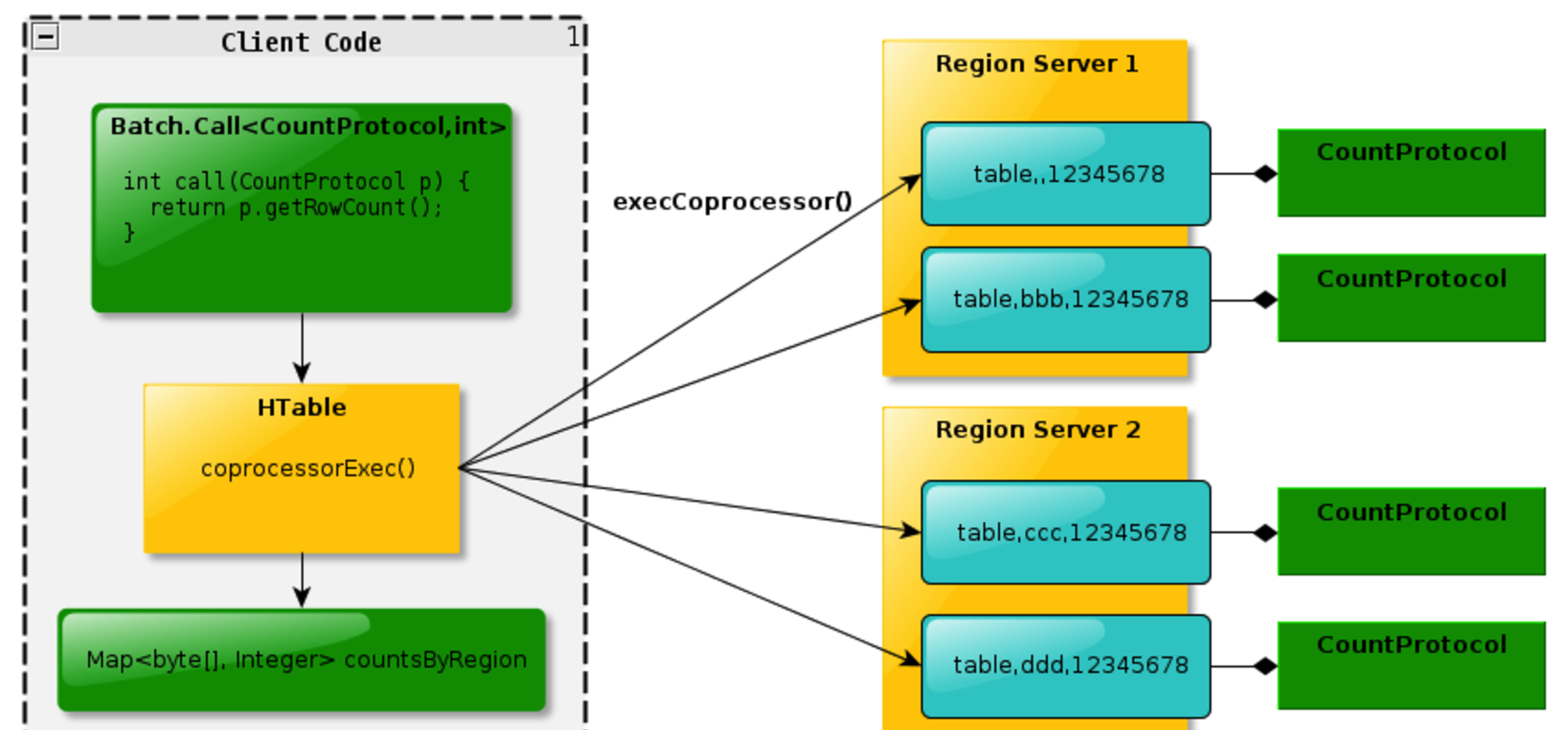
2. 两者代码实现细节的差异
在实现两种协处理器的时候稍有区别。无论哪种协处理器都需要运行于Server端的环境中。其中Endpoint还需要通过protocl来定义接口实现客户端代码进行rpc通信以此来进行数据的搜集归并。而Observer则不需要客户端代码,只在特定操作发生的时候出发服务端代码的实现。
3. Observer协处理器的实现
相对来说Observer的实现来的简单点,只需要实现服务端代码逻辑即可。通过实现一个RegionserverObserver来加深了解。
所要实现的功能:
假定某个表有A和B两个列--------------------------------便于后续描述我们称之为coprocessor_table 1. 当我们向A列插入数据的时候通过协处理器像B列也插入数据。 2.在读取数据的时候只允许客户端读取B列数据而不能读取A列数据。换句话说A列是只写 B列是只读的。(为了简单起见,用户在读取数据的时候需要制定列名) 3. A列值必须是整数,换句话说B列值也自然都是整数 4.当删除操作的时候不能指定删除B列 5.当删除A列的时候同时需要删除B列 6.对于其他列的删除不做检查
在上述功能点确定后,我们就要开始实现这两个功能。好在HBase API中有BaseRegionObserver,这个类已经帮助我们实现了大部分的默认实现,我们只要专注于业务上的方法重载即可。
代码框架:

public class 协处理器类名称 extends BaseRegionObserver { private static final Log LOG = LogFactory.getLog(协处理器类名称.class); private RegionCoprocessorEnvironment env = null;// 协处理器是运行于region中的,每一个region都会加载协处理器 // 这个方法会在regionserver打开region时候执行(还没有真正打开) @Override public void start(CoprocessorEnvironment e) throws IOException { env = (RegionCoprocessorEnvironment) e; } // 这个方法会在regionserver关闭region时候执行(还没有真正关闭) @Override public void stop(CoprocessorEnvironment e) throws IOException { // nothing to do here } /** * 出发点,比如可以重写prePut postPut等方法,这样就可以在数据插入前和插入后做逻辑控制了。 */ @Override
业务代码实现 :
根据上述需求和代码框架,具体逻辑实现如下。
- 在插入需要做检查所以重写了prePut方法
- 在删除前需要做检查所以重写了preDelete方法
public class MyRegionObserver extends BaseRegionObserver { private static final Log LOG = LogFactory.getLog(MyRegionObserver.class); private RegionCoprocessorEnvironment env = null; // 设定只有F族下的列才能被操作,且A列只写,B列只读。的语言 private static final String FAMAILLY_NAME = "F"; private static final String ONLY_PUT_COL = "A"; private static final String ONLY_READ_COL = "B"; // 协处理器是运行于region中的,每一个region都会加载协处理器 // 这个方法会在regionserver打开region时候执行(还没有真正打开) @Override public void start(CoprocessorEnvironment e) throws IOException { env = (RegionCoprocessorEnvironment) e; } // 这个方法会在regionserver关闭region时候执行(还没有真正关闭) @Override public void stop(CoprocessorEnvironment e) throws IOException { // nothing to do here } /** * 需求 1.不允许插入B列 2.只能插入A列 3.插入的数据必须为整数 4.插入A列的时候自动插入B列 */ @Override public void prePut(final ObserverContext<RegionCoprocessorEnvironment> e, final Put put, final WALEdit edit, final Durability durability) throws IOException { // 首先查看单个put中是否有对只读列有写操作 List<Cell> cells = put.get(Bytes.toBytes(FAMAILLY_NAME), Bytes.toBytes(ONLY_READ_COL)); if (cells != null && cells.size() != 0) { LOG.warn("User is not allowed to write read_only col."); throw new IOException("User is not allowed to write read_only col."); } // 检查A列 cells = put.get(Bytes.toBytes(FAMAILLY_NAME), Bytes.toBytes(ONLY_PUT_COL)); if (cells == null || cells.size() == 0) { // 当不存在对于A列的操作的时候则不做任何的处理,直接放行即可 LOG.info("No A col operation, just do it."); return; } // 当A列存在的情况下在进行值得检查,查看是否插入了整数 byte[] aValue = null; for (Cell cell : cells) { try { aValue = CellUtil.cloneValue(cell); LOG.warn("aValue = " + Bytes.toString(aValue)); Integer.valueOf(Bytes.toString(aValue)); } catch (Exception e1) { LOG.warn("Can not put un number value to A col."); throw new IOException("Can not put un number value to A col."); } } // 当一切都ok的时候再去构建B列的值,因为按照需求,插入A列的时候需要同时插入B列 LOG.info("B col also been put value!"); put.addColumn(Bytes.toBytes(FAMAILLY_NAME), Bytes.toBytes(ONLY_READ_COL), aValue); } /** * 需求 1.不能删除B列 2.只能删除A列 3.删除A列的时候需要一并删除B列 */ @Override public void preDelete( final ObserverContext<RegionCoprocessorEnvironment> e, final Delete delete, final WALEdit edit, final Durability durability) throws IOException { // 首先查看是否对于B列进行了指定删除 List<Cell> cells = delete.getFamilyCellMap().get( Bytes.toBytes(FAMAILLY_NAME)); if (cells == null || cells.size() == 0) { // 如果客户端没有针对于FAMAILLY_NAME列族的操作则不用关心,让其继续操作即可。 LOG.info("NO F famally operation ,just do it."); return; } // 开始检查F列族内的操作情况 byte[] qualifierName = null; boolean aDeleteFlg = false; for (Cell cell : cells) { qualifierName = CellUtil.cloneQualifier(cell); // 检查是否对B列进行了删除,这个是不允许的 if (Arrays.equals(qualifierName, Bytes.toBytes(ONLY_READ_COL))) { LOG.info("Can not delete read only B col."); throw new IOException("Can not delete read only B col."); } // 检查是否存在对于A队列的删除 if (Arrays.equals(qualifierName, Bytes.toBytes(ONLY_PUT_COL))) { LOG.info("there is A col in delete operation!"); aDeleteFlg = true; } } // 如果对于A列有删除,则需要对B列也要删除 if (aDeleteFlg) { LOG.info("B col also been deleted!"); delete.addColumn(Bytes.toBytes(FAMAILLY_NAME), Bytes.toBytes(ONLY_READ_COL)); } } }
4. Observer协处理器上传加载
完成实现后需要将协处理器类打包成jar文件,对于协处理器的加载通常有三种方法:
1.配置文件加载:即通过hbase-site.xml文件配置加载,一般这样的协处理器是系统级别的,全局的协处理器,如权限控制等检查。
2.shell加载:可以通过alter命令来对表进行scheme进行修改来加载协处理器。
3.通过API代码实现:即通过API的方式来加载协处理器。
上述加载方法中,1,3都需要将协处理器jar文件放到集群的hbase的classpath中。而2方法只需要将jar文件上传至集群环境的hdfs即可。
下面我们只介绍如何通过2方法进行加载。
步骤1:通过如下方法创建表
hbase(main):001:0> create 'coprocessor_table','F'
0 row(s) in 2.7570 seconds
=> Hbase::Table - coprocessor_table
步骤2:通过alter命令将协处理器加载到表中
alter 'coprocessor_table' , METHOD =>'table_att','coprocessor'=>'hdfs://ns1/testdata/Test-HBase-Observer.jar|cn.com.newbee.feng.MyRegionObserver|1001'
其中:'coprocessor'=>'jar文件在hdfs上的绝对路径|协处理器主类|优先级|协处理器参数
上述协处理器并没有参数,所以未给出参数,对于协处理器的优先级不在此做讨论。
步骤3:检查协处理器的加载
hbase(main):021:0> describe 'coprocessor_table' Table coprocessor_table is ENABLED coprocessor_table, {TABLE_ATTRIBUTES => {coprocessor$1 => 'hdfs://ns1/testdata/T est-HBase-Observer.jar|cn.com.newbee.feng.MyRegionObserver|1001'} COLUMN FAMILIES DESCRIPTION {NAME => 'F', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_S COPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'f alse', BLOCKCACHE => 'true'} 1 row(s) in 0.0300 seconds
可以看到协处理器被表成功加载,其实内部是将update所有此表的region去加载协处理器的。
5. Observer协处理器测试
经过上述代码完成和加载完成后我们进行简单的协处理器测试,由于Observer并不需要我们去定制客户端代码,所以我们可以直接通过shell命令环境来测试。
用例1: 正常插入A列
hbase(main):024:0> scan 'coprocessor_table' ROW COLUMN+CELL 0 row(s) in 0.0100 seconds hbase(main):025:0> put 'coprocessor_table','row1','F:A',123 0 row(s) in 0.0210 seconds hbase(main):026:0> scan 'coprocessor_table' ROW COLUMN+CELL row1 column=F:A, timestamp=1469838240645, value=123 row1 column=F:B, timestamp=1469838240645, value=123 1 row(s) in 0.0180 seconds
结果:B列也被插入,OK
用例2:插入A列,但是值不为整数
hbase(main):027:0> put 'coprocessor_table','row1','F:A','cc'
ERROR: Failed 1 action: IOException: 1 time,
结果:插入失败,服务端报如下错误,OK
2016-07-29 20:25:45,406 WARN [B.defaultRpcServer.handler=3,queue=0,port=60020] feng.MyRegionObserver: Can not put un number value to A col.
用例3:插入B列
hbase(main):028:0> put 'coprocessor_table','row1','F:B',123
ERROR: Failed 1 action: IOException: 1 time,
结果:插入失败,服务器报如下错误,OK
2016-07-29 20:27:13,342 WARN [B.defaultRpcServer.handler=20,queue=2,port=60020] feng.MyRegionObserver: User is not allowed to write read_only col.
用例4:删除B列
hbase(main):029:0> delete 'coprocessor_table','row1','F:B'
ERROR: java.io.IOException: Can not delete read only B col.
结果:删除失败,OK
用例4:删除A列
hbase(main):030:0> scan 'coprocessor_table' ROW COLUMN+CELL row1 column=F:A, timestamp=1469838240645, value=123 row1 column=F:B, timestamp=1469838240645, value=123 1 row(s) in 0.0230 seconds hbase(main):031:0> delete 'coprocessor_table','row1','F:A' 0 row(s) in 0.0060 seconds hbase(main):032:0> scan 'coprocessor_table' ROW COLUMN+CELL 0 row(s) in 0.0070 seconds
结果:A列和B列同时被删除了。
6. Observer协处理器总结
Observer协处理器也可以看作为服务端的拦截器,用户可以根据需求确定拦截点,在去重写这些拦截点对应的方法即可,整个过程中不需要重启集群,在不修改HBase内部代码的情况下对HBase扩展更加方便。如扩展权限,扩展索引等都非常有用。
参考:
HBase 协处理器编程详解第一部分:Server 端代码编写
代码下载:
https://github.com/xufeng79x/Test-HBase-Observer
posted on 2017-02-08 10:50 xf-xrh-xf 阅读(12945) 评论(2) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步